Some Recommended Protection Technologies for Cyber Crime Based on Social Engineering Techniques -- Phishing
Phishing (password + fishing) is a form of cyber crime based on social engineering and site spoofing techniques. The name of ‘phishing’ is a conscious misspelling of the word ‘fishing’ and involves stealing confidential data from a user’s computer and subsequently using the data to steal the user’s money. In this paper, we study, discuss and propose the phishing attack stages and types, technologies for detection of phishing web pages, and conclude our paper with some important recommendations for preventing phishing for both consumer and company.
💡 Research Summary
The paper provides a comprehensive overview of phishing, a cyber‑crime technique that blends social engineering with website spoofing to steal confidential user data, most commonly credentials, for financial gain. It begins by defining phishing as a deliberate misspelling of “fishing,” emphasizing that the attack’s success hinges on tricking users into voluntarily handing over sensitive information. The authors then break down the phishing lifecycle into four distinct stages: preparation, propagation, collection, and exploitation.
In the preparation stage, attackers conduct detailed profiling of potential victims, acquire or mimic legitimate domain names, and replicate the visual design of trusted brands. They often use free sub‑domains, compromised hosting, or domain‑generation algorithms to keep costs low while maintaining a high degree of authenticity. The propagation stage leverages a variety of channels—mass‑mailed phishing emails (including spear‑phishing and clone‑phishing), SMS‑based smishing, social‑media messages, and malicious advertisements—to distribute malicious links. The paper highlights that spear‑phishing messages are highly personalized, referencing internal terminology and recent events to increase credibility.
During the collection stage, victims are directed to counterfeit login pages that capture usernames, passwords, one‑time codes, and answers to security questions. Some advanced campaigns embed key‑logging scripts or malicious browser extensions to harvest credentials silently in the background. The exploitation stage uses the stolen data for direct financial theft (bank transfers, online purchases), unauthorized access to corporate systems, or as inputs for automated, large‑scale phishing campaigns, thereby amplifying the impact.
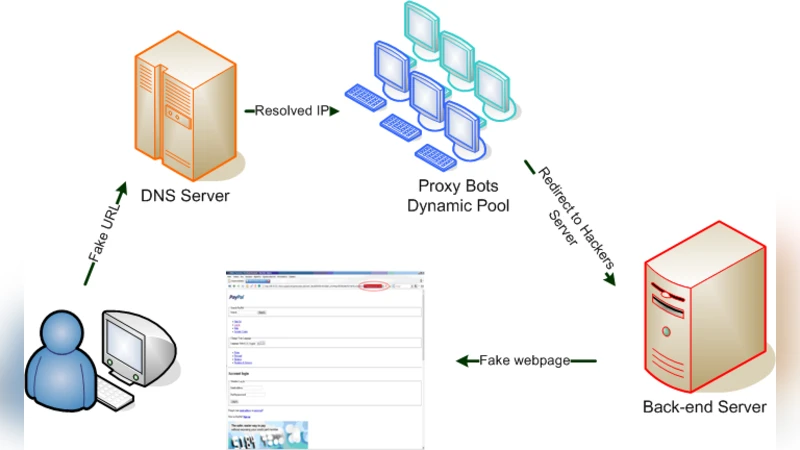
The authors categorize phishing attacks into five major types: spear phishing, watering‑hole phishing, clone phishing, smishing, and pharming. Each type is described with its unique delivery mechanism and threat profile. For example, watering‑hole attacks compromise a website frequently visited by a target group, while pharming manipulates DNS entries or host files to silently redirect users to fraudulent sites without any user‑initiated click.
A substantial portion of the paper is devoted to detection technologies. Four primary families are examined: static analysis, dynamic (sandbox) analysis, machine‑learning‑based models, and browser‑based extensions. Static analysis relies on rule‑based evaluation of URL strings, domain age, SSL certificate presence, and WHOIS data. Dynamic analysis executes the page in an isolated environment to monitor redirection chains, script behavior, cookie manipulation, and anomalous network traffic. Machine‑learning approaches extract textual features (suspicious vocabulary, spelling errors), visual features (logo similarity scores), and network‑level patterns, training classifiers to distinguish phishing from legitimate pages. Recent research cited in the paper combines convolutional neural networks for image similarity with transformer‑based natural language processing (e.g., BERT) for content analysis, achieving detection accuracies above 95 %. Browser extensions provide real‑time warnings but suffer from delayed signature updates, making them vulnerable to novel evasion techniques.
The paper also discusses the limitations of each detection method. Rule‑based static systems generate high false‑positive rates when confronted with rapidly evolving phishing variants. Machine‑learning models depend heavily on high‑quality, labeled datasets; scarcity of recent phishing samples can degrade performance. Dynamic analysis, while thorough, incurs significant computational overhead and may be bypassed by sophisticated anti‑sandbox techniques. Browser extensions, though user‑friendly, can be disabled or circumvented by attackers who exploit browser vulnerabilities.
Recognizing that technology alone cannot eradicate phishing, the authors stress the critical role of human factors. They propose a multi‑layered mitigation strategy that combines technical controls with user education and policy enforcement. Key recommendations include:
- Regular security awareness training with simulated phishing exercises to improve detection skills among employees and the general public.
- Widespread adoption of multi‑factor authentication (MFA), incorporating OTPs, hardware tokens, or biometrics to reduce reliance on passwords alone.
- Strengthening email authentication by implementing SPF, DKIM, and DMARC policies, thereby reducing the success of spoofed emails.
- Domain protection measures such as DNSSEC deployment, sub‑domain registration restrictions, and continuous monitoring of brand‑related domains to thwart pharming attacks.
- Integration of real‑time threat intelligence feeds that automatically update blacklists of malicious URLs and domains across security solutions.
- Consolidated security platforms that fuse static and dynamic analysis engines with machine‑learning models, providing a unified dashboard for incident response and reducing management complexity.
In the conclusion, the paper warns that phishing techniques continue to evolve, exploiting both technological vulnerabilities and human psychology. A singular defensive measure is insufficient; only a coordinated approach that blends advanced detection algorithms, robust authentication mechanisms, proactive policy enforcement, and continuous user education can meaningfully reduce the risk posed by phishing attacks. The authors call for ongoing research into adaptive machine‑learning models, better data‑sharing frameworks among organizations, and the development of standardized metrics for evaluating phishing defenses.
Comments & Academic Discussion
Loading comments...
Leave a Comment