Spam filtering by quantitative profiles
Instead of the 'bag-of-words' representation, in the quantitative profile approach to spam filtering and email categorization, an email is represented by an m-dimensional vector of numbers, with m fixed in advance. Inspired by Sroufe et al. [Sroufe, …
Authors: M. Grendar, J. v{S}kutova, V. v{S}pitalsky
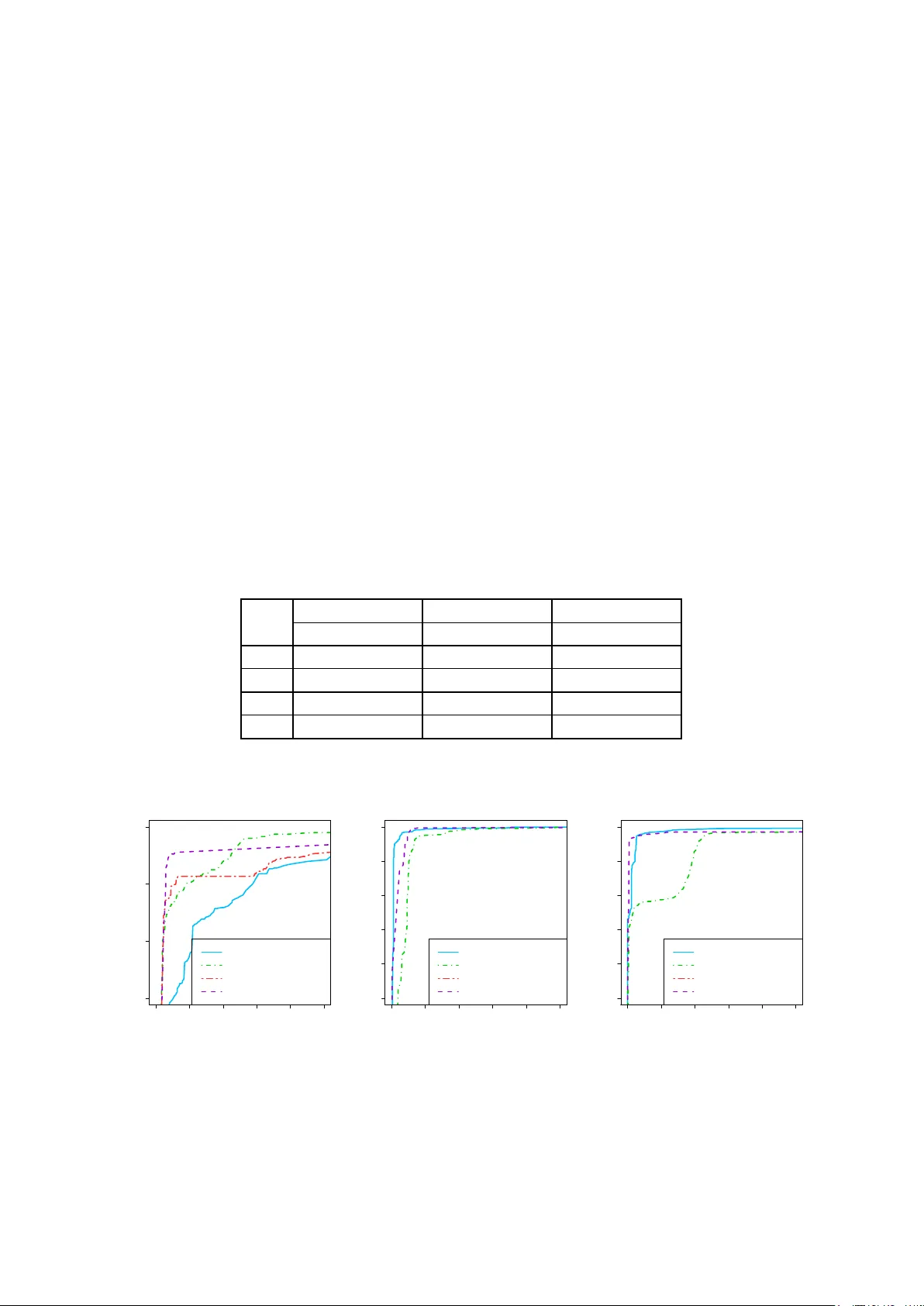
Spam filtering b y quan titativ e profiles M. Grend´ ar a , J. ˇ Skuto v´ a a , V. ˇ Spitalsk´ y a a Slovanet a.s., Z´ ahr adn ´ ıcka 151, 821 08 Br atislava, Slovakia Abstract Instead of the “bag-of-w ords” represen tation, in the quan titativ e profile approach to spam filtering and email categorization, an email is represented b y an m -dimensional v ector of num bers, with m fixed in adv ance. Inspired by Sroufe et al. [Sroufe, P ., Phithakkitnuk o on, S., Dantu, R., and Cangussu, J. (2010). Email shap e analysis. In LNCS , 5935, pp. 18-29] tw o instances of quantitativ e profiles are considered: line profile and character profile. Performance of these profiles is studied on the TREC 2007, CEAS 2008 and a priv ate corpuses. At low computational costs, the tw o quantitativ e profiles achiev e p erformance that is at least comparable to that of heuristic rules and naiv e Bay es. Keywor ds: email categorization, spam filtering, quan titative profile, character profile, line profile, Random F orest 1. In tro duction Spam is an unsolicited email message. F rom the receiver’s p ersp ective, spam is an anno y ance and th us it is necessary to blo c k its delivery , for instance, by filtering it out. T raditional approach to spam filtering and email categorization that is based on heuristic rules, naive Ba yes filtering and/or text-mining suffers from sev eral deficiencies. Among shortcomings of the traditional approac h there are high computational costs, language dep endence, necessity to up date the heuristic rules, high n umber of rules, and vulnerability . Instead of the “bag-of-words” representation, employ ed in text-mining and naive Bay es filtering, in the quan titative profile ( QP ) approach that we prop ose, an email is represen ted by an m -dimensional vector of n umbers with m fixed in adv ance. Inspired by Sroufe, Phithakkitnuk oon, Dantu, and Cangussu [12], tw o instances of QP s are considered: line profile ( LP ) and c haracter profile ( CP ). Informally put, the line profile of an email is a v ector of lengths of the first m lines. The character profile is a histogram of characters. Of course, man y other QP s are conceiv able. The main adv an tages of the t wo considered quantitativ e profiles are i ) sound p erformance, ii ) simple computabilit y , iii ) language-indep endence, iv ) robustness to outlying emails, v ) high scalabilit y and v i ) low vulnerabilit y . The considered tw o instances of the quan titativ e profile approac h p erform comparably to the naive Ba yes filtering and heuristics-based approaches and p erform very well also in a multi-language, non-English comm unication. F urthermore, the satisfactory p erformance is attained b y means of a small set of easily computable quantitativ e features. A p erformance study was done on the TREC 2007, CEAS 2008 and a priv ate corpuses. T o demonstrate the pow er of the considered QP s, the profiles are obtained from ra w emails, without any prepro cessing. Consequen tly , w e inten tionally ignore the structure of emails and character enco ding. On the tw o QP s, the Random F orest algorithm substantially outp erforms other classification algorithms (SVM, LD A/QD A, logistic regression). Thanks to the Random F orest, the QP approach gains robustness to emails with extreme-v alued profiles as well as high scalability . Email addr esses: marian.grendar@slovanet.net (M. Grend´ ar), jana.skutova@slovanet.net (J. ˇ Skutov´ a), vladimir.spitalsky@slovanet.net (V. ˇ Spitalsk´ y) Pr eprint submitte d to Elsevier June 4, 2021 In our view, classification and email categorization b y LP (or CP ) should hav e lo w vulnerabilit y . F or, the lines the lengths of which differentiates b etw een spam and ham, c hange from corpus to corpus. F or instance, in the CEAS 2008 corpus, the most imp ortant for deciding b etw een spam and ham are the lengths of the (10, 17, 15, 14, 16)-th lines, whilst in the TREC 2007 corpus they are the (5, 13, 6, 15, 7)-th lines. As the training corpus is usually not av ailable to a spammer, it should b e not easy to ev ade the LP (or CP ) filter. As a by-product of a p erformance study of CP and LP , we note that in the TREC 2007 and CEAS 2008 corpuses the n um b er of header lines is capable of discriminating betw een spam and ham, at a rate that is, in our view, to o high. Consequently , the corpuses lead to ov erly optimistic p erformance of spam filtering metho ds. The pap er is organized as follows. In the next section we formally introduce the QP s mentioned ab ov e. Then, in Section 3, w e describ e the three email corpuses used for assessmen t of the QP s’ performance. In Section 4 we describ e measures used for performance ev aluation. The results are summarized in Section 5. In the concluding section some directions for future research are briefly discussed. All the computations w ere p erformed with R [7]. T o make the results repro ducible, a supplementary material including the source co de was prepared, cf. [4]. 2. Quan titativ e profiles The quantitative pr ofile ( QP ) of an email is an m -dimensional vector of real n umbers that represents the email. The dimension m of the profile is set in adv ance, and it is the same for all emails. In this paper we consider t wo particular QP s – the line profile and the character profile. These profiles can b e introduced by means of a simple probabilistic mo del. An email is represented as a realization of a vector random v ariable, that is generated by a hierarchical data generating pro cess. The length n of an email is an integer-v alued random v ariable, with the probabilit y distribution F n . Given the length, the email is represented b y a random v ector X n 1 = ( X 1 , . . . , X n ) from the probabilit y distribution F X n 1 | n with the supp ort in A n , where A = { a 1 , . . . , a m } is a finite set (alphab et) of size m = |A| . Then, the char acter pr ofile ( CP ) of an em ail is an m -dimensional random v ector CP = ( CP 1 , . . . , CP m ), where CP j = n X i =1 I { X i = a j } , j = 1 , . . . , m, and I is the indicator function. http://www.theinsider.org/news/emails/unsubscribe/ To be removed from this mailing list please use the form provided: −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− http://www.theinsider.org/news/article.asp?id=2476 American gunman massacres students and staff at American university *** BREAKING NEWS *** Lines: 10 Content−Length: 336 Status: O X−OriginalArrivalTime: 17 Apr 2007 10:44:10.0734 (UTC) Message−ID: X−MimeOLE: Produced By Microsoft MimeOLE V6.00.3790.3959 Date: Tue, 17 Apr 2007 11:44:10 +0100 Subject: "The Insider" − News Bulletin To: "Subscriber" From: "The Insider" Tue, 17 Apr 2007 11:44:10 +0100 Received: from mail pickup service by cosmic200 with Microsoft SMTPSVC; for ; Tue, 17 Apr 2007 06:44:26 −0400 by speedy.uwaterloo.ca (8.12.8/8.12.5) with ESMTP id l3HAiP0I026448 Received: from cosmic200 (windows.globalgold.co.uk [194.1.150.45]) Return−Path: From the_insider@postmaster.co.uk Tue Apr 17 06:44:26 2007 (a) Email (b) Line profile (c) Character profile Figure 1: Graphical representation of the line and character profiles of an email In order to introduce the other QP , it is necessary to select a sp ecial character (or a subset of c haracters) from the alphab et. Let k b e the n umber of o ccurrences of the sp ecial character in an email and let T j 2 ( j = 1 , . . . , k ) b e the index of the j -th o ccurrence of the sp ecial character; put T 0 = 0. Then the binary pr ofile ( BP ) of an email is defined as a ˜ k -dimensional random v ector BP = ( BP 1 , . . . , BP ˜ k ), where BP j = T j − T j − 1 − 1 , j = 1 , . . . , ˜ k . There, ˜ k is the maximum allo wable n umber of the o ccurrences of the sp ecial c haracter and it is set in adv ance. Hence, if k > ˜ k , the rest of the email is ignored. And if an email has k < ˜ k , BP j = 0 for j > k . In this work, an email is understo o d as a stream of bytes without any prepro cessing, so that A is taken to b e the ASCI I c haracter set. The end-of-line is taken for the sp ecial c haracter. Consequen tly , the binary profile b ecomes the line pr ofile ( LP ) since B P j is the length of the j -th line of an email in b ytes. W e fix the maximal n umber ˜ k of considered lines to 100. 3. Data sets T o assess the p erformance of the tw o quantitativ e profiles, we consider three email corpuses: the publicly a v ailable TREC 2007 and CEAS 2008 corpuses, and a priv ate corpus. The TREC 2007 corpus [3] comprises ov er 75 000 emails (25 220 hams and 50 199 spams), of whic h appro ximately 67% is spam, and the rest are ham emails. F or the training phase w e used the first 50 000 emails. The rest forms the test set. The ratio of spam to ham in the training and test sets is approximately 2:1. The other publicly av ailable corpus, used for the p erformance analysis of QP s, is CEAS 2008 [2]. It consists of 137 705 emails (27 126 hams and 110 579 spams). The corpus w as hand lab eled [9]. T o form the training set, we used the first 90 000 emails. The test set comprises the remaining emails. The ratio of spam to ham in the training and test sets is approximately 4:1. P erformance of spam filtering algorithms is typically assessed on English language corpuses, such as the ab o ve mentioned TREC and CEAS. When applied to non-English emails, their p erformance may b e differen t. Due to the supp ort from a Slov ak internet services provider, w e enjoy ed the opp ortunit y of access to a priv ate corpus created in 2010, that comprises mainly non-English emails. Structure of the corpus is summarized in T able 1. The training set w e used consists of 11 050 emails and the test set consists of 12 200 emails. T able 1: Comp osition of the priv ate corpus corpus s.ham adv ert notify spam total train 6837 1611 1225 1377 11 050 test 3650 1409 5758 1383 12 200 The priv ate corpus w as hand lab eled. Emails w ere placed into one of the tw o groups: ham and spam. Moreo ver, ham w as divided into advert, solicited ham (denoted s.ham) and notify . Based on the language of the ma jor part of an email, the emails w ere placed into one of the four language groups: Slo v ak/Czech, English, German, and other. The corpus comprises 64% of the Slo v ak/Czech ham in the training set and 38% in the test set. 4. Classification algorithm and p erformance measures Quan titative profiles serve as an input to a classification algorithm. In this w ork w e use the Random F orest classifier, in tro duced b y Breiman [1] and p orted to R by Liaw and Wiener [6], with the default settings. W e hav e employ ed also LDA, logistic regression, LASSO and SVM [5], but these metho ds p erformed muc h w orse. 3 T o ev aluate QPs’ p erformance, we calculate the false p ositive rate fpr = F P / ( T N + F P ) and the false negativ e rate fnr = F N/ ( T P + F N ), where TP ( TN ) stands for the num b er of true p ositive (true negativ e) emails, i.e. the correctly recognized spam (ham) emails; and FP ( FN ) stands for the n umber of false positive (false negative) emails, i.e. the incorrectly recognized ham (spam) emails, resp ectiv ely . W e also presen t the receiv er operating c haracteristic ( ROC ) curv e, i.e. the graph of the true p ositive rate vs. the false p ositive rate, obtained as functions of the decision threshold. The area A UC under the ROC curv e is also rep orted. 5. Results In this section w e summarize p erformance of the basic QP s on the three corpuses mentioned ab o ve. 5.1. Comp arison of quantitative pr ofiles with Sp amAssassin and Bo gofilter F or the sake of comparison, we rep ort also results for SpamAssassin ( SA ) [11], version 3.3.1, off-line and without the Ba yes filter, and Bogofilter ( BF ) [8], v ersion 1.2.2 with the default configuration. On the priv ate corpus, the output from SA was processed by the Random F orest classification algorithm, as it attains muc h b etter p erformance than SA with the default weigh ts. In addition to muc h b etter p erformance, it allows for email categorization, which is imp ossible with the default SA . On the public corpuses, how ever, the default SA classification p erforms b etter. Bogofilter allows a binary classification only . BF was learnt in the batch mo de. T able 2: fnr (%) at fixed fpr = 0 . 5% or fpr = 1% priv ate TREC07 CEAS08 filter at 0.5% at 1% at 0.5% at 1% at 0.5% at 1% CP 14.39 11.64 2.53 0.49 4.38 4.25 LP 21.33 20.10 0.30 0.13 0.39 0.27 SA 12.68 10.10 35.87 30.51 76.14 69.92 BF 13.05 7.38 0.40 0.06 0.47 0.36 0.00 0.02 0.04 0.06 0.08 0.10 0.80 0.85 0.90 0.95 F alse positive rate T rue positive rate A UC LP = 0.96395 A UC CP = 0.95982 A UC SA = 0.95682 A UC BF = 0.96131 (a) priv ate corpus 0.00 0.01 0.02 0.03 0.04 0.05 0.90 0.92 0.94 0.96 0.98 1.00 F alse positive rate T rue positive rate A UC LP = 0.99986 A UC CP = 0.9993 A UC SA = 0.94216 A UC BF = 0.99959 (b) TREC 2007 corpus 0.00 0.01 0.02 0.03 0.04 0.05 0.90 0.92 0.94 0.96 0.98 1.00 F alse positive rate T rue positive rate A UC LP = 0.99974 A UC CP = 0.99889 A UC SA = 0.79569 A UC BF = 0.99842 (c) CEAS 2008 corpus Figure 2: ROC curves 4 On the priv ate corpus, for fpr = 0 . 5% the b est p erformance is attained by SA and BF , and CP p erforms only slightly worse, cf. T able 2 and Figure 2. LP is slightly less effectiv e, and it attains fnr around 21% at fpr = 0 . 5%. With the exception of SA , on the public corpuses all the studied filters attain muc h b etter p erformance than on the priv ate corpus, see also Section 5.5. The tw o QP s p erform muc h b etter than SA as T able 2 as w ell as Figures 2b and 2c indicate. The line profile attains b etter p erformance (smaller fnr ) than BF at the 0 . 5% lev el of fpr . 5.2. Email c ate gorization for the private c orpus On the priv ate corpus, p erformance of CP and especially LP in spam filtering (i.e. binary categorization) is w orse than that of SA and BF . How ever, in categorization of emails into one of the four categories, b oth CP and LP p erform muc h b etter in the most interesting category of solicited ham. Misclassification table for CP and SA is in T able 3. T able 3: CP and SA confusion tables for categorization, priv ate corpus CP SA coun t advert s.ham notify spam adv ert s.ham notify spam adv ert 530 837 10 32 515 830 17 47 ham 26 3597 27 0 95 3290 248 17 notify 20 237 5499 2 24 235 5498 1 spam 37 221 12 1113 44 161 14 1164 5.3. Comp arison with email shap e analysis Sroufe et al. [12] suggest to filter spam b y means of its shap e, which the authors define (using our terminology) as a smoothed line profile of email bo dy , where smo othing is p erformed b y the kernel smo other. Sroufe et al. also rep ort the total error of 30%, based on a preliminary study on the TREC corpus. F urther, the authors find the p erformance v ery go o d, ’considering that no conten t or con text w as even referenced’, cf. [12], p. 26. The line profile, that is inspired b y the email shap e analysis, attains on the TREC corpus fpr = 4 . 23% a fnr = 17 . 00%, when the threshold is not optimized and email headers are inten tionally not tak en into account, cf. Section 5.5. This gives the total error around 12 . 29% and indicates that smo othing is unnecessary . 5.4. R e duction of the fe atur e sp ac e It is also imp ortant to know to what extent the dimension of the QP feature space can b e reduced without substantiv e reduction of the classifier’s p erformance. T o this end the top 20 and the top 50 features w ere considered, where the ranking of features was provided by the Random F orest’s measure of the mean decrease of accuracy . The study was done on the priv ate corpus and solely the email b o dy was considered. In the binary classification the top 20 features of the line profile attain essentially the same p erformance as the en tire line profile of the length 100. In the case of CP , to attain the full-set p erformance, the top 50 features out of 256 are needed. The same holds for SA . Ho wev er, in the case of the email categorization it is not p ossible to reduce the dimension of SA features without substantiv e decrease in accuracy . 5 5.5. Why ar e TREC and CEAS misle ading? All the considered email filters except of SA attain muc h better p erformance on the public corpuses than on the priv ate one; cf. T able 2. In search for explanation we hav e noted that in the public corpuses, unlik e to the priv ate corpus, the n umber of header lines con tains information that is substan tive for spam filtering. Figure 3 depicts the distribution of the num b er of lines in header, for spam and ham, in the TREC corpus. Once the email header is not taken in to accoun t, and solely the email b ody is pro cessed, p erformance of LP and CP worsens and b ecomes comparable to that on the priv ate corpus; cf. T able 4. In T able 4, LPH ( CPH ) denotes the line (character) profile of email header and LPB ( CPB ) denotes the line (character) profile of email b o dy , resp ectiv ely . Number of header lines Density 0.00 0.05 0.10 20 40 60 ham 0.00 0.05 0.10 spam Figure 3: Distribution of emails with resp ect to the num b er of header lines, for spam and ham, in the TREC 2007 corpus T able 4: fnr (%) at fixed fpr = 0 . 5% or fpr = 1% priv ate TREC07 CEAS08 filter at 0.5% at 1% at 0.5% at 1% at 0.5% at 1% CPH 16.51 13.71 0.19 0.05 0.78 0.30 LPH 18.06 15.11 1.78 0.12 0.68 0.36 CPB 14.24 11.92 15.05 5.47 4.70 4.51 LPB 21.26 18.58 45.01 43.67 7.07 6.35 The decline of p erformance of CP and LP caused by exclusion of email headers supp orts the hypothesis that in the TREC 2007 and CEAS 2008 corpuses the profiles of headers carry a substantiv e information for discriminating b et ween spam and ham. 5.6. Summary of the p erformanc e study The empirical study implies that the simple and easily obtainable line and character profiles attain at least comparable p erformance as the optimally tuned SpamAssassin, which is based on hundreds of fixed rules, and the p erformance of character profiles is close to that of Bogofilter. P articularly , on the public corpuses LP is b etter than BF and SA . On the priv ate corpus CP attains comparable p erformance as BF and SA , and LP is slightly worse. 6 6. Conclusions Motiv ated b y Sroufe et al. [12], w e ha ve prop osed the quantitativ e profile approac h to email classification. In this rep ort w e explored tw o quantitativ e profiles, the line profile and the c haracter profile. The profiles are obtained from ra w emails, without an y prepro cessing. The computational costs of the tw o profiles are minimal. Performance of the profiles was studied on the TREC 2007, CEAS 2008 corpuses and a priv ate, multi-lingual corpus. The tw o quan titative profiles attained at least comparable p erformance as the optimally tuned SpamAssassin and the batc h-mo de learnt Bogofilter. Besides the go o d performance, the tw o quan titativ e profiles are language indep endent and the res ulting filter is robust to outlying emails, highly scalable and has lo w vulnerability . As a by-product, w e hav e noted that the num b er of header lines in the TREC 2007 and CEAS 2008 corpuses contain rather strong information on the email class. The corpuses thus lead to ov erly optimistic p erformance of spam filters. In the near future w e plan to explore quan titative profiles based on size and structure of emails, on the sym b olic dynamics, and another instances of the binary profile. Also, the profiles are w orth employing in a semi-sup ervised email categorization. 7. Ac kno wledgement Stim ulating feedback from J´ an Gallo and Stanisla v Z´ ari ˇ s is gratefully ackno wledged. This pap er was prepared as a part of the pro ject “SP AMIA”, M ˇ S SR 3709/2010-11, supported b y the Ministry of Education, Science, Researc h and Sp ort of the Slo v ak Republic, under the heading of the state budget support for researc h and developmen t. References [1] Breiman, L. (2001). Random forests. Machine L earning , 45(1), 5-32. [2] Cormac k, G. V., and Lynam, T. R. (2008). CEAS 2008 corpus. http://plg.uwaterloo.ca/ ~ gvcormac/ceascorpus [3] Cormac k, G. V., and Lynam, T. R. (2007). TREC 2007 corpus. http://plg.uwaterloo.ca/ ~ gvcormac/treccorpus07/about.html [4] Grend´ ar, M., ˇ Skutov´ a, J., and ˇ Spitalsk´ y, V. (2011). Supplement to “Spam filtering by quantitativ e profiles”. http://www.savbb.sk/ ~ grendar/spam/SupplementToQuantitativeProfiles.pdf [5] Hastie, T., Tibshirani, R., and F riedman, J. (2009). The Elements of Statistic al L e arning , 2-nd ed., Springer, New Y ork. [6] Lia w, A., and Wiener, M. (2002). Classification and regression by randomF orest. R News , 2(3), 18-22. [7] R Dev elopment Core T eam (2010). R: A language and en vironment for statistical computing. R F oundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0. http://www.R- project.org [8] Ra ymond, E. S., Relson, D., Andree, M., and Louis, G. 2004. Bogofilter. http://Bogofilter.sourceforge.net [9] Segal, R., Bratko, A., and Cormack, G. (2008). CEAS 2008 Spam Filter Challenge, conference talk, http://www.ceas.cc/2008/challenge/results.pdf [10] Sing, T., Sander, O., Beeren winkel, N., and Lengauer, T. (2009). R OCR: Visualizing the performance of scoring classifiers. R pack age version 1.0-4. http://CRAN.R- project.org/package=ROCR [11] SpamAssassin. http://spamassassin.apache.org [12] Sroufe, P ., Phithakkitnuk o on, S., Dantu, R., and Cangussu, J. (2010). Email shap e analysis. In Distribute d Computing and Networking , Lecture Notes in Computer Science, K. Kant et al. (eds), 5935/2010, pp. 18-29. 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment