Generalized Louvain Method for Community Detection in Large Networks
In this paper we present a novel strategy to discover the community structure of (possibly, large) networks. This approach is based on the well-know concept of network modularity optimization. To do so, our algorithm exploits a novel measure of edge centrality, based on the k-paths. This technique allows to efficiently compute a edge ranking in large networks in near linear time. Once the centrality ranking is calculated, the algorithm computes the pairwise proximity between nodes of the network. Finally, it discovers the community structure adopting a strategy inspired by the well-known state-of-the-art Louvain method (henceforth, LM), efficiently maximizing the network modularity. The experiments we carried out show that our algorithm outperforms other techniques and slightly improves results of the original LM, providing reliable results. Another advantage is that its adoption is naturally extended even to unweighted networks, differently with respect to the LM.
💡 Research Summary
The paper introduces a novel community detection algorithm called Fast κ‑path Community Detection (FKCD), which generalizes the well‑known Louvain method (LM) by incorporating a global edge‑centrality measure based on κ‑paths. The authors first review the community detection landscape, distinguishing between global‑feature approaches (e.g., spectral clustering, modularity maximization) and local‑information approaches (e.g., original LM). While LM is fast and works well on large weighted graphs, it does not exploit any global information about edge importance, especially in unweighted networks.
To address this gap, the authors define κ‑path edge centrality Lκ(e) as the sum over all source nodes of the proportion of random simple paths of length at most κ that traverse edge e. This metric captures how frequently an edge participates in information propagation across the whole network. Computing Lκ(e) exactly would be prohibitive, so the paper adopts the Weighted Edge Random Walk κ‑Path (WERW‑Kpath) algorithm. WERW‑Kpath proceeds in two stages: (1) assign each node a selection probability proportional to its local effective density δ(v) = (|I(v)|+|O(v)|)/|E|, and give each edge an initial weight ω(e)=1/|E|; (2) perform ρ = |E|‑1 random walk simulations, each starting from a node chosen according to δ(v). During a walk, an untraversed outgoing edge is selected with probability proportional to its current weight, the edge weight is increased by 1/|E|, and the walk continues until either κ steps have been taken or no untraversed outgoing edges remain. This process avoids cycles and limits path length, yielding a total time complexity of O(κ|E|) and linear memory usage.
After the centrality scores are obtained, edges are re‑weighted by Lκ(e). The authors then define the distance between two adjacent nodes as the inverse of the weighted edge, and compute the proximity (inverse distance) for all connected pairs. With these proximities, the standard two‑phase Louvain optimization is applied: (i) each node is moved to the neighboring community that yields the largest increase in modularity ΔQ (the formula is the same as in LM but now uses the new edge weights); (ii) the resulting communities are collapsed into super‑nodes, forming a new, smaller graph, and the process repeats until modularity improvement stops.
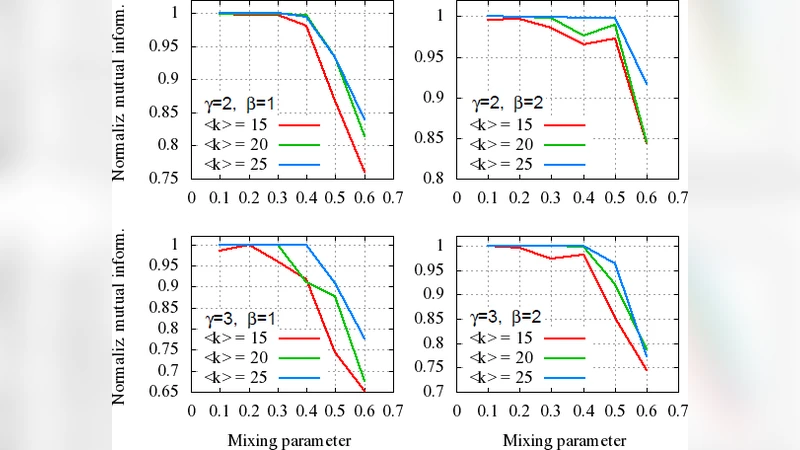
The experimental evaluation covers several real‑world large networks (social media graphs, collaboration networks) and synthetic benchmarks. FKCD is compared against the original Louvain method, Girvan‑Newman, Clauset‑Newman‑Moore, and Extremal Optimization. Results show that FKCD consistently achieves higher modularity—typically 1–2 % above LM—while maintaining near‑linear runtime. Notably, FKCD works equally well on unweighted graphs, where LM would otherwise treat all edges equally and miss the global propagation information captured by κ‑path centrality.
The paper concludes that integrating a near‑linear global edge‑centrality measure with the efficient local moves of LM yields a method that is both scalable and slightly more accurate. Limitations include sensitivity to the choice of κ (small κ may miss long‑range influence, large κ increases computation), stochastic variability due to random walks, and the need to store per‑edge flags and weights, which could become memory‑intensive for extremely large graphs. Future work is suggested on adaptive κ selection, parallelizing the random‑walk phase, extending the centrality to directed or weighted paths, and applying the framework to dynamic networks. Overall, FKCD represents a meaningful step toward bridging global and local information in community detection for large‑scale networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment