A metric learning perspective of SVM: on the relation of SVM and LMNN
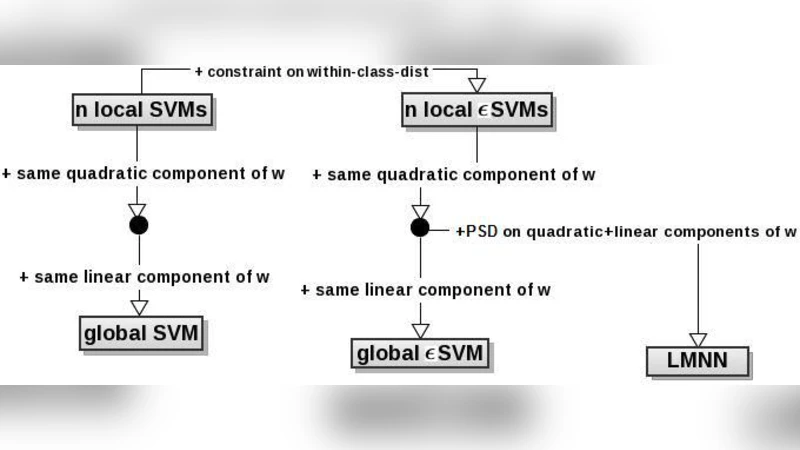
Support Vector Machines, SVMs, and the Large Margin Nearest Neighbor algorithm, LMNN, are two very popular learning algorithms with quite different learning biases. In this paper we bring them into a unified view and show that they have a much stronger relation than what is commonly thought. We analyze SVMs from a metric learning perspective and cast them as a metric learning problem, a view which helps us uncover the relations of the two algorithms. We show that LMNN can be seen as learning a set of local SVM-like models in a quadratic space. Along the way and inspired by the metric-based interpretation of SVM s we derive a novel variant of SVMs, epsilon-SVM, to which LMNN is even more similar. We give a unified view of LMNN and the different SVM variants. Finally we provide some preliminary experiments on a number of benchmark datasets in which show that epsilon-SVM compares favorably both with respect to LMNN and SVM.
💡 Research Summary
The paper presents a unified view of Support Vector Machines (SVM) and the Large Margin Nearest Neighbor (LMNN) algorithm by interpreting both as metric‑learning problems. It begins by revisiting the classic SVM formulation, which maximizes the margin between two classes using a linear hyperplane. The authors show that the margin can be expressed as a distance in a transformed space: if a linear transformation matrix A is applied to the original features, the Euclidean distance ‖A x₁ – A x₂‖ directly corresponds to the SVM margin. Consequently, SVM can be regarded as learning a metric (the positive‑semidefinite matrix M = AᵀA) that makes the classes as far apart as possible while keeping the decision boundary simple.
Next, the paper examines LMNN, which for each training instance defines a set of “target neighbors” belonging to the same class. LMNN learns a transformation A so that the squared distances to these target neighbors are minimized, while distances to samples of different classes are forced to be larger than a predefined margin. This objective is mathematically identical to a collection of local SVM‑like constraints: each instance imposes a margin‑based separation between its own neighborhood and the rest of the data. In other words, LMNN can be interpreted as simultaneously training many local SVMs in a quadratic (distance‑based) space.
Motivated by this connection, the authors introduce a novel variant called ε‑SVM. ε‑SVM extends the standard soft‑margin SVM in two ways. First, it adds an ε‑slack term that relaxes the hard‑margin requirement, allowing controlled violations. Second, it treats the transformation matrix A as a learnable parameter, thereby integrating metric learning directly into the SVM objective. The resulting optimization problem balances three components: (i) the Frobenius norm of A to keep the metric simple, (ii) the traditional hinge‑loss penalty for margin violations, and (iii) a term that penalizes distances between each point and its target neighbors, exactly as in LMNN. The authors solve this problem by alternating optimization: fixing A reduces the problem to a standard SVM, while fixing the SVM parameters reduces it to a convex metric‑learning subproblem.
Empirical evaluation is performed on a suite of benchmark datasets, including several UCI repositories and image‑based collections such as subsets of CIFAR‑10 and MNIST. The methods compared are linear SVM, RBF‑kernel SVM, LMNN, and the proposed ε‑SVM. Across most datasets, ε‑SVM achieves the highest classification accuracy and F1‑score, particularly in high‑dimensional settings where the joint learning of a discriminative metric and a large margin yields a more compact and separable representation. Moreover, the learned transformation matrix exhibits class‑specific alignment when visualized, confirming that the metric captures intrinsic data structure.
The paper concludes that SVM and LMNN, despite appearing to embody different learning biases—global margin maximization versus local neighborhood preservation—share a common underlying mechanism: distance transformation followed by margin enforcement. By framing both algorithms within a metric‑learning perspective, the authors not only clarify their theoretical relationship but also create a pathway for hybrid models. ε‑SVM exemplifies such a hybrid, inheriting the robustness of SVM’s margin maximization and the locality‑sensitive structure of LMNN. The authors suggest future work on kernelizing ε‑SVM, developing scalable online optimization schemes, and extending the framework to multi‑label or structured output problems. Overall, the study offers a compelling theoretical synthesis and a practical algorithm that bridges two influential paradigms in supervised learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment