Bayesian Active Learning for Classification and Preference Learning
Information theoretic active learning has been widely studied for probabilistic models. For simple regression an optimal myopic policy is easily tractable. However, for other tasks and with more complex models, such as classification with nonparametr…
Authors: Neil Houlsby, Ferenc Huszar, Zoubin Ghahramani
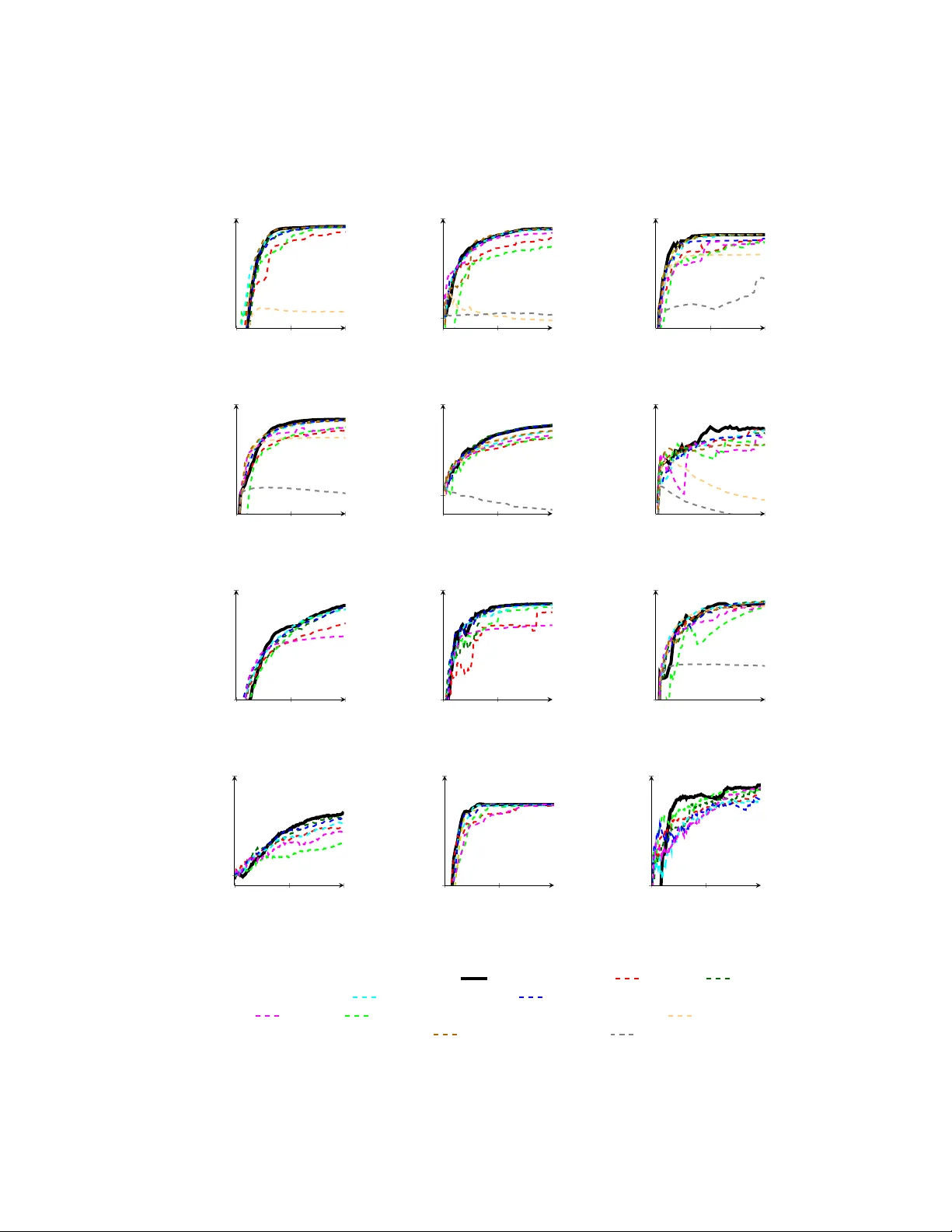
Ba y esian Activ e Learning for Classification and Preference Learning Neil Houlsb y , F erenc Husz´ ar, Zoubin Ghahramani, M´ at´ e Lengyel Computational and Biological Learning Lab oratory Univ ersity of Cam bridge No vem ber 27, 2024 Abstract Information theoretic activ e learning has b een widely studied for prob- abilistic models. F or simple regression an optimal m yopic p olicy is easily tractable. How ever, for other tasks and with more complex mo dels, such as classification with nonparametric mo dels, the optimal solution is harder to compute. Curren t approaches make approximations to achiev e tractabil- it y . W e propose an approac h that expresses information gain in terms of predictive entropies, and apply this metho d to the Gaussian Process Classifier (GPC). Our approach mak es minimal approximations to the full information theoretic ob jectiv e. Our exp erimental p erformance compares fa vourably to many popular active learning algorithms, and has equal or lo wer computational complexity . W e compare well to decision theoretic approac hes also, which are privy to more information and require muc h more computational time. Secondly , by developing further a reformulation of binary preference learning to a classification problem, we extend our algorithm to Gaussian Pro cess preference learning. 1 In tro duction In most machine learning systems, the learner passiv ely collects data with which it mak es inferences ab out its en vironment. In activ e learning, how ev er, the learner seeks the most useful measurements to b e trained upon. The goal of activ e learning is to produce the b est mo del with the least p ossible data; this is closely related to the statistical field of optimal experimental design. With the adven t of the in ternet and expansion of storage facilities, v ast quantities of unlab elled data hav e become a v ailable, but it can b e costly to obtain lab els. Finding the most useful data in this v ast space calls for efficient active learning algorithms. Tw o approac hes to activ e learning are to use decision and information the- ory [ Kap oor et al., 2007 , Lindley , 1956 ]. The former minimizes the exp ected 1 losses encountered after making decisions based on the data collected i.e. min- imize the Bay es posterior risk [ Ro y and McCallum, 2001 ]. Maximising perfor- mance under test is the ultimate ob jective of most learners, how ever, ev aluat- ing this ob jective can b e very hard. F or example, the methods proposed in [ Kap oor et al., 2007 , Zh u et al., 2003 ] for classification are in general expensive to compute. F urthermore, one ma y not kno w the loss function or test distribution in adv ance, or ma y w ant the mo del to p erform well on a v ariety of loss functions. In extreme scenarios, such as exploratory data analysis, or visualisation, losses ma y be v ery hard to quantify . This motiv ates information theoretic approaches to activ e learning, which are agnostic to the decision task at hand and particular test data, this is known an inductiv e approach. They seek to reduce the n um b er of feasible mo dels as quic kly as possible, using either heuristics (e.g. margin sampling [ T ong and Koller, 2001 ]) or by formalising uncertain ty using w ell studied quantities, such as Shannons en tropy and the KL-divergence [ Co ver et al., 1991 ]. Although the latter approach w as proposed sev eral decades ago [ Lindley , 1956 , Bernardo, 1979 ], it is not alwa ys straigh tforward to apply the criteria to complicated mo dels suc h as nonparametric pro cesses with infinite parameter spaces. As a result man y algorithms exist whic h compute appro ximate p osterior entropies, p erform sampling, or work with related quantities in non-probabilistic mo dels. W e return to this problem, presenting the full information criterion and demonstrate ho w to apply it to Gaussian Pro cesses Classification (GPC), yielding a nov el active learning algorithm that makes minimal appro ximations. GPC is a p o werful, non-parametric k ernel-based mo del, and p oses an interesting problem for information-theoretic activ e learning b ecause the parameter space is infinite dimensional and the p osterior distribution is analytically intractable. W e present the information theoretic approach to active learning in Section 2. In Section 3 w e apply it to GPC, and show how to extended our method to preference learning. In Section 4 we review other approaches and ho w they compare to our algorithm. W e tak e particular care to contrast our approac h to the Informative V ector Machine, that addresses data p oin t selection for GPs directly . W e present results on a wide v ariety of datasets in Section 5 and conclude in Section 6. 2 Ba y esian Information Theoretic Activ e Learn- ing W e consider a fully discriminative mo del where the goal of active learning is to discov er the dependence of some v ariable y ∈ Y on an input v ariable x ∈ X . The k ey idea in active learning is that the learner chooses the input queries x i ∈ X and observes the system’s response y i , rather than passively receiving ( x i y i ) pairs. Within a Bay esian framework we assume existence of some laten t param- eters, θ , that con trol the dependence b etw een inputs and outputs, p ( y | x , θ ). Ha ving observed data D = { ( x i , y i ) } n i =1 , a p osterior distribution o ver the pa- 2 rameters is inferred, p ( θ |D ). The central goal of information theoretic ac- tiv e learning is to reduce the nu mber p ossible hypotheses maximally fast, i.e. to minimize the uncertain ty ab out the parameters using Shannon’s entrop y [ Co ver et al., 1991 ]. Data p oints D 0 are selected that satisfy arg min D 0 H[ θ |D 0 ] = − R p ( θ |D 0 ) log p ( θ |D 0 )d θ . Solving this problem in general is NP-hard; how ev er, as is common in sequen tial decision making tasks a my opic (greedy) approxi- mation is made [ Hec kerman et al., 1995 ]. It has bee n shown that the my opic p olicy can perform near-optimally [ Golo vin and Krause, 2010 , Dasgupta, 2005 ]. Therefore, the ob jectiv e is to seek the data point x that maximises the decrease in exp ected posterior en tropy: arg max x H[ θ |D ] − E y ∼ p ( y | x D ) [H[ θ | y , x , D ]] (1) Note that exp ectation o ver the unseen output y is required. Many w orks e.g. [ MacKa y , 1992 , Krishnapuram et al., , La wrence et al., 2003 ] prop ose using this ob jectiv e directly . How ever, parameter p osteriors are often high dimen- sional and computing their entropies is usually intractable. F urthermore, for nonparametric pro cesses the parameter space is infinite dimensional so Eqn. (1) b ecomes p o orly defined. T o a v oid gridding parameter space (exp onentially hard with dimensionalit y), or sampling (from which it is notoriously hard to estimate en tropies without introducing bias [ P anzeri and Petersen, 2007 ]), these papers mak e Gaussian or lo w dimensional approximations and calculate the entrop y of the approximate p osterior. A second computational difficulty arises; if N x data p oin ts are under consideration, and N y resp onses may b e seen, then O ( N x N y ), p oten tially expensive, p osterior up dates are required to calculate Eqn. (1). An imp ortant insight arises if we note that the ob jective in Eqn. (1) is equiv alen t to the conditional m utual information betw een the unknown output and the parameters, I[ θ , y | x , D ]. Using this insight it is simple to sho w that the ob jective can be rearranged to compute entropies in y space: arg max x H[ y | x , D ] − E θ ∼ p ( θ |D ) [H[ y | x , θ ]] (2) Eqn. (2) o vercomes the c hallenges w e describ ed for Eqn. (1) . En tropies are no w calculated in, usually low dimensional, output space. F or binary classification, these are just en tropies of Bernoulli v ariables. Also θ is now conditioned only on D , so only O (1) p osterior up dates are required. Eqn. (2) also provides us with an in teresting intuition ab out the ob jective; we seek the x for which the mo del is marginally most uncertain ab out y (high H[ y | x , D ]), but for which individual settings of the parameters are confident (lo w E θ ∼ p ( θ |D ) [H[ y | x , θ ]] ). This can b e in terpreted as seeking the x for whic h the parameters under the p osterior disagree about the outcome the most, so w e refer to this ob jective as Ba yesian Active Learning b y Disagreement (BALD). W e presen t a method to apply Eqn. (2) directly to GPC and preference learning. W e no longer need to build our entrop y calculation around the type of p osterior approximation (as 3 in [ MacKa y , 1992 , Krishnapuram et al., , La wrence et al., 2003 ]) but are free to c ho ose from many of the a v ailable algorithms. Minimal additional approximations are introduced, and so, to our knowledge our algorithm represents the most exact and fastest wa y to perform full information-theoretic activ e learning in non-parametric discriminative mo dels. 3 Gaussian Pro cesses for Classification and Pref- erence Learning In this section we derive the BALD algorithm for Gaussian Pro cess classification (GPC). GPs are a p o werful and p opular non-parametric to ol for regression and classification. GPC app ears to b e an esp ecially challenging problem for information-theoretic activ e learning b ecause the parameter space is infinite, ho wev er, by using (2) w e are able to calculate fully the relev ant information quan tities without having to w ork out entropies of infinite dimensional ob jects. The probabilistic model underlying GPC is as follo ws: f ∼ GP( µ ( · ) , k ( · , · )) y | x , f ∼ Bernoulli(Φ( f ( x ))) The latent parameter, no w called f is a function X → R , and is assigned a Gaussian pro cess prior with mean µ ( · ) and co v ariance function or kernel k ( · , · ). W e consider the probit case where given the v alue of f , y tak es a Bernoulli distribution with probabilit y Φ( f ( x )), and Φ is the Gaussian CDF. F or further details on GPs see [Rasm ussen and Williams, 2005]. Inference in the GPC model is intractable; given some observ ations D , the p osterior ov er f b ecomes non-Gaussian and complicated. The most commonly used approximate inference methods – EP , Laplace approximation, Assumed Densit y Filtering and sparse metho ds – all approximate the p osterior by a Gaussian [ Rasm ussen and Williams, 2005 ]. Throughout this section we will assume that we are provided with such a Gaussian approximation from one of these metho ds, though the active learning algorithm do es not care whic h one. In our deriv ation w e will use 1 ≈ to indicate where suc h an approximation is exploited. The informativeness of a query x is computed using Eqn. (2) . The en trop y of the binary output v ariable y giv en a fixed f can b e expressed in terms of the binary entrop y function h: H[ y | x , f ] = h (Φ( f ( x )) h( p ) = − p log p − (1 − p ) log(1 − p ) Exp ectations ov er the p osterior need to b e computed. Using a Gaussian approxi- mation to the p osterior, for each x , f x = f ( x ) will follow a Gaussian distribution with mean µ x , D and v ariance σ 2 x , D . T o compute Eqn. (2) w e ha ve to compute 4 t wo entrop y quantities. The first term in Eqn. (2) , H[ y | x , D ] can b e handled analytically for the probit case: H[ y | x , D ] 1 ≈ h Z Φ( f x ) N ( f x | µ x , D , σ 2 x , D ) d f x = h Φ µ x , D q σ 2 x , D + 1 (3) The second term, E f ∼ p ( f |D ) [H[ y | x , f ]] can be computed approximately as follo ws: E f ∼ p ( f |D ) [H[ y | x , f ]] 1 ≈ Z h(Φ( f x )) N ( f x | µ x , D , σ 2 x , D ) d f x (4) 2 ≈ Z exp − f 2 x π ln 2 N ( f x | µ x , D , σ 2 x , D ) d f x = C q σ 2 x , D + C 2 exp − µ 2 x , D 2 σ 2 x , D + C 2 where C = q π ln 2 2 . The first approximation, 1 ≈ , reflects the Gaussian ap- pro ximation to the posterior. The integral in the left hand side of Eqn. (4) is in tractable. By p erforming a T a ylor expansion on ln h(Φ( f x )) (see supplemen tary material) we can see that it can be approximated up to O ( f 4 x ) by a squared exp onen tial curve, exp ( − f 2 x /π ln 2). W e will refer to this appro ximation as 2 ≈ . No w w e can apply the standard con volution formula for Gaussians to finally get a closed form expression for b oth terms of Eqn. (2). Fig. 1 depicts the striking accuracy of this simple approximation. The max- im um possible error that will b e incurred when using this approximation is if N ( f x | µ x , D , σ 2 x , D ) is centred at µ x , D = ± 2 . 05 with σ 2 x , D tending to zero (see Fig. 1, absolute error ), yielding only a 0.27% error in the integral in Eqn. (4) . The authors are unaw are of previous use of this simple and useful approximation in this con text. In Section 5 we inv estigate exp erimentally the information lost from approximations 1 ≈ and 2 ≈ as compared to the golden standard of extensiv e Mon te Carlo simulation. T o summarise, the BALD algorithm for Gaussian pro cess classification con- sists of t wo steps. First it applies an y standard approximate inference algorithm for GPCs (such as EP) to obtain the p osterior predictive mean µ x , D and σ x , D for eac h point of interest x . Then, it selects a query x that maximises the following ob jective function: h Φ µ x , D q σ 2 x , D + 1 − C exp − µ 2 x , D 2 ( σ 2 x , D + C 2 ) q σ 2 x , D + C 2 (5) 5 − 5 0 5 0 1 h (Φ( · )) exp( − t 2 π log(2) ) 0 5 · 10 − 3 difference Figure 1: Analytic approximation ( 1 ≈ ) to the binary en tropy of the error function ( ) by a squared exp onen tial ( ). The absolute error ( ) remains under 3 · 10 − 3 . F or most practically relev ant k ernels, the ob jectiv e (5) is a smo oth and differen tiable function of x , so gradien t-based optimisation procedures can b e used to find the maximally informative query . 3.1 Extension: Learning Hyp erparameters In many applications the parameter set θ naturally divides in to parameters of in terest, θ + , and n uisance parameters θ − , i.e. θ = { θ + , θ − } . In such settings, the active learning ma y w ant to query p oints that are maximally informativ e ab out θ + , while not caring ab out θ − . By integrating Eqn. (1) o ver the n uisance parameters, θ − , BALD’s ob jective is re-derived as: H E p ( θ + , θ − |D ) y | x , θ + , θ − − E p ( θ + |D ) H E p ( θ − | θ + , D ) [ y | x , θ + , θ − ] (6) In the con text of GP mo dels, hyperparameters t ypically con trol the smo oth- ness or spatial length-scale of functions. If we maintain a posterior distribution o ver these hyperparameters, whic h w e can do e. g. via Hamiltonian Monte Carlo, w e can c ho ose either to treat them as n uisance parameters θ − and use Eq. 6, or to include them in θ + and p erform active learning ov er them as w ell. In certain cases, suc h as automatic relev ance determination [ Rasm ussen and Williams, 2005 ], it ma y ev en mak e sense to treat h yp erparameters as v ariables of primary interest, and the function f itself as nuisance parameter θ − . 3.2 Preference Learning Our active learning framework for GPC can b e extended to the imp ortan t problem of preference learning [ F ¨ urnkranz and H¨ ullermeier, 2003 , Ch u and Ghahramani, 2005 ]. In preference learning the dataset consists for pairs of items ( u i , v i ) ∈ X 2 with binary lab els, y i ∈ { 0 , 1 } . y i = 1 means instance u i is preferred to v i , denoted u i v i . The task is to predict the preference relation b etw een an y ( u , v ). W e can view this as a special case of building a classifier on pairs of inputs 6 h : X 2 7→ { 0 , 1 } . [ Ch u and Ghahramani, 2005 ] prop ose a Ba yesian approach, using a latent preference function f , ov er which a GP prior is defined. The mo del predicts preference, u i v i whenev er f ( u i ) + u i > f ( v i ) + v i , where u i , v i denote additiv e Gaussian noise. Under this mo del, the lik eliho o d of f b ecomes: P [ y = 1 | ( u i , v i ) , f ] = P [ u i v i | f ] = Φ f ( u i ) − f ( v i ) √ 2 σ noise (7) By rescaling the laten t function f , it can b e assumed w.l.o.g. that √ 2 σ noise = 1. The likelihoo d only dep ends on the difference b etw een f ( u ) and f ( v ). W e therefore define g ( u , v ) = f ( u ) − f ( v ), and do inference entirely in terms of g , for which the likelihoo d b ecomes the same as for probit classification: y | u , v , f ∼ Bernoulli (Φ( g ( u , v ))). W e observ e that a GP prior is induced on g b ecause it is formed by p erforming a linear op eration on f , for which w e ha ve a GP prior already f ∼ GP (0 , k ). W e can derive the induced cov ariance function of g as (deriv ation in the Supplemen tary material) as: k pref (( u i , v i ) , ( u j , v j )) = k ( u i , u j ) + k ( v i , v j ) − k ( u i , v j ) − k ( v i , u j ). Note that this k ernel k pref resp ects the an ti-symmetry prop erties desired for a preference learning scenario, i.e. the v alue g ( u, v ) is perfectly an ti-correlated with g ( v , u ), ensuring P [ u v ] = 1 − P [ v u ] holds. Thus, we can co nclude that the GP preference learning framew ork of [ Ch u and Ghahramani, 2005 ], is equiv alen t to GPC with a particular class of kernels, that we ma y call the pr efer enc e judgement kernels . Therefore, our active learning algorithm presen ted in Section 3 for GPC can readily b e applied to pairwise preference learning also. 4 Related Metho dologies There are a num ber of closely related algorithms for activ e classification whic h w e no w review. The Informativ e V ector Machine (IVM): P erhaps the most closely re- lated approach is the IVM [ La wrence et al., 2003 ]. This popular,and successful approac h to activ e learning was designed specifically for GPs; it uses an infor- mation theoretic approac h and so appears v ery similar to BALD. The IVM algorithm was designed for subsampling a dataset for training a GP , so it is privy to the y v alues b efore including a measuremen t; it cannot therefore work explic- itly in output space i.e. with Eqn. (2) . The IVM uses Eqn. (1) , but parameter en tropies are calculated appro ximately in the marginal subspace corresp onding to the observed data p oin ts. The en trop y decrease after inclusion of a new data p oin t can then b e calculated efficiently using the GP cov ariance matrix. Although the IVM and BALD are motiv ated by the same ob jectiv e, they work fundamen tally differently when appro ximate inference is carried out. At an y time 7 b oth metho ds ha ve an appro ximate p osterior q t ( θ |D ), this can b e up dated with the likelihoo d of a new data p oint p ( y t +1 | f , x t +1 ), yielding ˆ p t +1 ( θ |D , x t +1 , y t +1 ) = 1 Z q t ( θ |D ) p ( y t +1 | f , x t +1 ). If the p osterior at t + 1 is appro ximated directly one gets q t +1 ( θ |D , x t +1 , y t +1 ). BALD calculates the en tropy difference b etw een q t and ˆ p t +1 , without having to compute q t +1 for each candidate x . In contrast, the IVM calculates the entrop y change b etw een q t and q t +1 . The IVM’s ap- proac h cannot calculate the entrop y of the full infinite dimensional p osterior, and requires O ( N x N y ) posterior up dates. T o do these updates efficien tly , ap- pro ximate inference is p erformed using Assumed Density Filtering (ADF). Using ADF means that q t +1 is a direct approximation to ˆ p t +1 , indicating that the IVM makes a further approximation to BALD. Since BALD only requires O (1) p osterior up dates it can afford to use more accurate, iterativ e procedures, suc h as EP . Information Theoretic approaches: Maxim um En tropy Sampling (MES) [ Sebastiani and Wynn, 2000 ] explicitly w orks in dataspace (Eqn. (2) ). MES w as prop osed for regression mo dels with input-indep enden t observ ation noise. Al- though Eqn. (2) is used, the second term is constan t because of input independent noise and is ignored. One cannot, ho wev er, use MES for heteroscedastic re- gression or classification; it fails to differen tiate betw een mo del uncertain ty and observ ation uncertaint y (ab out which our model ma y b e confident). Some toy demonstrations sho w this ‘information based’ activ e learning criterion p erforming pathologically in classification by rep eatedly querying points close the decision b oundary or in regions of high observ ation