BIN@ERN: Binary-Ternary Compressing Data Coding
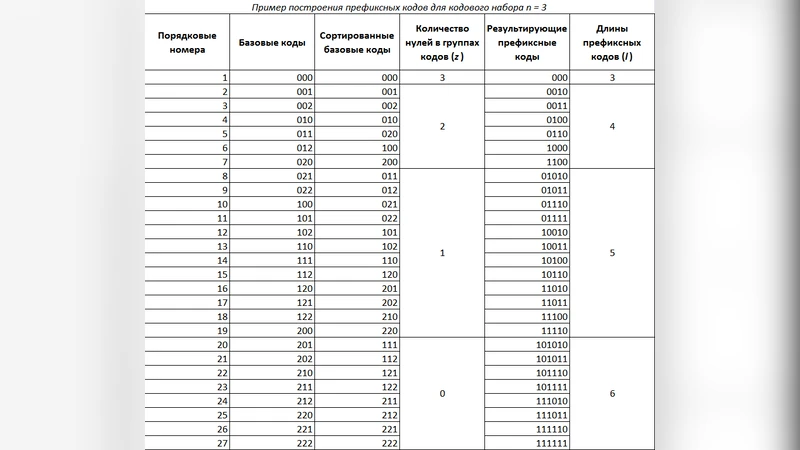
This paper describes a new method of data encoding which may be used in various modern digital, computer and telecommunication systems and devices. The method permits the compression of data for storage or transmission, allowing the exact original data to be reconstructed without any loss of content. The method is characterized by the simplicity of implementation, as well as high speed and compression ratio. The method is based on a unique scheme of binary-ternary prefix-free encoding of characters of the original data. This scheme does not require the transmission of the code tables from encoder to decoder; allows for the linear presentation of the code lists; permits the usage of computable indexes of the prefix codes in a linear list for decoding; makes it possible to estimate the compression ratio prior to encoding; makes the usage of multiplication and division operations, as well as operations with the floating point unnecessary; proves to be effective for static as well as adaptive coding; applicable to character sets of any size; allows for repeated compression to improve the ratio.
💡 Research Summary
The paper introduces BIN@ERN (Binary‑Ternary Compressing Data Coding), a novel loss‑less data compression scheme that blends binary (0, 1) and ternary (2) symbols into a single prefix‑free code space. Unlike traditional binary‑only variable‑length codings such as Huffman, BIN@ERN assigns each source symbol a code composed of a sequence of 0, 1, and occasional 2 symbols; the presence of a 2 acts as a “mode switch” after which the following bits are interpreted as ordinary binary digits. This hybrid representation allows finer granularity in code‑length allocation, especially when symbol probabilities differ dramatically.
A central claim of the work is that no explicit code table needs to be transmitted. The authors define a deterministic, linear “code list” that enumerates all possible binary‑ternary codewords in a fixed order based on the size of the source alphabet (N). For any symbol with rank r in the ordered frequency list, the algorithm computes its code length and the exact bit pattern using only integer arithmetic (shifts, adds, and subtracts). Consequently, both encoder and decoder can reconstruct the identical code list on‑the‑fly, eliminating any side‑channel overhead. This property is particularly attractive for bandwidth‑constrained or low‑power environments where every transmitted bit matters.
Implementation simplicity is another highlighted advantage. The method deliberately avoids multiplication, division, and floating‑point operations; all required calculations are performed with integer logic. This makes the algorithm amenable to hardware acceleration, micro‑controller implementation, and real‑time processing where deterministic latency is essential.
The authors discuss two operational modes. In the static mode, the entire source is scanned once, symbol frequencies are collected, and a single code list is generated for the whole file. In the adaptive mode, the input stream is partitioned into blocks; after each block the frequency estimate is updated, a new code list is derived, and encoding proceeds with the updated list. Because the list can be regenerated from the updated frequencies alone, the only additional information that may need to be exchanged is a minimal “sync” token indicating that the decoder should recompute the list, not the full table itself.
A further contribution is the concept of “repeated compression.” After an initial BIN@ERN pass, the resulting bitstream can be fed back into the same encoder for a second (or third) pass, potentially extracting residual redundancy. The authors provide a mathematical argument that the compression ratio converges, i.e., each additional pass yields diminishing but non‑negative gains. In practice, however, the marginal improvement is expected to drop sharply after the first or second iteration, a phenomenon the paper acknowledges but does not quantify experimentally.
Strengths of the proposal include:
- Zero‑overhead code‑table transmission, which reduces protocol complexity.
- Linear‑time decoding via direct index lookup, enabling high throughput.
- Absence of floating‑point arithmetic, facilitating deterministic, low‑power hardware designs.
- Applicability to both static and adaptive scenarios, and to alphabets of arbitrary size (including Unicode).
- The possibility of multi‑pass compression for extra gain.
Nevertheless, the paper leaves several critical questions unanswered. First, the computational cost of generating the binary‑ternary code list for large alphabets is not analyzed; enumerating all mixed‑radix codewords could become prohibitive when N reaches thousands or millions. Second, there is a lack of empirical comparison with established compressors (Huffman, arithmetic coding, LZ‑based schemes). Without benchmark data on compression ratio, speed, and memory footprint, it is difficult to assess whether BIN@ERN offers a practical advantage. Third, the adaptive mode’s synchronization mechanism is only sketched; in multi‑user or packet‑lossy networks, ensuring that encoder and decoder stay in lockstep may still require explicit signaling. Fourth, the repeated‑compression idea is theoretically sound but practically limited; the paper does not provide guidance on when additional passes are worthwhile or how to detect convergence automatically. Finally, while the claim of “no code‑table transmission” holds for a single point‑to‑point link, distributed systems that share a common codebook across many nodes would still need a method to disseminate the initial ordering or to agree on the ranking policy.
In conclusion, BIN@ERN presents an intriguing hybrid radix coding framework that promises simplicity, speed, and low overhead. Its theoretical contributions—particularly the deterministic index‑based decoding and the avoidance of floating‑point math—are valuable for specialized domains such as embedded telemetry, real‑time streaming, and resource‑constrained IoT devices. However, to move from concept to a widely adoptable technology, further work is required: rigorous complexity analysis, comprehensive experimental evaluation against state‑of‑the‑art compressors, and robust protocols for adaptive synchronization in noisy or multi‑endpoint environments. If these gaps are addressed, BIN@ERN could become a compelling alternative in the toolbox of lossless data compression techniques.