Memory Based Machine Intelligence Techniques in VLSI hardware
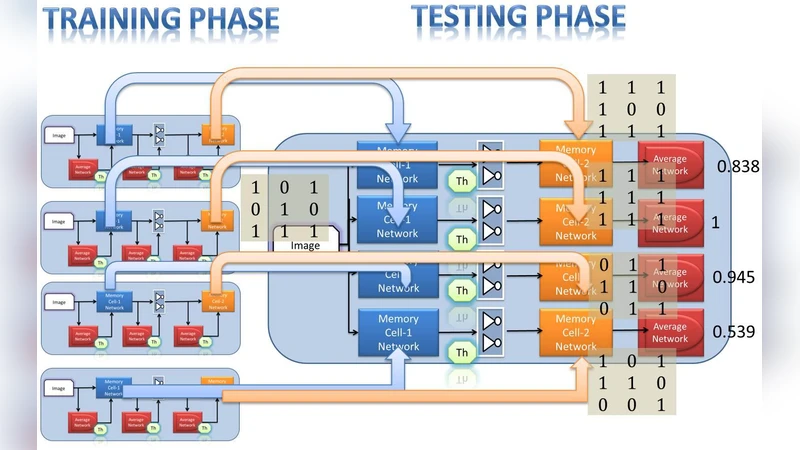
We briefly introduce the memory based approaches to emulate machine intelligence in VLSI hardware, describing the challenges and advantages. Implementation of artificial intelligence techniques in VLSI hardware is a practical and difficult problem. Deep architectures, hierarchical temporal memories and memory networks are some of the contemporary approaches in this area of research. The techniques attempt to emulate low level intelligence tasks and aim at providing scalable solutions to high level intelligence problems such as sparse coding and contextual processing.
💡 Research Summary
The paper provides a comprehensive overview of contemporary efforts to embed memory‑centric artificial‑intelligence (AI) techniques within very‑large‑scale integration (VLSI) hardware. It begins by outlining the fundamental challenges that arise when traditional digital neural networks are mapped onto silicon: high power consumption, large silicon area, limited memory bandwidth, and the prohibitive cost of moving data between separate compute and storage units. To address these issues, the authors argue that the memory fabric itself must become the computational substrate, thereby collapsing the von‑Neumann bottleneck and enabling truly scalable AI accelerators.
Three principal families of memory‑based approaches are examined in depth. First, deep architectures are discussed in the context of emerging non‑volatile memory (NVM) technologies such as resistive RAM (RRAM), phase‑change memory (PCM), and magnetoresistive RAM (MRAM). By storing synaptic weights directly in NVM cells and performing in‑situ multiply‑accumulate (MAC) operations, designers can dramatically reduce data movement, lower latency, and achieve orders‑of‑magnitude improvements in energy efficiency. The paper also reviews weight‑sharing, pruning, and quantization techniques that further shrink the silicon footprint of multi‑layer networks.
Second, the Hierarchical Temporal Memory (HTM) model is presented as a biologically inspired alternative that emphasizes temporal sequences and sparse representations. The authors describe how HTM’s fundamental elements—cells, segments, and predictive states—can be mapped onto individual memory cells, using the intrinsic programmability of NVM to encode synaptic permanence. Because the state of each cell is retained after power‑off, HTM implementations naturally support continual learning and on‑chip memory of long‑term context, a capability that is difficult to achieve with conventional volatile SRAM‑based designs.
Third, the concept of memory networks and processing‑in‑memory (PIM) architectures is explored. Rather than executing explicit MAC operations, these systems rely on state propagation and content‑addressable matching within the memory array itself. The authors highlight sparse coding schemes that exploit non‑uniform memory mapping to maximize storage utilization, and they discuss dynamic re‑wiring mechanisms that enable context‑dependent connectivity without costly routing. To mitigate error propagation in large arrays, the paper proposes on‑chip error‑correction codes, adaptive re‑training loops, and temperature‑aware calibration circuits.
Across all three approaches, the paper identifies a set of common hardware challenges: variability and drift of NVM cells, sensitivity to temperature and supply voltage, and the need for robust fault‑tolerance mechanisms. It also points out the current lack of mature design‑automation tools capable of exploring the massive design space that combines algorithmic parameters with circuit‑level constraints. The authors suggest that high‑level synthesis (HLS) frameworks augmented with machine‑learning‑driven optimization could shorten development cycles and improve design quality.
In the concluding section, the authors outline future research directions. They advocate for three‑dimensional (3D) stacking and multi‑chip‑module (MCM) integration to achieve the density required for large‑scale memory‑based AI systems. Event‑driven, asynchronous logic is recommended to further reduce dynamic power, especially in applications that process sparse, temporally irregular data streams. Finally, the paper envisions hardware that can emulate the plasticity of biological synapses, allowing on‑chip structures to reconfigure themselves in response to experience, thereby moving beyond static weight matrices toward truly adaptive intelligent hardware.
Overall, the paper argues that memory‑centric AI offers a promising pathway to reconcile the competing demands of energy efficiency, scalability, and continual learning in VLSI implementations. By addressing reliability concerns and advancing automated design methodologies, these techniques could become the foundation of next‑generation intelligent silicon.