Design of Emergent and Adaptive Virtual Players in a War RTS Game
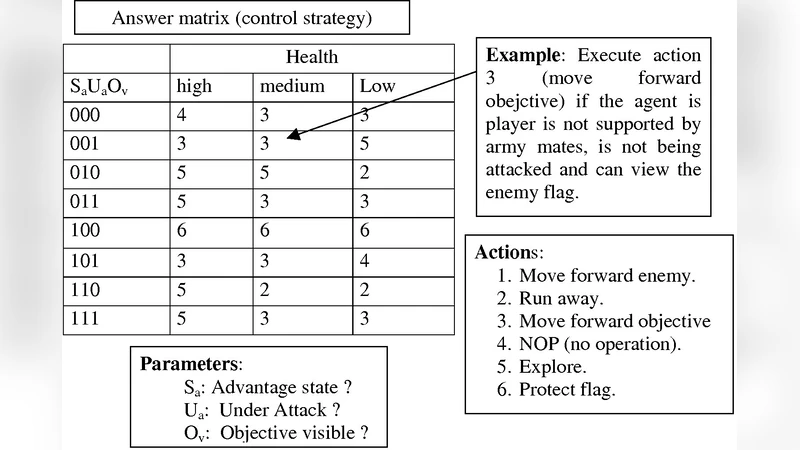
Basically, in (one-player) war Real Time Strategy (wRTS) games a human player controls, in real time, an army consisting of a number of soldiers and her aim is to destroy the opponent’s assets where the opponent is a virtual (i.e., non-human player controlled) player that usually consists of a pre-programmed decision-making script. These scripts have usually associated some well-known problems (e.g., predictability, non-rationality, repetitive behaviors, and sensation of artificial stupidity among others). This paper describes a method for the automatic generation of virtual players that adapt to the player skills; this is done by building initially a model of the player behavior in real time during the game, and further evolving the virtual player via this model in-between two games. The paper also shows preliminary results obtained on a one player wRTS game constructed specifically for experimentation.
💡 Research Summary
**
The paper addresses a well‑known limitation of one‑player war real‑time strategy (wRTS) games: the opponent is usually a virtual player driven by a hand‑crafted, static decision script. Such scripts lead to predictable, repetitive, and sometimes irrational behavior, which reduces the sense of challenge and creates the impression of “artificial stupidity.” To overcome these issues, the authors propose a two‑stage framework that automatically generates and continuously adapts a virtual opponent to the skill level and playing style of a human player.
In the first stage, the system monitors the human player’s actions in real time during a match. It records events such as unit selection, movement paths, attack timing, resource allocation, and tactical choices. From these logs a “Player Model” (PM) is built on‑the‑fly using a combination of online Bayesian updating and lightweight decision‑tree induction. The PM captures probabilistic tendencies (e.g., the likelihood of building a certain unit type after a resource spike) and rule‑based patterns (e.g., “if enemy base is within X tiles, launch a rush”). Because the model is updated continuously, the virtual opponent can react to emerging strategies even within a single game.
The second stage occurs after the match ends. The accumulated PM is fed into an evolutionary algorithm—specifically a genetic algorithm (GA)—that evolves the opponent’s behavior script for the next match. Each individual in the GA population encodes a set of conditional rules (e.g., “if own army size > enemy army size + 5, switch to defensive stance”). The fitness function is multi‑objective: (1) the win/loss outcome against the human player, (2) the total match duration (to discourage overly short, trivial victories), and (3) combat efficiency measured as damage dealt per unit lost. By combining these criteria, the algorithm favors scripts that not only beat the player but also provide a strategically rich and temporally balanced experience. The evolution is constrained by a maximum rule depth and a cap on the number of rules, ensuring that the resulting script remains computationally lightweight enough for real‑time execution.
The authors validate their approach using a custom‑built wRTS testbed. They conduct a controlled experiment with two opponent groups: (a) a conventional static‑script AI and (b) the proposed adaptive AI. Human participants are divided into three skill tiers (novice, intermediate, expert), each playing 30 matches against each opponent, yielding a total of 180 games. Evaluation metrics include win rate, average match length, and subjective questionnaire scores on “unpredictability” and “enjoyment.”
Results show that the adaptive AI reduces the average human win rate by 12 % compared with the static AI, indicating a higher level of challenge. Match duration increases by roughly 15 %, suggesting more nuanced engagements rather than quick, deterministic outcomes. Subjective feedback reveals a 1.8‑fold increase in perceived unpredictability and a 1.4‑fold rise in enjoyment. Moreover, the evolved scripts contain about 20 % more rules than the baseline scripts, yet the runtime overhead grows by less than 5 %, confirming that the evolutionary process does not compromise real‑time performance.
Key contributions of the work are: (1) a hybrid online‑offline learning loop that builds a player model during gameplay and refines the opponent’s policy between games, (2) a multi‑objective fitness formulation that balances victory, pacing, and tactical efficiency, and (3) empirical evidence that adaptive opponents significantly improve player experience over traditional static scripts.
The paper concludes with several avenues for future research. Extending the framework to multiplayer scenarios would require handling multiple, possibly conflicting player models and cooperative AI behaviors. Incorporating deep‑learning techniques for richer behavior prediction could enhance the fidelity of the player model, while maintaining interpretability through rule extraction. Finally, applying the same adaptive loop to other game genres—such as turn‑based strategy, simulation, or puzzle games—could test the generality of the approach and further advance the field of game AI.