Online and Batch Learning Algorithms for Data with Missing Features
We introduce new online and batch algorithms that are robust to data with missing features, a situation that arises in many practical applications. In the online setup, we allow for the comparison hypothesis to change as a function of the subset of f…
Authors: Afshin Rostamizadeh, Alekh Agarwal, Peter Bartlett
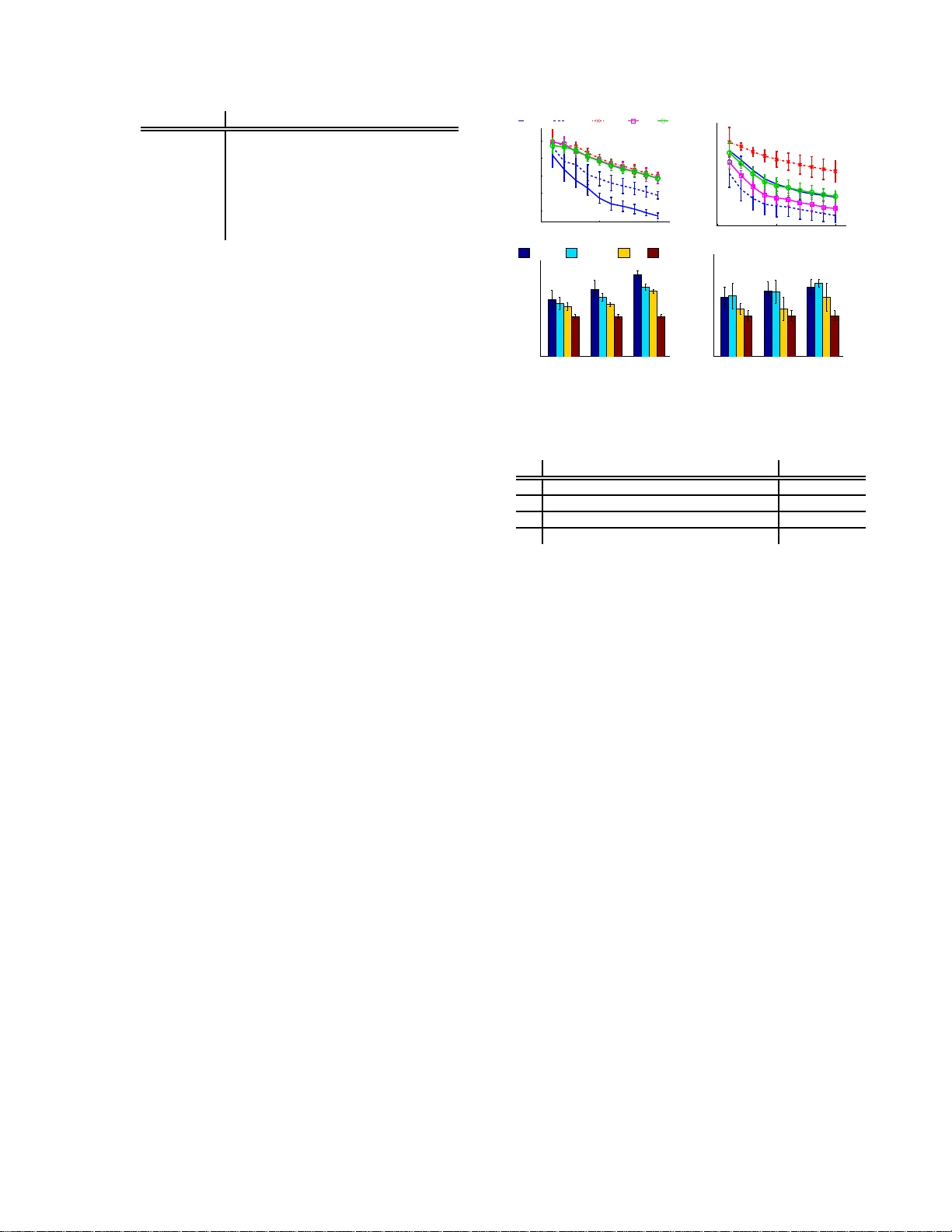
Learning with Missing F eatures Afshin Rostamizadeh Dept. of Electrical Engineering and Computer Science, UC Berkeley Alekh Agarw al Dept. of Electrical Engineering and Computer Science, UC Berkeley P eter Bartlett Mathematical Sciences, QUT and EECS and Statistics, UC Berkeley Abstract W e int ro duce new online and batch algo- rithms that are robust to data with missing features, a situation that arise s in many prac- tical applications. In the online setup, w e al- low for the compar ison hypothesis to change as a function of the subset of features that is observed on a ny g iven round, extending the standard setting where the comparison h y- po thesis is fixed throughout. In the batc h setup, we present a co nvex rela xation of a non-conv ex problem to join tly estimate an imputation function, us ed to fill in the v alues of missing features , along with the clas s ifica- tion hypo thes is . W e pr ov e regre t bounds in the online setting and Radema cher complex- it y bo unds for the batch i.i.d. setting. The al- gorithms a re tested on s everal UCI datasets, showing s upe r ior p erfor ma nce ov er ba s eline imputation metho ds. 1 In tro duction Standard learning algor ithms assume that ea ch train- ing example is f u l ly observe d and do esn’t suffer a ny corruption. How ever, in many real-life scenario s, tra in- ing a nd test data often undergo some form of cor- ruption. W e c onsider settings where all the fea tures might not be obs erved in every ex a mple, a llowing for bo th adversarial and s to chastic feature deletio n mo d- els. Such situatio ns arise, for example, in medical diagnosis—pr edictions ar e often desired using only a partial arr ay o f medical meas urements due to time o r cost constr aints. Survey data a re often inco mplete due to par tia l non-resp ons e of participants. Vision task s routinely need to deal with pa rtially co rrupted or o c- cluded images. Data colle cted through m ultiple sen- sors, such as multiple ca mer as, is often sub ject to the sudden failur e of a subse t of the sens o rs. In this w or k, we desig n and analyze learning algo- rithms that addr ess these exa mples o f learning with missing features . The firs t setting we co ns ider is on- line lear ning where b oth examples and missing features are c hos e n in a n ar bitrary , p ossibly adversarial, fash- ion. W e define a nov el notion o f regre t suitable to the setting a nd pr ovide an algorithm which has a prov- ably bounded regret on the o rder of O ( √ T ), where T is the num b e r o f examples. The second scenario is batch learning, whe r e examples and missing features are drawn accor ding to a fixed and unknown distribu- tion. W e design a learning alg orithm whic h is guaran- teed to glo bally optimize an intuitiv e o b jective func- tion and which also exhibits a g e neralization erro r on the o rder of O ( p d/T ), where d is the data dimension. Both alg orithms a re also explored empir ically a cross several publicly av ailable datas ets sub ject to v arious artificial a nd natur a l types of feature corruption. W e find very encour aging r e sults, indicating the efficacy of the sugg ested algorithms and their sup erio r pe rfor- mance ov er ba seline metho ds. Learning with missing or corrupted featur es ha s a long history in statistics [14, 1 0], and has r ecieved recent attent io n in machine lear ning [9, 15, 5 , 7]. Imputa- tion metho ds (see [14, 1 5, 10]) fill in missing v alues, generally indep endent of any learning alg orithm, af- ter which standar d algo rithms ca n be a pplied to the data. Better p erformance might b e exp ected, though, by lear ning the imput a tion a nd prediction functions simult a ne o usly . Prev io us w ork s [15] address this issue using EM, but can get stuck in lo cal optima and do not hav e stro ng theo r etical guarantees. O ur w or k als o is differen t from settings where features a re missing only at test time [9, 1 1], settings that give access to noisy versions of all the features [6] or settings where observed features are pick ed by the alg orithm [5]. Section 2 intro duce s b oth the genera l online a nd batch settings. Sections 3 and 4 detail the alg orithms and theoretical r esults within the online and batch settings resp. Empirical results a re pre s ented in Section 5. 2 The Setting In our setting it will b e useful to denote a training instance x t ∈ R d and pr e dic tio n y t , as well as a cor- ruption vector z t ∈ { 0 , 1 } d , where [ z t ] i = 0 if feature i is not obser ved, 1 if feature i is observed. W e will discuss as s pe c ific examples b oth class ification problems where y t ∈ {− 1 , 1 } and re g ressio n problems where y t ∈ R . The learning algo rithm is given the corruption v ector z t as w ell as the corrupted instance, x ′ t = x t ◦ z t , where ◦ deno tes the compo nent -w is e pro duct b etw een t wo v ectors . Note that the tr aining algorithm is ne ver given acce ss to x t , how ever it is given z t , and s o has knowledge of exa ctly which co o rdinates have b e e n cor - rupted. The following subsections explain the online and batch se ttings resp ectively , as well as the t yp e of hypotheses that ar e considered in each. 2.1 Online learning with missing features In this setting, at ea ch time-step t the lea r ning algo- rithm is pr e sented with an arbitrarily (p ossibly ad- versarially) chosen instance ( x ′ t , z t ) a nd is ex pe c ted to predict y t . After predictio n, the lab el is then revealed to the learner which then can up date its hypothesis. A natura l question to ask is what happ ens if we simply ignore the distinction b etw een x ′ t and x t and just run an online learning a lgorithm on this corr upted data. Indeed, doing so would give a small b ound on re g ret: R ( T , ℓ ) = T X t =1 ℓ ( h w t , x ′ t i , y t ) − inf w ∈W T X t =1 ℓ ( h w , x ′ t i , y t ) , (1) with resp ect to a conv ex los s function ℓ and for any conv ex compact subset W ⊆ R d . How ever, any fixed weigh t v ector w in the second ter m might hav e a very large loss, mak ing the regret guar antee useless—b oth the learner and the comparator ha ve a large loss mak- ing the difference s mall. F or instance, assume one feature p erfectly predicts the la be l, while ano ther o ne only predicts the label with 80% accuracy , and ℓ is the quadratic lo ss. It is easy to see that there is no fixed w that w ill p erfo r m well on b oth examples where the first feature is observed a nd examples wher e the fir st feature is missing but the second one is obse r ved. T o address the above concer ns, w e consider us ing a linear c orruption-dep endent hyp othesis which is p er- mitted to c hange as a function of the observed cor- ruption z t . Sp ecifica lly , given the corr upted instance and corr uption vector, the predicto r uses a funct io n w t ( · ) : { 0 , 1 } d → R d to choo se a weigh t vector, a nd makes the prediction b y t = h w t ( z t ) , x ′ t i . In order to provide theoretica l g ua rantees, we will bound the fol- lowing notion of re gret, R z ( T , ℓ ) = T X t =1 ℓ ( h w t , x ′ t i , y t ) − inf w ∈W T X t =1 ℓ ( h w ( z t ) , x ′ t i , y t ) , (2) where it is implicit that w t also dep ends on z t and W now co ns ists of corruptio n-dep endent hypotheses. Similar definitions of regret hav e b een looked at in the setting learning with side info r mation [8, 12], but o ur sp ecial case admits strong er results in terms of b oth upper and lower bo unds . In the most genera l case, we may consider W a s the class of a ll functions which map { 0 , 1 } d → R d , how ever w e show this ca n lead to an intractable learning problem. This motiv ates the study of in tere sting subsets of this mo s t g eneral function clas s. This is the main fo cus of Section 3. 2.2 Batc h learning with missi ng features In the setup of batch lea rning with i.i.d. data, examples ( x t , z t , y t ) ar e drawn acco rding to a fixed but unknown distribution and the goal is to choo se a hypo thesis that minimizes the exp ected er ror, with resp ect to an a p- propriate los s function ℓ : E x t , z t ,y t [ ℓ ( h ( x t , z t ) , y t )]. The hypotheses h we consider in this s cenario will be inspired by imputatio n-based metho ds prev alent in statistics literature used to address the problem of missing feature s [1 4]. An imputation mapping is a function used to fill in unobserved fea tures using the observed features , a fter which the c omplete d examples can be used for pr e dic tio n. In particular, if we cons ider an imputation function φ : R d × { 0 , 1 } d → R d , which is mea nt to fill miss ing feature v alues, and a linear pr e- dictor w ∈ R d , we can parameter ize a hypo thesis with these tw o function h φ , w ( x ′ t , z t ) = h w , φ ( x ′ t , z t ) i . It is clear that the m ultiplicative interaction b etw een w and φ will make mo st natural for m ula tio ns non- conv ex, and we elab or ate more on this in Section 4. In the i.i.d. setting, the natur al quantit y of interest is the g eneralizatio n error of our learned hypo thesis. W e provide a Rademacher complexity b ound o n the class of w , φ pair s we use, ther eby s howing that any hypo th- esis with a small empirical error will also ha ve a small exp ected loss. The sp ecific clas s of hypo theses and details of the bound ar e pres ented in Sec tio n 4. F ur- thermore, the rea son as to wh y an imputation-bas ed hypothesis clas s is not analyzed in the mo re gener al ad- versarial setting will also b e ex plained in that section. 3 Online Corr uption-Based Algorithm In this section, w e consider the class of c orruption- dep endent hypotheses defined in Section 2 .1. Recall the definition of regr et (2), which we wis h to control in this fr a mework, and o f the co mparator class o f func- tions W ⊆ { 0 , 1 } d → R d . It is clear that the function class W is muc h r icher than the comparato r class in the corruption-fr ee scenario, where the b es t linea r pre- dictor is fixed for all ro unds. It is natural to ask if it is even possible to prov e a non-tr ivial reg ret b ound over this richer comparator class W . In fac t, the fir st r esult of our pa pe r pr ovides a low er bound on the minimax regret when the compara to r is allowed to pick arbi- trary mappings, i.e. the set W contains all mappings . The r esult is stated in terms of the minimax reg ret under the loss function ℓ under the usual (cor r uption- free) definition (1): R ∗ ( T , ℓ ) = inf w 1 ∈W sup ( x 1 , z 1 ,y 1 ) · · · inf w T ∈W sup ( x T , z T ,y T ) R ( T , ℓ ) Prop ositi on 1 If W = { 0 , 1 } d → R d the minimax value of the c orruption dep endent re gr et for any loss function ℓ is lower b ounde d as inf w 1 ∈W sup ( x 1 , z 1 ,y 1 ) · · · inf w T ∈W sup ( x T , z T ,y T ) R z ( T , ℓ ) = Ω 2 d/ 2 R ∗ T 2 d/ 2 , ℓ . This pr op osition (the pr o of of whic h app ea rs in the app endix [17]) shows that the minimax regret is lo wer bo unded b y a term that is ex po nential in the di- mensionality o f the learning pro blem. F or mos t non- degenerate conv ex and Lipschitz losses, R ∗ ( T , ℓ ) = Ω( √ T ) without further ass umptions (see e.g. [1]) which yields a Ω(2 d/ 4 √ T ) low er bo und. The bo und can b e further strengthened to Ω(2 d/ 2 √ T ) for lin- ear lo sses which is unimprov a ble since it is achieved by solving the classificatio n problem corres p o nding to each pattern indep endently . Thu s, it will b e difficult to achiev e a low regre t against arbitrar y ma ps from { 0 , 1 } d to R d . In the follow- ing section we co ns ider a res tricted function clas s and show that a mirror -descent alg orithm can achiev e re- gret poly no mial in d and sub-linear in T , implying tha t the average r egret is v anishing. 3.1 Linear Corruption-Dep endent Hyp othese s Here w e analyze a co rruption-dep endent hypothesis class that is parametrized by a matrix A ∈ R d × k , where k may be a function of d . In the simplest case of k = d , the parametriza tion lo oks fo r weigh ts w ( z t ) that dep end linearly on the co rruption vector z t . Defining w A ( z t ) = Az t achiev es this, and intu- itively this allows us to ca pture how the presence or absence of one feature affects the weigh t o f ano ther feature. This will b e clarified further in the ex amples. In g eneral, the matrix A will be d × k , where k will be determined by a function ψ ( z t ) ∈ { 0 , 1 } k that maps z t to a po ssibly higher dimension space. Given, a fixed ψ , the ex plicit par ameterization in ter ms of A is, w A , ψ ( z t ) = A ψ ( z t ) . (3) In what fo llows, w e drop the s ubscript from w A , ψ in order to simplify notation. Ess ent ia lly this a llows us to in tro duce non-linearities as a function of the corr up- tion vector, but the no n-linear transform is known and fixed througho ut the learning pro cess . Before analyz- ing this setting, w e give a few exa mples a nd intuit io n as to why such a pa rametrizatio n is useful. In ea ch example, w e will show how ther e exists a choice of a matrix A that captures the sp ecific pro blem’s assump- tions. This implies that the fixed compar ator can use this choice in hindsight, and by having a low reg ret, our algor ithm would implicitly lear n a h yp othes is close to this reaso nable choice of A . 3.1.1 Corruption-free sp ecial case W e star t by noting that in the case of no corruption (i.e. ∀ t, z t = 1 ) a standard linear h yp o thes is mo del ca n be cast within the matrix based fr amework b y defining ψ ( z t ) = 1 and lear ning A ∈ R d × 1 . 3.1.2 Ranking-based parameterization One natural metho d for class ifica tion is to order the features by their predictive p ow er, and to weight fea - tures propo rtionally to their ranking (in terms of ab- solute v alue; that is, the sign of w eig ht dep ends on whether the cor relation with the la b el is p os itive or negative). In the cor rupted features setting, this nat- urally corr esp onds to ta king the av ailable features at any ro und and putting mor e weigh t on the most pre- dictive obser ved fea tur es. This is particularly impo r- tant while using marg in-based losses such as the hinge loss, wher e we wan t the prediction to hav e the right sign and b e large eno ugh in magnitude. Our parametriz a tion allows s uch a strategy when us- ing a simple function ψ ( z t ) = z t . Without loss of generality , assume that the features a re arr anged in de- creasing order o f discriminative pow er (we can always rearr ange r ows and columns of A if they’re not). W e also assume p os itive co r relations o f a ll features with the lab el; a more elab o rate construction works for A when they’re not. In this case, consider the para meter matrix and the induced clas s ification weight s [ A ] i,j = 1 , j = i − 1 d , j < i 0 , j > i , [ w ( z t )] i = [ z t ] i 1 − X j 0, it is deleted with pro bability β , which again can b e tuned to induce mor e or les s missing da ta . T a ble 1 shows the av era ge fr action o f features r e ma ining after b eing sub ject to each t yp e of corruption; that is, the total sum of feature s av ailable ov er all instances div ided by the total n umber o f fea- tures that would b e av ailable in th e corruption-free case. The av erage error-ra te along with one standard de- viation is rep or ted ov er 5 trials ea ch with a random fold o f 10 00 tra ining p oints 1 . In the batch setting the remainder of the dataset in each tria l is used as the test set. When applica ble, ea ch tria l is also sub- jected to a different random cor ruption pattern. All scores are r ep orted with re sp ect to the b est p erform- ing par ameters, λ , C , η and γ , tuned a cross the v alues { 2 − 12 , 2 − 11 , . . . , 2 10 } . 1 With the except ion of optdigits in the online setting where 3000 p oin ts are used.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment