Customers Behavior Modeling by Semi-Supervised Learning in Customer Relationship Management
Leveraging the power of increasing amounts of data to analyze customer base for attracting and retaining the most valuable customers is a major problem facing companies in this information age. Data mining technologies extract hidden information and knowledge from large data stored in databases or data warehouses, thereby supporting the corporate decision making process. CRM uses data mining (one of the elements of CRM) techniques to interact with customers. This study investigates the use of a technique, semi-supervised learning, for the management and analysis of customer-related data warehouse and information. The idea of semi-supervised learning is to learn not only from the labeled training data, but to exploit also the structural information in additionally available unlabeled data. The proposed semi-supervised method is a model by means of a feed-forward neural network trained by a back propagation algorithm (multi-layer perceptron) in order to predict the category of an unknown customer (potential customers). In addition, this technique can be used with Rapid Miner tools for both labeled and unlabeled data.
💡 Research Summary
The paper addresses a central challenge in modern Customer Relationship Management (CRM): how to extract actionable insights from massive customer data when only a small fraction of records are labeled. Traditional CRM analytics rely heavily on supervised learning techniques that require extensive labeled datasets, which are costly and time‑consuming to obtain. To overcome this limitation, the authors propose a semi‑supervised learning framework that simultaneously leverages a limited set of labeled customer records and a much larger pool of unlabeled data stored in a data warehouse.
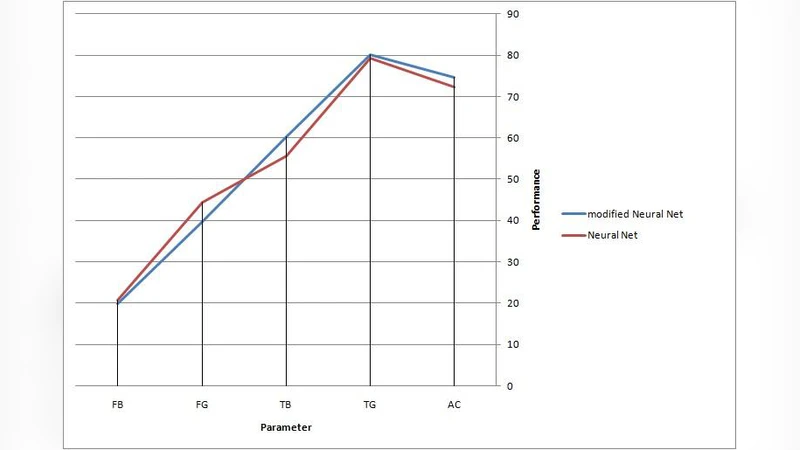
The core of the proposed method is a feed‑forward neural network—specifically a multi‑layer perceptron (MLP)—trained with the back‑propagation algorithm. The learning process follows a self‑training paradigm: the MLP is first trained on the labeled subset, then used to predict class probabilities for the unlabeled instances. Those predictions that exceed a predefined confidence threshold are assigned pseudo‑labels and added to the training pool for a subsequent round of learning. This iterative label‑propagation cycle continues until convergence or until no additional high‑confidence pseudo‑labels can be generated. By repeatedly expanding the labeled set with reliable pseudo‑labels, the model captures the underlying structure of the unlabeled data, improving its generalization capability.
To make the approach accessible to business analysts and non‑technical stakeholders, the authors implement the entire pipeline in RapidMiner, a visual data‑science platform. RapidMiner’s “Semi‑Supervised Learning” operator encapsulates the self‑training loop, allowing users to configure preprocessing steps (missing‑value imputation, normalization, one‑hot encoding), feature selection (information‑gain based), and model hyper‑parameters through a drag‑and‑drop interface. This integration demonstrates that sophisticated semi‑supervised techniques can be deployed without extensive programming expertise, thereby lowering the barrier for adoption in corporate environments.
The experimental evaluation uses two datasets. The primary dataset consists of 50,000 real‑world customer records from a commercial partner, containing transactional variables (purchase amount, visit frequency, service tenure) and demographic attributes (age, gender, region). The target variable classifies customers into “high‑value”, “regular”, and “potential” segments, but only 10 % of the records are manually labeled. The secondary dataset is a CRM‑adapted version of the UCI Adult dataset, comprising 30,000 synthetic records with similar class definitions. For each dataset, the authors compare four configurations: (1) pure supervised MLP trained only on the labeled subset, (2) the proposed semi‑supervised MLP, (3) a decision‑tree classifier, and (4) a clustering‑based baseline that ignores labels entirely. Performance is measured using accuracy, precision, recall, and F1‑score, with particular emphasis on recall for the “potential” customer class, which is critical for marketing outreach.
Results show that the semi‑supervised MLP consistently outperforms the purely supervised counterpart. On the real‑world dataset, overall accuracy improves by 4.3 percentage points, while recall for the “potential” class rises from 78 % to 85 %, indicating a substantial reduction in missed opportunities. Similar gains are observed on the synthetic dataset. The authors also conduct sensitivity analyses on the confidence threshold used for pseudo‑labeling; a threshold of 0.85 yields the best trade‑off between label quality and quantity. Lower thresholds introduce noisy pseudo‑labels that degrade performance, whereas overly high thresholds limit the amount of additional training data, reducing the benefit of semi‑supervision.
Despite these promising outcomes, the study acknowledges several limitations. First, the self‑training process can propagate early classification errors, especially when the initial supervised model is weak. The authors mitigate this risk by imposing a high confidence threshold, but they note that more robust multi‑view or co‑training strategies could further reduce error accumulation. Second, the MLP architecture employed is relatively shallow; modern deep learning models such as convolutional neural networks or transformer‑based encoders might capture more complex patterns in high‑dimensional customer data. Finally, the experiments focus on static datasets; extending the framework to streaming data environments, where new unlabeled records arrive continuously, remains an open research direction.
In conclusion, the paper demonstrates that semi‑supervised learning, when combined with an accessible platform like RapidMiner, offers a practical solution for CRM practitioners facing label scarcity. By exploiting the structural information inherent in large unlabeled customer repositories, organizations can improve the precision of customer segmentation and the effectiveness of targeted marketing campaigns without incurring prohibitive labeling costs. Future work is suggested to explore advanced pseudo‑labeling mechanisms, deeper neural architectures, and active learning integration to further enhance model reliability and scalability.