uncertaint y e.g. [ Huang et al., 2010 ]. This is b ecause MES is inappropriate in this domain; BALD distinguishes be- t ween observ ation and mo del uncertain ty and eliminates these problems as we will show. Mutual-information based ob jectiv e functions are presented in [ Ertin et al., , F uhrmann, 2003 ]. They maximise the m utual information b etw een the v ariable b eing measured and the v ariable of in terest. F uhrmann [ F uhrmann, 2003 ] applies this to linear Gaussian mo dels and acoustic arrays, Ertin et al. [ Ertin et al., ] to a com m unications c hannel. Although related, these ob jectives do not work with the model parameters and are not applied to classification. [ Guestrin et al., 2005 , Krause et al., 2006 ] also use mutual information. They sp ecify interest p oin ts in adv ance and maximise the expected m utual information b et ween the predictiv e distributions at these p oin ts and at the observ ed lo cations. Although this is a ob jectiv e is promising for regression, it is not tractable for models with input-dep enden t observ ation noise, such as classification or preference learning. Decision theoretic: W e briefly men tion decision theoretic approac hes to ac- tiv e learning. Two closely related algorithms, [ Kap oor et al., 2007 , Zh u et al., 2003 ], seek to minimize the exp ected cost i.e. loss weigh ted misclassification probability on all seen and future data. These metho ds observ e the lo cations of the test p oin ts and their ob jective functions become monotonic in the predictiv e entropies at the test points. [ Kap oor et al., 2007 ] also includes an empirical error term 8 MCMC EP ( 1 ≈ ) Laplace ( 1 ≈ ) MC 0 7 . 51 ± 2 . 51 41 . 57 ± 4 . 02 2 ≈ 0 . 16 ± 0 . 05 7 . 43 ± 2 . 40 40 . 45 ± 3 . 67 Figure 2: Percen tage approximation error ( ± 1 s.d.) for different metho ds of appro ximate inference ( c olumns ) and approximation methods for ev aluating Eqn. (4) ( r ows ). The results indicate that 2 ≈ is a v ery accurate appro ximation; EP causes some loss and Laplace significan tly more, which is in line with the comparison presented in [ Kuss and Rasm ussen, 2005 ]. F or our exp eriments w e use EP . that can yield pathological b ehaviour (w e inv estigate this exp erimentally). These approac hes are computationally expensive, requiring O ( N x N y ) posterior up dates. Also, they m ust kno w the locations of the test data (and th us are transductiv e approac hes); designing an inductiv e, decision-theoretic algorithm is an op en, hard problem as it would require exp ensive in tegration o ver p ossible test data distributions. Non-probabilistic Some non-probabilistic methods hav e close analogues to information theoretic activ e learning. Perhaps the most ubiquitous is active learning for SVMs [ T ong and Koller, 2001 , Seung et al., 1992 ], where the volume of V ersion Space (VS) is used as a pro xy for the posterior en tropy . If a uniform (improp er) prior is used with a deterministic classification likelihoo d, the log v olume of VS and Ba yesian p osterior entrop y are in fact equiv alent. Just as Ba yesian p osteriors b ecome in tractable after observing many data p oints, VS can b ecome complicated. [ T ong and Koller, 2001 ] prop oses methods for approximat- ing VS with a simple shap es, such as hyperspheres (their simplest approximation reduces to margin sampling). This closely resembles approximating a Ba yesian p osterior using a G aussian distribution via the Laplace or EP approximations. [ Seung et al., 1992 ] sidesteps the problem b y working with predictions. The al- gorithm, Query by Committee (QBC), samples parameters from VS (committee mem b ers), they v ote on the outcome of eac h p ossible x . The x with the most balanced v ote is selected; this is termed the ‘principle of maximal disagreemen t’. If BALD is used with a sampled p osterior, query b y committee is implemented but with a probabilistic measure of disagreement. QBC’s deterministic v ote criterion discards confidence in the predictions and so can exhibit the same pathologies as MES. 5 Exp erimen ts Quan tifying Approximation Losses: T o obtain (5) w e made tw o appro x- imations: we perform approximate inference ( 1 ≈ ), and w e approximated the binary en tropy of the Gaussian CDF by a squared exponential ( 2 ≈ ). Both of these can be substituted with Mon te Carlo sampling, enabling us to compute 9 Dim. 1 Dim. 2 (a) blo ck in the middle Dim. 1 Dim. 2 (b) blo ck in the corner Dim. 1 Dim. 2 (c) chec kerboard 0 20 40 0 . 5 0 . 9 No. queried p oints Accuracy 0 25 50 0 . 5 1 No. queried p oints Accuracy 0 25 50 0 . 5 1 No. queried p oints Accuracy Figure 3: T op: Ev aluation on artificial datasets. Exemplars of the tw o classes are shown with blac k squares ( ) and red circles ( ). Bottom: Results of active learning with nine methods: random query ( ), BALD( ), MES ( ), QBC with the vote criterion with 2 ( ) and 100 ( ) committee mem b ers, activ e SVM ( ), IVM ( ), decision theoretic: [ Kap oor et al., 2007 ] ( ), [Zh u et al., 2003] ( ) and empirical error ( ). an asymptotically unbiased estimate of the expected information gain. Using extensiv e Mon te Carlo as the ‘gold standard’, we can ev aluate how m uch w e lo ose by applying these appro ximations. W e quantify approximation error as: max x ∈P I ( x ) − I (arg max x ∈P ˆ I ( x )) max x ∈P I ( x ) · 100% (8) where I is the ob jective computed using Monte Carlo, ˆ I is the appro ximate ob jective. The c anc er UCI dataset was used, results and discussion are in Fig. 2. P o ol based activ e learning: W e test BALDfor GPC and preference learning in the po ol-based setting i.e. selecting x v alues from a fixed set of data-points. Although BALD can generalise to selecting contin uous x , this enables us to compare to algorithms that cannot. W e compare to eight other algorithms: random sampling, MES, QBC (with 2 and 100 committee mem b ers), SVM with version space appro ximation [ T ong and Koller, 2001 ], decision theoretic approac hes in [ Kap oor et al., 2007 , Zh u et al., 2003 ] and directly minimizing 10 0 20 40 0 . 5 1 No. queried p oints Accuracy (a) crabs 0 50 100 0 . 5 1 No. queried p oints Accuracy (b) vehicle 0 30 60 0 . 6 1 No. queried p oints Accuracy (c) wine 0 25 50 0 . 6 1 No. queried p oints Accuracy (d) wdb c 0 50 100 0 . 5 1 No. queried p oints Accuracy (e) isolet 0 50 0 . 5 0 . 75 No. queried p oints Accuracy (f ) austra 0 30 60 0 . 7 1 No. queried p oints Accuracy (g) letter D vs. P 0 50 100 0 . 7 1 No. queried p oints Accuracy (h) letter E vs. F 0 50 0 . 5 0 . 75 No. queried p oints Accuracy (j) cancer 0 100 200 0 . 5 0 . 6 No. queried p oints Accuracy (j) pref: kinematics 0 30 60 0 . 6 1 No. queried p oints Accuracy (k) pref: cart 0 150 300 0 . 55 0 . 7 No. queried p oints Accuracy (l) pref: cpu Figure 4: T est set classification accuracy on classification and preference learning datasets. Metho ds used are BALD( ), random query ( ), MES ( ), QBC with 2 ( QBC 2 , ) and 100 ( QBC 100 , ) committee mem b ers, activ e SVM ( ), IVM ( ), decision theoretic [ Kap oor et al., 2007 ] ( ), deci- sion theoretic [ Zh u et al., 2003 ] ( ) and empicial error ( ). The decision theoretic metho ds to ok a long time to run, so were not completed for all datasets. Plots (a-i) are GPC datasets, (j-l) are preference learning. . 11 0 50 100 BALD Rand IVM MES QBC2 QBC100 SVM Kap oor Zh u et al. Empirical Figure 5: Summary of results for all classification exp eriments. y -axis denotes the num b er of additional data points, relative to BALD, required to achiev e at least 97 . 5% of the predictive p erformance of the entire p o ol. The ‘b o x’ denotes 25th to 75th p ercen tile, the red line denotes the median ov er datasets, and the ‘whisk ers’ depict the range. The crosses denote outliers ( > 2 . 7 σ from the mean). P ositive v alues mean that the algorithm required more data points than BALD to achiev e the same p erformance. exp ected empirical error (the last is not a widely used method, but is included for analysis of [Kap o or et al., 2007]). W e consider three artificial, but c hallenging, datasets. The first of whic h, blo ck in the midd le , has a block of noisy p oints on the decision b oundary , the second blo ck in the c orner , has a blo ck of uninformative p oints far from the decision b oundary: a strong active learning algorithm should a void these uninformativ e regions. The third is similar to the che ckerb o ar d dataset in [ Zh u et al., 2003 ], and is designed to test the algorithm’s capabilities to find multiple disjoint islands of p oints from one class. The three datasets and results using each algorithm are depicted in Fig. 3. Results are also presen ted on eight UCI classification datasets austr alia, cr abs, vehicle, isolet, c anc er, wine, wdb c and letter . L etter is a m ulticlass dataset for whic h w e select hard-to-distinguish letters E vs. F and D vs. P . F or preference learning we use the cpu, c art and kinematics regression datasets 1 pro cessed to yield a preference task as describ ed in [ Ch u and Ghahramani, 2005 ]. Results are plotted in Fig. 4, and Fig. 5 depicts an aggregation of the results. Discussion: Figs. 3 and 4 sho w that by using BALDw e mak e significan t gains o ver naive random sampling in both the classification and preference learning domains. Relative to other activ e learning algorithms BALDis consisten tly the 1 http://www.liacc.up.pt/ ltorgo/Regression/DataSets.html 12 b est, or amongst the b est p erforming algorithms on all datasets. On any individ- ual dataset BALD’s performance is often matched b ecause we compare to many metho ds, and the more approximate algorithms can hav e go o d p erformance under different conditions. Fig. 5 rev eals that BALD has the b est ov erall perfor- mance; on av erage, all other metho ds require more data p oints to ac hieve the same classification accuracy . Zhu et al. ’s decision theoretic approac h is closest, the median increase in the num ber of data p oints required is 1 . 4 and zero (i.e. equiv alen t to BALD) is within the inter-quartile range. This algorithm, ho wev er, requires m uch more computational time and has access to the full set of test inputs, which BALD does not hav e. MES and QBC app ear close in p erformance to BALD, but the zero line falls outside b oth of their inter-quartile ranges. As exp ected, MES p erforms p o orly on the noisy dataset (Fig. 3(a)) because it discards knowledge of observ ation noise. When there is zero observ ation noise it is equiv alent to BALD e.g. Fig. 3(c). On many of the real-world datasets MES p erforms as w ell as BALD e.g. Fig. 4(b, e), indicating that these datasets are mostly noise-free. The IVM performs w ell on Fig. 3(c), but pathologically on 3(a); this is due to the fact that it biases selection tow ards p oints from only one class in the noisy cluster, reducing the p osterior entrop y rapidly but artificially . Ho wev er, it also p erforms significantly worse than BALD on noise-free (indicated by MES’s strong p erformance) datasets e.g. Fig. 4(b). This implies that the IVM’s p osterior approximation or the ADF up date are detrimental to the algorithm’s p erformance. QBC often yields only a small decrement in p erformance, the sampling appro ximation is often not too detrimen tal. How ev er, it p erforms po orly on the noisy artificial dataset (Fig. 3(a)) b ecause the vote criterion is not main taining a notion of inheren t uncertain ty , like MES. The SVM-based approach exhibits v ariable p erformance (it do es w ell on Fig. 4(d), but v ery p o orly on 4(f )). The p erformance is greatly effected by the appro ximation used, for consistency w e presen t here one that yielded the most consistent go o d p erformance. Decision theoretic approac hes sometimes perform w ell, on 3(c) they choose the first 16 p oin ts from the cen tre of eac h cluster as they are influenced by the surrounding unlab elled points. BALDdo es not observ e the unlab elled p oints so ma y not pick p oints from the centres. Fig. 5 rev eals that BALD is performing as well as the metho d in [ Zh u et al., 2003 ], and outp erforms the approach in [ Kap oor et al., 2007 ], despite not having access to the locations of the test p oin ts and ha ving a significantly lo wer computational cost. The ob jective in [ Kap oor et al., 2007 ] can fail, this is b ecause one term in their ob jectiv e function is the empirical error. The weigh t given to this term is determined by the relativ e sizes of the training and test set (and the asso ciated losses). Directly minimizing empirical error usually p erforms v ery pathologically , pic king only ‘safe’ points. When the method in [ Kap oor et al., 2007 ] assigns too m uch weigh t to this term, it can fail also. Finally we note that BALD may o ccasionally perform po orly on the first few data p oin ts (e.g. Fig. 4(l)). This is may be because the h yp erparameters are fixed throughout the exp eriments to pro vide a fair comparison to algorithms 13 incapable of incorp orating hyperparameter learning. This ma y mean that given little data the GP model ov erfits, leading to BALD selecting abnormal query lo cations. Maintaining a distribution ov er hyperparameters can b e done using MCMC, although this significantly increases computational time. Designing a general metho d to do this efficiently is a sub ject of further w ork. In practice, a simple heuristic suc h as pic king the first few points randomly , and optimising h yp erparameters will usually suffice. 6 Conclusions W e ha ve demonstrated a method that applies the full information theoretic activ e learning criterion to GP classification that makes, as far as the authors are aw are, the smallest n umber of approximations to date, and has as goo d computational complexit y . W e extend the GPC model to develop a new preference learning k ernel, which enables us to apply our active learning algorithm directly to this domain also. The metho d can handle naturally active learning of k ernel h yp erparameters, which is a hard, mostly unsolved problem, for example in SVM active learning. One notable feature of our approac h is that it is agnostic to the appro ximate inference metho ds used. This allows us to choose from a whole range of approximate inference methods, including EP , the Laplace appro ximation, ADF or even sparse online learning, and thereby make the trade off b etw een computational complexity and accuracy . Our exp erimental p erformance compares fav ourably to many other activ e learning methods for classification, and ev en decision theoretic metho ds that ha ve access to the test data and require muc h greater computational time. References [Bernardo, 1979] Bernardo, J. (1979). Exp ected information as expected utility. The A nnals of Statistics , 7(3):686–690. [Ch u and Ghahramani, 2005] Ch u, W. and Ghahramani, Z. (2005). Preference learning with Gaussian pro cesses. In ICML , pages 137–144. ACM. [Co ver et al., 1991] Co ver, T., Thomas, J., and Wiley , J. (1991). Elements of information the ory , volume 6. Wiley Online Library . [Dasgupta, 2005] Dasgupta, S. (2005). Analysis of a greedy activ e learning strategy . In NIPS . [Ertin et al., ] Ertin, E., Fisher, J., and P otter, L. Maxim um m utual information principle for dynamic se nsor query problems. In Information Pr o c essing in Sensor Networks , Lecture Notes in Computer Science. [F uhrmann, 2003] F uhrmann, D. (2003). A ctive T esting Surveil lanc e Systems, or, Playing Twenty Questions with a R adar . Defense T echnical Information Cen ter. 14 [F ¨ urnkranz and H¨ ullermeier, 2003] F ¨ urnkranz, J. and H¨ ullermeier, E. (2003). P airwise preference learning and ranking. Machine L e arning: ECML 2003 , pages 145–156. [Golo vin and Krause, 2010] Golo vin, D. and Krause, A. (2010). Adaptive sub- mo dularit y: A new approach to activ e learning and stochastic optimization. In COL T . [Guestrin et al., 2005] Guestrin, C., Krause, A., and Singh, A. P . (2005). Near- optimal sensor placemen ts in Gaussian processes. In Pr o c e e dings of the 22nd international c onfer enc e on Machine le arning , ICML ’05, pages 265–272, New Y ork, NY, USA. ACM. [Hec kerman et al., 1995] Hec kerman, D., Breese, J., and Rommelse, K. (1995). T roublesho oting under uncertain ty . Communic ations of the A CM , 38(3):27–41. [Huang et al., 2010] Huang, S., Jin, R., and Zhou, Z. (2010). Active learning b y querying informative and representativ e examples. A dvanc es in neur al information pr o c essing systems , 23:892–900. [Kap oor et al., 2007] Kap oor, A., Horvitz, E., and Basu, S. (2007). Selectiv e su- p ervision: Guiding supervised learning with decision-theoretic activ e learning. In IJCAI . [Krause et al., 2006] Krause, A., Guestrin, C., Gupta, A., and Klein b erg, J. (2006). Near-optimal sensor placements: Maximizing information while mini- mizing comm unication cost. In Pr o c e e dings of the 5th international c onfer enc e on Information pr o c essing in sensor networks , pages 2–10. A CM. [Krishnapuram et al., ] Krishnapuram, B., Williams, D., Xue, Y., Hartemink, A., Carin, L., and Figueiredo, M. On semi-supervised classification. NIPS . [Kuss and Rasm ussen, 2005] Kuss, M. and Rasmussen, C. E. (2005). Assesing appro ximations for gaussian process classification. In NIPS . MIT Press. [La wrence et al., 2003] La wrence, N., Seeger, M., and Herbrich, R. (2003). F ast sparse Gaussian Pro cess methods: The informativ e v ector mac hine. A dvanc es in neur al information pr o c essing systems , pages 625–632. [Lindley , 1956] Lindley , D. (1956). On a measure of the information pro vided b y an exp eriment. The A nnals of Mathematic al Statistics , 27(4):986–1005. [MacKa y , 1992] MacKa y , D. (1992). Information-based ob jective functions for activ e data selection. Neur al c omputation , 4(4):590–604. [P anzeri and Petersen, 2007] P anzeri, S., S. R. M. M. and P etersen, R. (2007). Correcting for the sampling bias problem in spik e train information measures. Journal of neur ophysiolo gy , 98(3):1064. [Rasm ussen and Williams, 2005] Rasm ussen, C. and Williams, C. (2005). Gaus- sian Pr o c esses for Machine L e arning . The MIT Press. 15 [Ro y and McCallum, 2001] Ro y , N. and McCallum, A. (2001). T ow ard optimal activ e learning through sampling estimation of error reduction. In ICML , pages 441–448. [Sebastiani and Wynn, 2000] Sebastiani, P . and Wynn, H. (2000). Maximum en tropy sampling and optimal Bay esian exp erimental design. Journal of the R oyal Statistic al So ciety: Series B (Statistic al Metho dolo gy) , 62(1):145–157. [Seung et al., 1992] Seung, H., Opper, M., and Somp olinsky , H. (1992). Query b y committee. In COL T , pages 287–294. ACM. [T ong and Koller, 2001] T ong, S. and Koller, D. (2001). Support v ector machine activ e learning with applications to text classification. Journal of Machine L e arning R ese ar ch , 2:45–66. [Zh u et al., 2003] Zh u, X., Ghahramani, Z., and Laffert y , J. (2003). Combining activ e learning and semi-sup ervised learning using Gaussian fields and har- monic functions. ICML 2003 workshop on The Continuum fr om L ab ele d to Unlab ele d Data in Machine L e arning and Data Mining . 16 APPENDIX – SUPPLEMENT AR Y MA TERIAL T a ylor Expansion for Appro ximation 2 ≈ W e p erform a T aylor expansion on ln H[Φ( x )] as follo ws: f ( x ) = f (0) + f 0 (0) x 1! + f 00 (0) x 2 2! + . . . f ( x ) = ln H[Φ( x )] f 0 ( x ) = − 1 ln 2 Φ 0 ( x ) H[Φ( x )] [ln Φ( x ) − ln(1 − Φ( x ))] f 00 ( x ) = 1 ln 2 Φ 0 ( x ) 2 H[Φ( x )] 2 [ln Φ( x ) − ln(1 − Φ( x ))] − 1 ln 2 Φ 00 ( x ) H[Φ( x )] [ln Φ( x ) − ln(1 − Φ( x ))] − 1 ln 2 Φ 0 ( x ) 2 H[Φ( x )] 1 Φ( x ) + 1 (1 − Φ( x ) ) ∴ ln H[Φ( x )] = 1 − 1 π ln 2 x 2 + O ( x 4 ) Because the function is ev en, we can insp ect that the x 3 term will be zero. Therefore, exp onentiating, we make the appro ximation up to O ( x 4 ): H[Φ( x )] 2 ≈ exp − x 2 π ln 2 Preference Kernel The mean µ pref , and cov ariance function k pref of the GP ov er g can b e computed from the mean and co v ariance of f ∼ GP( µ, k ) as follo ws: k pref ([ u i , v i ] , [ u j , v j ]) = C ov [ g ( u i , v i ) , g ( u j , v j )] = C ov [( f ( u i ) − f ( v i )) , ( f ( u i ) − f ( v i ))] = E [( f ( u i ) − f ( v i )) · ( f ( u i ) − f ( v i ))] − ( µ ( u i ) − µ ( v i )) ( µ ( v j ) − µ ( u i )) = k ( u i , u j ) + k ( v i , v j ) − k ( u i , v j ) − k ( v i , u j ) (9) µ pref ([ u , v ]) = E [ g ([ u , v ])] = E [ f ( u ) − f ( v )] = µ ( u ) − µ ( v ) (10) 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment