High-Rank Matrix Completion and Subspace Clustering with Missing Data
This paper considers the problem of completing a matrix with many missing entries under the assumption that the columns of the matrix belong to a union of multiple low-rank subspaces. This generalizes the standard low-rank matrix completion problem t…
Authors: Brian Eriksson, Laura Balzano, Robert Nowak
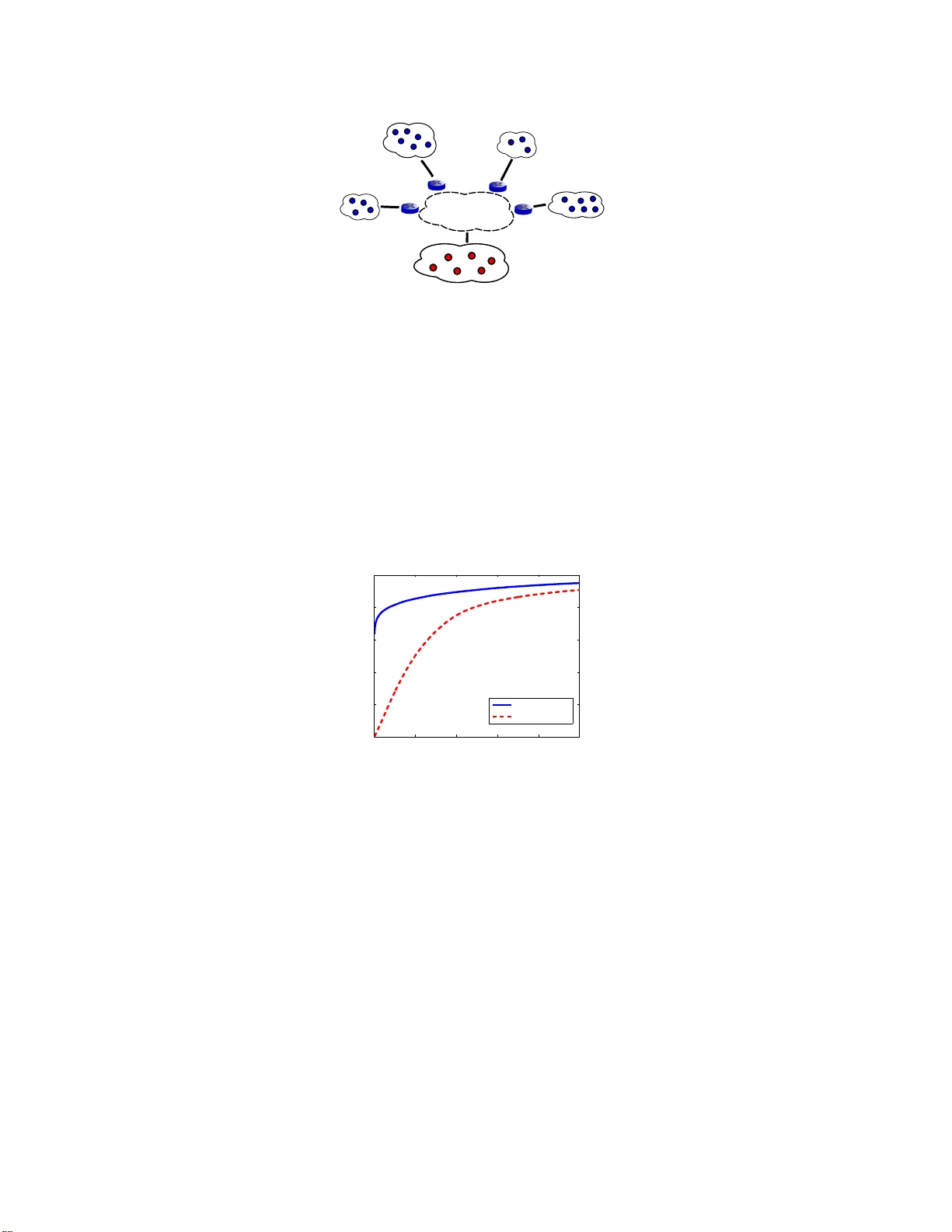
High-Ran k Matrix Comple tion and Subspace Clusterin g with Missing Data Brian Eriksson ∗ Boston Univ ersity and Univ ersity of W isconsin - Madison eriksson@cs.bu.edu Laura Balzano ∗ Univ ersity of W isconsin - Madison sunbeam@ece.wisc.edu Robert Now ak Univ ersity of W isconsin - Madison now ak@ece.wisc.edu December 2011 Abstract This paper considers the problem of completing a matrix with man y missing entries under the assumption that the columns o f the matrix belong t o a union of multiple lo w-rank subspaces. This generalizes the standard l ow-rank matrix completion problem to situations in which the matrix rank can be quite high or ev en full rank. Since the columns belong to a union of subspaces, this problem may also be vie wed as a missing-da ta version o f the subsp ace clustering problem. Let X be an n × N matrix wh ose (complete) colu mns lie in a u nion of at most k subspaces, each of rank ≤ r < n , a nd a ssume N ≫ kn . The main result of the paper sho ws that under mild assu mptions each column of X can be perfectly recovered with high probability from an i ncomplete version so long as at least C r N log 2 ( n ) entries of X are observe d uniformly at random, with C > 1 a con stant depending on the usual incoherence conditions, the geometrical arrangement o f subspaces, and the distribution of c olumns over the subspaces. The result is illustrated with numerical expe riments and an application to Internet distance matrix completion and topology identification. 1 Introd uction Consider a r eal-valued n × N dimen sional matrix X . Assume that the columns of X lie in the unio n of at mo st k subspaces o f R n , each having dimension at m ost r < n a nd assum e that N > k n . W e are e specially inte rested in “high -rank” situations in wh ich the to tal rank (the rank o f the un ion of the subspaces) may b e n . Our go al is to complete X based o n a n observation of a small rando m sub set of its entries. W e p ropose a novel meth od for this matrix co mpletion pro blem. In the app lications we have in mind N may be arbitrar ily large, and so we will f ocus on quantify ing the probab ility that a gi ven colum n i s perfectly completed, rather than the prob ability that whole matrix is perfectly completed ( i.e., every column is per fectly completed). Of course it is po ssible to translate between t hese two quantification s using a un ion bound, b ut that bound become s meaningless if N is extremely large. Suppose the en tries of X are o bserved un iformly at rand om with p robab ility p 0 . Let Ω denote th e set o f indices of obser ved entries a nd let X Ω denote the o bservations of X . Our main r esult shows that under a mild set of assump- tions ea ch colum n o f X can be perfectly rec overed from X Ω with h igh prob ability u sing a computatio nally efficient proced ure if p 0 ≥ C r n log 2 ( n ) (1) where C > 1 is a co nstant depen ding on th e usual incoh erence cond itions as well as the geo metrical arr angemen t of subspaces and the distribution of the columns in the s ubspaces. ∗ The first tw o authors contribut ed equall y to this paper . 1 1.1 Connections to Low-Rank Completion Low-rank matrix comp letion theo ry [1] shows th at an n × N matr ix of rank r can be recov ered from incom plete obser- vations, as lo ng as the nu mber of entries obser ved (with locatio ns sampled unifor mly at rand om) exceeds r N log 2 N (within a constan t factor and assuming n ≤ N ). It is also kn own that, in the same setting, com pletion is impossible if the number of observed entries is less than a constant times r N log N [2]. Th ese results imply that if the rank of X is close to n , then all of the entries are needed in order to determine the matrix. Here we co nsider a matrix whose column s lie in the un ion of at m ost k subsp aces of R n . Restrictin g th e ran k of each subspa ce to at most r , then the rank of the full matr ix our situation could be as large as k r , yielding the requir e- ment k r N log 2 N using current matrix completion theory . I n contrast, the bound in (1) i mplies that the comp letion of each column is po ssible from a constant times r N lo g 2 n entries sampled un iformly at rand om. Ex act co mpletion of ev ery column can be guaran teed by replacing log 2 n with log 2 N is this bound , b ut since we allow N to be very large we pr efer to state our result in terms of per-column completio n. Our m ethod, therefore, impr oves significantly upo n conv entional low-rank matrix completion, especially when k is large. This does not contradict the lo wer boun d in [2] , because the matrices we consider are not arb itrary high- rank m atrices, r ather the columns must belong to a unio n o f rank ≤ r subspaces. 1.2 Connections to Subspace Clustering Let x 1 , . . . , x N ∈ R n and assume each x i lies in one of at most k su bspaces of R n . Subspace clustering is the problem of learning the subspaces from { x i } N i =1 and assigning each vector to its pro per subspace; cf. [3] for a overview . This is a challenging problem, both in terms of com putation and inf erence, but provably p robably correct subspac e clustering algorithm s n ow exist [4, 5, 6 ]. Here we consider the p roblem of high rank ma trix comp le tio n , which is essentially equiv alent to subspace clustering with missing data. This prob lem has been looked at in previous works [7, 8], but to the be st of o ur knowledge our metho d and theoretica l bound s are novel. Note that our sampling p robab ility bound (1) requir es that o nly slightly more than r out o f n entries are ob served in each column , so the matrix m ay b e h ighly incomplete. 1.3 A Motiv ating Application There ar e many application s of subspace cluster ing, and it is reason able to suppo se that data m ay often be missing in high-d imensional problem s. One such ap plication is the Inter net distance m atrix com pletion and topo logy identifica- tion problem. Distances be tween networked devices can be mea sured in terms of hop-c ounts, the number of routers between th e devices. Infrastru ctures exist tha t reco rd distanc es from N en d host co mputer s to a set o f n monito ring points throughout the Internet. T he complete set of distances determines the network topology betwee n the compu ters and the mon itoring points [9]. These infr astructures are based entirely on passively mo nitoring of normal traffic. One advantage is the ability to monitor a very large portion of the In ternet, w hich is not po ssible using a cti ve pro bing methods due to the burden they place on networks. T he disadvantage of passive mon itoring is that measurements col- lected are b ased on norma l traf fic, which is no t specifically design ed or con trolled, therefore a sub set of the distanc es may not be observed. This p oses a matrix completio n problem, with the inco mplete distance matrix being p otentially full-rank in this application. Ho wever , computers tend to b e clustered within subnets having a small num ber of e gress (or access) po ints to the Inter net at la rge. The numb er of egress po ints in a subne t limits the rank o f the submatr ix of distances from computer s in th e subnet to the mo nitors. Therefo re the columns of the n × N distance matrix lie in the unio n of k low-rank subspaces, where k is the nu mber of subn ets. Th e solution to the matrix comp letion problem yields all the distances (and hence the topolog y) as well as the subn et clusters. 1.4 Related W ork The proo f o f the m ain result d raws on ideas from ma trix completio n theor y , sub space learning and detection with missing da ta, and subspace clu stering. One key ingred ient in our appro ach is the celebrated results on lo w-rank Matrix Completion [1, 2, 10]. Unfortu nately , in many real- world prob lems wh ere m issing data is p resent, par ticularly wh en the data is ge nerated from a union of subsp aces, these matrices can have very large rank values ( e .g., networking data in [11]). Thu s, the se prior results will require effecti vely all the elements be o bserved to accurately reconstru ct the matrix. 2 Our work builds upon the results of [1 2], which qu antifies the deviation o f an incom plete vector nor m with respect to the incoh erence of the samp ling pattern. While th is work also examines subspace detection using incom plete data, it assumes complete knowledge of the su bspaces. While r esearch th at examines subspace le arning h as be en pr esented in [13], the work in this paper differs by the concentr ation on learning from incomp lete ob servations ( i. e., when th ere are missing elements in the m atrix), and by the m ethodolo gical focus ( i.e., near est neig hbor clustering versus a mu ltiscale Singular V alue De composition approa ch). 1.5 Sket ch of Methodology The algorithm p roposed in this pap er in volves se veral relatively intuitive steps, outlin ed below . W e go into detail fo r each of these steps in following s ections. Local Ne ig hborhoods. A subset of colum ns of X Ω are selected uniform ly at random . The se are called seeds . A set of nearest neighbo rs is identified for each seed fro m th e rem ainder o f X Ω . In Sectio n 3 , w e show that nearest neighbo rs can b e reliab ly identified , even though a large portion of the data are missing, un der the usua l inco herence assumptions. Local Subspaces. T he subspace span ned by each seed an d its neigh borho od is ide ntified using matrix co mpletion . If matrix co mpletion fails ( i.e., if th e resulting matrix d oes n ot ag ree with the observed entries and/or the ran k o f the result is gr eater than r ), then the seed and its neig hborh ood ar e discarded. In Section 4 we show that when the numbe r of seeds an d th e neighbo rhood sizes are large en ough , then with high probability all k subspac es are iden tified. W e may also identify additio nal su bspaces which are un ions of the true subspaces, wh ich leads us to the next step. An example of these neighborho ods is shown in Figu re 1. Subspace Refinement. The set o f sub spaces obtained fro m the matrix co mpletions is pru ned to remove all but k subspaces. T he p runin g is acco mplished by simply discardin g a ll subspa ces that are sp anned by the un ion of two or more other subspaces. This can be done efficiently , as is shown in Section 5. Full Matrix Co mpletion. Each column in X Ω is a ssigned to its pro per subspace and com pleted b y p rojection on to that subspace , as d escribed in Section 6. Even wh en many ob servations are missing, it is possible to find the correc t subspace and the pro jection using r esults from subspace detectio n with missing data [1 2]. Th e resu lt o f th is step is a completed matrix b X such th at each column is correctly completed with high probability . The mathem atical analysis will be presented in the next f ew sections, organize d according to these steps. After proving the main result, experimental results are presented in the final section. Figure 1: Example of nearest-neighborho od selecting points on from a single subspace. For illustrati on, samples fr om three one- dimensional subspaces are depicted as small dots. The lar ge dot is the seed. The subset of sa mples with significan t o bserved support in common with that of the seed are depicted by ∗ ’ s. If the density of points is high enough, then the nearest neighbors we i dentify will belong to the same subspace as the seed. In this case we depict the ball containing the 3 nearest neighbors of the seed with significant support ov erlap. 3 2 K ey Ass umptions and Main Result The notion o f incoh erence plays a key ro le in matrix completion and sub space recovery from incomplete observations. Definition 1. The coherence of an r -dimen sional subspa ce S ⊆ R n is µ ( S ) := n r max j k P S e j k 2 2 wher e P S is the pr ojection o perator onto S and { e j } are the canonical u nit vectors for R n . Note that 1 ≤ µ ( S ) ≤ n/r . The coh erence o f single vector x ∈ R n is µ ( x ) = n k x k 2 ∞ k x k 2 2 , which is precisely the coheren ce of the one -dimension al subspace spanned by x . W ith this d efinition, we can s tate the main assumption s we make about the matrix X . A1. The colu mns o f X lie in the unio n o f at mo st k subsp aces, with k = o ( n d ) for some d > 0 . The subspaces are denoted by S 1 , . . . , S k and each has rank at most r < n . The ℓ 2 -norm of each column is ≤ 1 . A2. The coherence of e ach subspace is bound ed above by µ 0 . The coherence of each column is bound ed above by µ 1 and for any pair of columns, x 1 and x 2 , the coherence of x 1 − x 2 is also boun ded above by µ 1 . A3. The column s of X d o not lie in the intersection(s) of the subspaces with probability 1 , and if rank ( S i ) = r i , then any subset of r i columns f rom S i spans S i with probab ility 1 . Let 0 < ǫ 0 < 1 an d S i,ǫ 0 denote th e subset of points in S i at least ǫ 0 distance away fro m any oth er subspace. There exists a con stant 0 < ν 0 ≤ 1 , depe nding on ǫ 0 , such that (i) Th e probability that a column selected uniformly at random belongs to S i,ǫ 0 is at least ν 0 /k . (ii) If x ∈ S i,ǫ 0 , the n the p robability that a co lumn selected u niform ly at random b elongs to the ball o f radiu s ǫ 0 centered at x is at least ν 0 ǫ r 0 /k . The cond itions of A3 are met if, f or exam ple, th e columns ar e drawn f rom a mixture of continu ous distributions o n each of the subspa ces. The value of ν 0 depend s on the g eometrical arrang ement of the subspaces an d the distribution of the columns with in the subspaces. If the subspaces are not too close to each other, and the distributions within the subsp aces are fairly u niform , then typically ν 0 will be n ot too close to 0 . W e d efine th ree key qu antities, the confidenc e pa rameter δ 0 , the r equired numb er of “seed” c olumns s 0 , and a quantity ℓ 0 related to the neig hbor hood formation process (see Algorithm 1 in Section 3): δ 0 := n 2 − 2 β 1 / 2 log n , for some β > 1 , (2) s 0 := k (log k + log 1 / δ 0 ) (1 − e − 4 ) ν 0 , ℓ 0 := & max ( 2 k ν 0 ( ǫ 0 √ 3 ) r , 8 k log ( s 0 /δ 0 ) nν 0 ( ǫ 0 √ 3 ) r )' . W e can now state the main result of the paper . Theorem 2.1 . Let X b e an n × N ma trix satisfying A1 - A3 . Su p pose that each entry of X is o bserved ind epende ntly with p r oba b ility p 0 . If p 0 ≥ 128 β ma x { µ 2 1 , µ 0 } ν 0 r log 2 ( n ) n and N ≥ ℓ 0 n (2 δ − 1 0 s 0 ℓ 0 n ) µ 2 0 log p − 1 0 then each column of X can be p e rfectly recover ed with p r oba bility at least 1 − (6 + 15 s 0 ) δ 0 , u sing the meth odology sketched a bove (and d etailed later in the p aper). 4 The requiremen ts o n sam pling are essentially the same as those for stand ard lo w-rank ma trix c ompletion , ap art from r equireme nt th at the total n umber of column s N is sufficiently la rge. T his is nee ded to ensure th at each of the subspaces is suf ficiently represented in th e matrix. The requirem ent o n N is poly nomial in n for fixed p 0 , which is easy to see based on the definitions of δ 0 , s 0 , and ℓ 0 (see further discussion at the end of Section 3). Perfect recovery of each column is g uaranteed with probability that decreases linearly in s 0 , which itself is linear in k (ign oring log factors). This is expected sinc e this proble m is mo re difficult than k in dividual lo w-rank matr ix completion s. W e state our re sults in term s of a pe r-column (rather than full matrix ) recovery gu arantee. A full matrix recovery guaran tee can be given by replacing log 2 n with log 2 N . This is evident fro m the final c ompletion step discussed in Le mma 8, below . Howev er , since N may be qu ite large (perhap s arbitrarily large) in the application s we en vision, we chose to state our results in terms of a per -colum n gu arantee. The details of the metho dolog y and lem mas leading to the theo rem above are developed in th e subsequen t sections following the four steps of the method ology ou tlined ab ove. In cer tain cases it will be more c onv enient to con sider sampling the loc ations of obser ved entries uniformly at rand om with replacement rath er than without rep lacement, as assumed above. The following lemm a will be useful f or translatin g bou nds derived assuming sampling with replace- ment to our situation (the same sort of relation is noted in Proposition 3.1 in [1]). Lemma 1. Draw m samples ind epend e ntly and uniformly fr om { 1 , . . . , n } and let Ω ′ denote th e resulting subset o f unique values. Let Ω m be a sub set of size m selected uniformly a t random fr o m { 1 , . . . , n } . Let E deno te an event depend ing on a rand o m subset of { 1 , . . . , n } . I f P ( E (Ω m )) is a n on-increasing function o f m , the n P ( E (Ω ′ )) ≥ P ( E (Ω m )) . Pr oof. For k = 1 , . . . , m , let Ω k denote a su bset of size k sampled unifor mly at random fr om { 1 , . . . , n } , an d let m ′ = | Ω ′ | . P ( E (Ω ′ )) = m X k =0 P ( E (Ω ′ ) | m ′ = k ) P ( m ′ = k ) = m X k =0 P ( E (Ω k )) P ( m ′ = k ) ≥ P ( E (Ω m )) m X k =0 P ( m ′ = k ) . 3 Local Neighborhoods In this first step, s colu mns of X Ω are selected uniform ly at r andom and a set of “n earby” column s are identified fo r each, co nstituting a lo cal n eighbor hood of size n . All bo unds that ho ld ar e designed with pr obability at least 1 − δ 0 , where δ 0 is defined in (2) above. The s columns are called “seeds. ” The requ ired size of s is determin ed as follo ws. Lemma 2 . A ssume A3 holds. If the n umber o f chosen seeds, s ≥ k (log k + log 1 / δ 0 ) (1 − e − 4 ) ν 0 , then with pr obab ility greater tha n 1 − δ 0 for each i = 1 , . . . , k , at least one seed is in S i,ǫ 0 and each seed column has at least η 0 := 64 β max { µ 2 1 , µ 0 } ν 0 r log 2 ( n ) (3) observed entries. Pr oof. First no te that from Theorem 2.1, the expected num ber of observed entries pe r column is at least η = 128 β ma x { µ 2 1 , µ 0 } ν 0 r log 2 ( n ) 5 Therefo re, the numb er of observed e ntries b η in a column selected un iformly at rando m is pr obably no t significantly less. More precisely , by Chernoff ’ s bo und we ha ve P ( b η ≤ η / 2 ) ≤ exp( − η / 8 ) < e − 4 . Combining this with A3 , we have the pro bability that a rando mly selected colu mn belong s to S i,ǫ 0 and has η / 2 or more observed entries is at least ν ′ 0 /k , wh ere ν ′ 0 := (1 − e − 4 ) ν 0 . Th en, the pro bability that the set of s columns does not con tain a column from S i,ǫ 0 with at least η / 2 observed entries is less than (1 − ν ′ 0 /k ) s . The probability th at the set does not con tain at least one column from S i,ǫ 0 with η / 2 or m ore observed entries, for i = 1 , . . . , k is le ss than δ 0 = k (1 − ν ′ 0 /k ) s . Solving for s in term s of δ 0 yields s = log k + log 1 /δ 0 log k/ν ′ 0 k/ν ′ 0 − 1 The result follows by noting that log( x/ ( x − 1)) ≥ 1 /x, for x > 1 . Next, for each seed we mu st find a set of n column s from the same subspace as the seed. This will be ac complished by iden tifying colu mns th at are ǫ 0 -close to the seed , so that if the seed belongs to S i,ǫ 0 , the column s must belo ng to the same sub space. Clear ly the total numb er of columns N must be sufficiently large so that n or more such column s can be found . W e will r eturn to the requiremen t on N a bit later , after first dealing with the following challeng e. Since th e column s are only partially observed, it may not be p ossible to determin e how close each is to the seed. W e addr ess this by showing that if a colum n and the seed are both ob served on en ough common indices, then th e incohere nce as sumption A2 allows us reliably estimate the distance. Lemma 3. Assume A2 and let y = x 1 − x 2 , wher e x 1 and x 2 ar e two co lu mns of X . Assume ther e is a commo n set of indices of size q ≤ n wher e b oth x 1 and x 2 ar e observed. Let ω denote this common set of indices and let y ω denote the corresponding su b set of y . Then fo r any δ 0 > 0 , if the n umber of commonly ob served elements q ≥ 8 µ 2 1 log(2 /δ 0 ) , then with pr ob ability at lea st 1 − δ 0 1 2 k y k 2 2 ≤ n q k y ω k 2 2 ≤ 3 2 k y k 2 2 . Pr oof. Note that k y ω k 2 2 is the sum of q rando m variables drawn uniform ly at rando m witho ut replacem ent from the set { y 2 1 , y 2 2 , . . . , y 2 n } , and E k y ω k 2 2 = q n k y k 2 2 . W e will prove the bou nd under the assump tion that, instead, the q variables are sampled with rep lacement, so that they are independ ent. By Lemm a 1, this will provide the desired result. Note that if one variable in the sum k y ω k 2 2 is replaced with ano ther v alu e, then the sum changes in value by at most 2 k y k 2 ∞ . Therefo re, McDiramid’ s Inequality sho ws that for t > 0 P k y ω k 2 2 − q n k y k 2 2 ≥ t ≤ 2 exp − t 2 2 q k y k 4 ∞ , or equiv alently P n q k y ω k 2 2 − k y k 2 2 ≥ t ≤ 2 exp − q t 2 2 n 2 k y k 4 ∞ . Assumption A2 implies th at n 2 k y k 4 ∞ ≤ µ 2 1 k y k 4 2 , and so we hav e P n q k y ω k 2 2 − k y k 2 2 ≥ t ≤ 2 exp − q t 2 2 µ 2 1 k y k 4 2 . T aking t = 1 2 k y k 2 2 yields the result. Suppose that x 1 ∈ S i,ǫ 0 (for som e i ) an d that x 2 6∈ S i , an d that both x 1 , x 2 observe q ≥ 2 µ 2 0 log(2 /δ 0 ) common indices. Let y ω denote the difference between x 1 and x 2 on the co mmon supp ort set. If the partial distan c e n q k y ω k 2 2 ≤ ǫ 2 0 / 2 , then the result above implies that with pro bability at least 1 − δ 0 k x 1 − x 2 k 2 2 ≤ 2 n q k y ω k 2 2 ≤ ǫ 2 0 . 6 On the other hand if x 2 ∈ S i and k x 1 − x 2 k 2 2 ≤ ǫ 2 0 / 3 , then with probability at least 1 − δ 0 n q k y ω k 2 2 ≤ 3 2 k x 1 − x 2 k 2 2 ≤ ǫ 2 0 / 2 . Using these results we will proceed as follo ws. For each seed we find all columns th at have at least t 0 > 2 µ 2 0 log(2 /δ 0 ) observations at indices in common with the seed (the prec ise value o f t 0 will be specified in a mo ment). Assuming that this set is sufficiently large, we will select ℓn these columns unif ormly at ran dom, f or some integer ℓ ≥ 1 . In particular, ℓ will be c hosen so that with high probability at least n of the colu mns will be within ǫ 0 / √ 3 o f th e seed , ensuring that with pr obability a t least δ 0 the correspo nding pa rtial distance of each will b e within ǫ 0 / √ 2 . That is enoug h to guarantee with the same probability that th e co lumns are within ǫ 0 of the seed. Of co urse, a union bo und will be ne eded so that the distance bound s above hold u niform ly over the set of sℓn columns u nder c onsideration , which mean s that we will n eed each to h av e at least t 0 := 2 µ 2 0 log(2 sℓn/ δ 0 ) observations at indices in co mmon with the correspon ding seed. All th is is predicated on N being large en ough so that such co lumns exist in X Ω . W e will return to this issue later , after determining the requiremen t for ℓ . For now we will simply assume that N ≥ ℓn . Lemma 4. Assume A3 and for each seed x let T x,ǫ 0 denote the number of columns of X in the ball of radius ǫ 0 / √ 3 about x . I f the n u mber of co lumns selected for each seed, ℓn , such that, ℓ ≥ max ( 2 k ν 0 ( ǫ 0 √ 3 ) r , 8 k log ( s/δ 0 ) nν 0 ( ǫ 0 √ 3 ) r ) , then P ( T x,ǫ 0 ≤ n ) ≤ δ 0 for all s seeds. Pr oof. Th e proba bility that a column ch osen unif ormly at rand om from X belon gs to th is ball is at least ν 0 ( ǫ 0 / √ 3) r /k , by Assumption A3 . Therefo re the expected numb er of points is E [ T x,ǫ 0 ] ≥ ℓnν 0 ( ǫ 0 √ 3 ) r k . By Chernoff ’ s bo und for any 0 < γ < 1 P T x,ǫ 0 ≤ (1 − γ ) ℓnν 0 ( ǫ 0 √ 3 ) r k ! ≤ exp − γ 2 2 ℓnν 0 ( ǫ 0 √ 3 ) r k ! . T ake γ = 1 / 2 which yields P T x,ǫ 0 ≤ ℓnν 0 ( ǫ 0 √ 3 ) r 2 k ! ≤ exp − ℓnν 0 ( ǫ 0 √ 3 ) r 8 k ! . W e would like to choose ℓ so that ℓnν 0 ( ǫ 0 √ 3 ) r 2 k ≥ n and so that exp − ℓnν 0 ( ǫ 0 √ 3 ) r 8 k ≤ δ 0 /s ( so that the desire d r esult fails for one or more of the s seeds is less than δ 0 ). The first con dition lead s to the requ irement ℓ ≥ 2 k ν 0 ( ǫ 0 √ 3 ) r . T he second condition prod uces the requ irement ℓ ≥ 8 k log ( s/δ 0 ) nν 0 ( ǫ 0 √ 3 ) r . W e can now formally state the procedu re for finding local neighbor hoods in Algor ithm 1. Recall that the number of observed entries in each seed is at least η 0 , per Lemma 2. Lemma 5. If N is sufficiently lar ge and η 0 > t 0 , then th e Loc a l Neighbo rhood Pr o cedure in Algorithm 1 pr oduces at least n columns within ǫ 0 of each seed, and at least one seed will belong to each of S i,ǫ 0 , for i = 1 , . . . , k , with pr ob a bility at lea st 1 − 3 δ 0 . Pr oof. Lem ma 2 states that if we select s 0 seeds, then with prob ability at least 1 − δ 0 there is a seed in each S i,ǫ 0 , i = 1 , . . . , k , with at least η 0 observed en tries, wh ere η 0 is d efined in (3). Lem ma 4 implies that if ℓ 0 n co lumns are selected un iformly at random f or each seed, then with pro bability at least 1 − δ 0 for each seed at least n o f the columns 7 Algorithm 1 - Local Neighborh ood Pro cedure Input: n , k , µ 0 , ǫ 0 , ν 0 , η 0 , δ 0 > 0 . s 0 := k (log k + log 1 / δ 0 ) (1 − e − 4 ) ν 0 ℓ 0 := & max ( 2 k ν 0 ( ǫ 0 √ 3 ) r , 8 k log ( s 0 /δ 0 ) nν 0 ( ǫ 0 √ 3 ) r )' t 0 := ⌈ 2 µ 2 0 log(2 s 0 ℓ 0 n/δ 0 ) ⌉ Steps: 1. Select s 0 “seed” columns uniform ly at r andom and discard all with less than η 0 observations 2. For each s eed, find all colum ns with t 0 observations at loca tions observed in the seed 3. Randomly select ℓ 0 n colum ns from each such set 4. Form local neighb orhoo d f or each seed by ran domly selecting n columns with par tial distance less than ǫ 0 / √ 2 from the seed will be within a d istance ǫ 0 / √ 3 of the seed . Each seed has at least η 0 observed entries and we need to find ℓ 0 n other columns with at least t 0 observations at indices where the seed was observed. Provided that η 0 ≥ t 0 , this is ce rtainly possible if N is large enou gh. It follows from Lemma 3 that ℓ 0 n columns have at least t 0 observations at ind ices where the seed was also o bserved, then with p robab ility at least 1 − δ 0 the p artial distances will be within ǫ 0 / √ 2 , which implies the true distances are within ǫ 0 . The result follows by the un ion bound. Finally , we quantify just how large N n eeds to be. Lemma 4 also shows that we requ ire at least N ≥ ℓn ≥ max ( 2 k n ν 0 ( ǫ 0 √ 3 ) r , 8 k log ( s/δ 0 ) ν 0 ( ǫ 0 √ 3 ) r ) . Howe ver, w e must also determine a lower bound on the prob ability that a colum n selected un iformly at ran dom has at least t 0 observed ind ices in common with a seed. Let γ 0 denote th is proba bility , and let p 0 denote the probab ility of observing each entry in X . Note that our main result, Theorem 2.1, assumes that p 0 ≥ 128 β ma x { µ 2 1 , µ 0 } ν 0 r log 2 ( n ) n . Since eac h seed ha s a t le ast η 0 entries o bserved, γ 0 is grea ter than or equ al to the pro bability that a Binomia l ( η 0 , p 0 ) random variable is a t least t 0 . Thus, γ 0 ≥ η 0 X j = t 0 η 0 j p j 0 (1 − p 0 ) η 0 − j . This implies that the expected number of colum ns with t 0 or more observed indices in common with a seed is at least γ 0 N . If e n is the actual numb er with this property , then by Chern off ’ s bou nd, P ( e n ≤ γ 0 N / 2) ≤ exp( − γ 0 N / 8) . So N ≥ 2 ℓ 0 γ − 1 0 n will suffice to gu arantee th at enough colu mns ca n be fou nd for each seed with p robab ility at least 1 − s 0 exp( − ℓ 0 n/ 4) ≥ 1 − δ 0 since this will be far larger than 1 − δ 0 , since δ 0 is polyno mial in n . T o take this a step further, a simple lower bou nd on γ 0 is ob tained as follows. Sup pose we consid er only a t 0 -sized subset o f the indices where the seed is observed . Th e pr obability that an other co lumn selected at rando m is ob served at all t 0 indices in this subset i s p t 0 0 . Clearly γ 0 ≥ p t 0 0 = exp( t 0 log p 0 ) ≥ (2 s 0 ℓ 0 n ) 2 µ 2 0 log p 0 . This yields the following sufficient condition on th e size of N : N ≥ ℓ 0 n (2 s 0 ℓ 0 n/δ 0 ) 2 µ 2 0 log p − 1 0 . 8 From the definitions of s 0 and ℓ 0 , this implies tha t if 2 µ 2 0 log p 0 is a fixed co nstant, then a sufficient nu mber o f columns will exist if N = O ( poly ( k n /δ 0 )) . F o r example, if µ 2 0 = 1 and p 0 = 1 / 2 , then N = O (( k n ) /δ 0 ) 2 . 4 ) will suffice; i.e., N need o nly grow polyno mially in n . On the other hand, in the extremely und ersampled case p 0 scales like log 2 ( n ) /n (as n grows and r and k stay c onstant) and N will n eed to grow almost exponentially in n , like n log n − 2 log log n . 4 Local Subspace Completion For each of our local neighb or sets, we will ha ve an incompletely obser ved n × n matrix ; if all the neighb ors b elong to a single subspace, the matrix will ha ve rank ≤ r . First, we r ecall the following result from low-rank matrix comp letion theory [1]. Lemma 6. Consider an n × n matrix of rank ≤ r a n d r ow and column spaces with coh e r en ces bounded a bove by some con stant µ 0 . Then the matrix can b e e x a ctly comp leted if m ′ ≥ 64 max µ 2 1 , µ 0 β r n log 2 (2 n ) (4) entries ar e observed uniformly at rando m, for constan ts β > 0 and with pr ob a bility ≥ 1 − 6 (2 n ) 2 − 2 β log n − n 2 − 2 β 1 / 2 . W e wish to app ly these results to our local n eighbor sets, but we have three issues we m ust addr ess: First, the sampling of the matrices forme d by lo cal n eighbo rhood sets is not unifo rm since the set is selected b ased on the observed indic es of the seed. Seco nd, gi ven Lemma 2 we must complete not one, b ut s 0 (see Algorithm 1) incomplete matrices simultane ously with high pro bability . Third, some of the loca l neighb or sets may hav e column s from mo re than one subspace. Let us consider each issue separately . First c onsider the fact that our in complete subm atrices are not sampled un iformly . The non- unifor mity can be corrected with a simple thinnin g p rocedu re. Recall that the column s in th e seed’ s local neighb orhoo d are identified first by finding column s with sufficient overlap with each seed’ s obser vations. T o refe r to the seed’ s o bservations, we will say “the support of the seed. ” Due to this selec tion of columns, the resulting n eighbo rhood colum ns are highly sampled on the support of the seed. In fact, if we again u se the no tation q for the m inimum overlap between two co lumns needed to calcu late distance, then th ese colu mns have at least q ob servations on the supp ort of the seed. Off the support, these co lumns are still sampled u niformly at rando m with the same probab ility as the entire ma trix. T herefor e we focus on ly o n correcting the sampling pattern on the support of the seed. Let t be the cardinality of th e support of a particular seed. Because all entries of the entire matrix are sampled indepen dently with pro bability p 0 , th en for a ra ndomly selected column , the ra ndom variable which gen erates t is binomial. For neighbo rs selected to have at least q overlap with a particular seed, we d enote t ′ as the numb er of samples overlapping with the sup port of the seed. The probability density for t ′ is positiv e only for j = q , . . . , t , P ( t ′ = j ) = t j p j 0 (1 − p 0 ) t − j ρ where ρ = P t j = q t j p j 0 (1 − p 0 ) t − j . In order to thin the common support, we need tw o new ran dom v ariables. The first is a bernoulli, call it Y , which takes the value 1 with prob ability ρ an d 0 with pr obability 1 − ρ . The seco nd ran dom variable, call it Z , takes values j = 0 , . . . , q − 1 with prob ability P ( Z = j ) = t j p j 0 (1 − p 0 ) t − j 1 − ρ Define t ′′ = t ′ Y + Z (1 − Y ) . The density of t ′′ is P ( t ′′ = j ) = P ( Z = j )(1 − ρ ) j = 0 , . . . , q − 1 P ( t ′ = j ) ρ j = q , . . . , t (5) 9 which equ al to the desired bin omial d istribution. Thus, t he thinning is accomplished as follo ws. For each column draw an independ ent sample of Y . If the sample is 1 , then the column is not altered . If the samp le is 0 , then a realization of Z is drawn, which we denote by z . Select a rand om subset of s ize z from the observed entries in the s eed suppor t and discard the rem ainder . W e n ote th at the seed itself sho uld no t be used in completion, b ecause there is a dependenc e between the sample locations of the seed column and its selected neighbo rs which cann ot be eliminated. Now after thin ning, we hav e the following matrix comp letion guarantee fo r each neighbo rhood matr ix. Lemma 7 . A ssume all s 0 seed neighborhoo d ma trices a re th in ned acco r d ing to the d iscussion a bove, ha ve rank ≤ r , and the matrix entries ar e observed un iformly a t rand om with pr oba bility , p 0 ≥ 128 β max { µ 2 1 , µ 0 } ν 0 r log 2 ( n ) n (6) Then with pr ob ability ≥ 1 − 12 s 0 n 2 − 2 β 1 / 2 log n , all s 0 matrices ca n be p erfectly c o mpleted. Pr oof. First, we find that if each matr ix has m ′ ≥ 64 max µ 2 1 , µ 0 β r n log 2 (2 n ) entries ob served u niform ly at ran dom (with re placement) , then with prob ability ≥ 1 − 12 s 0 n 2 − 2 β 1 / 2 log n , a ll s 0 matrices are perfectly completed . This follows by Lemma 6, the observation that 6 (2 n ) 2 − 2 β log n + n 2 − 2 β 1 / 2 ≤ 12 n 2 − 2 β 1 / 2 log n , and a simple application of the union bound . But, under ou r sampling assump tions, the numb er of entries ob served in each seed n eighbo rhood matrix is ran dom. Thus, the to tal num ber of ob served entries in e ach is guaran teed to be sufficiently large with high p robab ility as follows. The ran dom numb er of entries o bserved in an n × n ma trix is b m ∼ Binomial ( p 0 , n 2 ) . By Chernoff ’ s bound we h av e P ( b m ≤ n 2 p 0 / 2) ≤ exp( − n 2 p 0 / 8) . By the u nion bou nd we find that b m ≥ m ′ entries ar e observed in e ach o f th e s 0 seed matrices with prob ability at least 1 − exp( − n 2 p 0 / 8 + log s 0 ) if p 0 ≥ 128 β max { µ 2 1 ,µ 0 } ν 0 r log 2 ( n ) n . Since n 2 p 0 > r n log 2 n and s 0 = O ( k (log k + log n )) , this p robab ility tends to zero expo nentially in n as long as k = o ( e n ) , which hold s accord ing to Assumptio n A1 . Theref ore this h olds with proba bility at least 1 − 12 s 0 n 2 − 2 β 1 / 2 log n . Finally , let us consider the third is sue, the possibility that one or more of the po ints in the neighborh ood of a seed lies in a subspace d ifferent than the seed sub space. Wh en this occurs, th e ra nk of the submatrix fo rmed by th e seed’ s neighbo r columns will be larger than the d imension of the seed subspace. Without loss of gen erality assume that we have on ly tw o subspaces repr esented in the neighbor set, and assume their dimensions are r ′ and r ′′ . First, in the case that r ′ + r ′′ > r , when a ra nk ≥ r matrix is c ompleted to a rank r matrix , with overwhelmin g probability th ere will be erro rs with respect to the observations as long as the num ber of sample s in each column is O ( r lo g r ) , which is assumed in o ur case; see [12]. Thu s we can detect and discard these cand idates. Second ly , in the case that r ′ + r ′′ ≤ r , we still have enough samples to complete this matrix successfully with high pro bability . Howev er , since we have drawn enough seeds to g uarantee that every subspac e has a seed with a neigh borho od entir ely in that subsp ace, we will find that this problem seed is redun dant. This is deter mined in the Subspace Refinement st ep. 5 Subspace Refinement Each of the matrix com pletion steps a bove yields a low-rank matrix with a corresp onding column subspace, which we will call the candid ate subspaces. While the tr ue num ber of subspa ces will not be k nown in ad vance, since s 0 = O ( k (log k + log(1 /δ 0 )) , the candidate su bspaces will contain the true subspaces with high probab ility (see Lemma 4). W e must now deal with the algorithmic is sue of determ ining the true set of subspaces. W e first note that, fro m Assumption A3 , with pro bability 1 a set of po ints of size ≥ r all dr awn f rom a single subspace S of dime nsion ≤ r will span S . In fact, any b < r points will span a b -dimensio nal sub space of the r -d imensional subspace S . 10 Assume that r < n , since oth erwise it is clearly necessary to observe all entries. Therefo re, if a seed’ s nearest neighbo rhoo d set is confined to a sin gle sub space, then th e colu mns in span their subspace. And if the seed ’ s nearest neighbo rhoo d contain s colu mns f rom two or more subspaces, then the matrix will have ran k larger than that of any of the constitue nt subspaces. Thus, if a certain candid ate subspace is spanned by the union of two or mor e smaller candidate subspaces, th en it follows that that subspac e is not a true subspace (since we assume that none of the true subspaces are contained within another). This observation suggests the following subspace refinement proced ure. The s 0 matrix completio ns yield s ≤ s 0 candidate column subsp aces; s may be less than s 0 since comp letions that fail are discarded as described above. First sort the estimated sub spaces in order o f ran k fr om smallest to largest (with arbitrary o rdering of subspaces of the same ra nk), which we write as S (1) , . . . , S ( s ) . W e will deno te the final set of estimated subspaces as b S 1 , . . . , b S k . The first subspace b S 1 := S (1) , a lowest-rank subsp ace in the candida te set. Next, b S 2 = S (2) if an d o nly if S (2) is n ot contained in b S 1 . Following this simple sequen tial strate gy , suppose that when we reach the cand idate S ( j ) we hav e so far determine d b S 1 , . . . , b S i , i < j . If S ( j ) is not in th e span o f ∪ i ℓ =1 b S ℓ , the n we set b S i +1 = S ( j ) , o therwise we move on to the next candidate. In this way , we can pr oceed sequentially through the rank-ord ered list o f candidates, and we will identify all true subspaces. 6 The Full Monty Now all will be revealed. At this po int, we hav e identified the tr ue subspaces, and all N columns lie in the span of one of tho se sub spaces. For e ase of pr esentation, w e assume that the number o f sub spaces is exactly k . Howe ver if columns lie in the sp an of fe wer than k , then th e proc edure ab ove will p roduc e the cor rect num ber . T o complete the full matrix , we proceed o ne colu mn at a time. For each column of X Ω , we deter mine the correct sub space to which this column belong s, and we then complete the column using that sub space. W e can do th is with high pro bability due to results from [12, 14]. The first step is that o f subspace assignm ent, d etermining the cor rect subspace to wh ich this colu mn belongs. In [14], it is sh own that given k sub spaces, an incomplete vector ca n b e assigne d to its clo sest sub space with high probab ility given enoug h observations. In the situation at hand , we ha ve a special case of the results of [14] becau se we are considering the more specific situation where our incom plete vector lies exactly in one of the candid ate subspaces, and we hav e an upper bound for both the dimension and coheren ce of tho se subspaces. Lemma 8. Let {S 1 , . . . , S k } b e a co llection of k subspaces of dimension ≤ r and coherence p arameter boun d ed above by µ 0 . Consider co lumn vector x with index set Ω ∈ { 1 , . . . , n } , and defi ne P Ω , S j = U j Ω U j Ω T U j Ω − 1 U j Ω T , wher e U j is the orthonorma l column span of S j and U j Ω is the column span of S j r estricted to the observed r ows, Ω . W ithout loss of generality , suppose the column of inter est x ∈ S 1 . If A3 holds, and the pr o bability of observing each entry of x is independen t an d Bernoulli with p arameter p 0 ≥ 128 β max { µ 2 1 , µ 0 } ν 0 r log 2 ( n ) n . Then with pr ob ability at lea st 1 − (3( k − 1) + 2) δ 0 , k x Ω − P Ω , S 1 x Ω k 2 2 = 0 (7) and for j = 2 , . . . , k k x Ω − P Ω , S j x Ω k 2 2 > 0 . (8) Pr oof. W e wish to u se results from [12, 14], which require a fix ed number o f measu rements | Ω | . By Cher noff ’ s bou nd P | Ω | ≤ np 0 2 ≤ ex p − np 0 8 . 11 Note th at np 0 > 16 r β log 2 n , theref ore exp − np 0 8 < ( n − 2 β ) log n < δ 0 ; in other words, we o bserve | Ω | > np 0 / 2 entries of x with p robab ility 1 − δ 0 . Th is set Ω is selected uniform ly at r andom among all sets o f size | Ω | , but using Lemma 1 we can assume that the samples are drawn uniformly with replacement in order to apply results of [12, 14]. Now we sh ow that | Ω | > np 0 / 2 samp les selected unifor mly with rep lacement implies that | Ω | > max 8 rµ 0 3 log 2 r δ 0 , rµ 0 (1 + ξ ) 2 (1 − α )(1 − γ ) (9) where ξ , α > 0 and γ ∈ (0 , 1) are define d as α = r 2 µ 2 1 | Ω | log 1 δ 0 , ξ = r 2 µ 1 log 1 δ 0 , and γ = r 8 r µ 0 3 | Ω | log 2 r δ 0 . W e start with the second term in the max of (9). Substituting δ 0 and the boun d for p 0 , o ne can show that for n ≥ 15 both α ≤ 1 / 2 and γ ≤ 1 / 2 . Th is makes (1 + ξ ) 2 / (1 − α )(1 − γ ) ≤ 4(1 − ξ ) 2 ≤ 8 ξ 2 for ξ > 2 . 5 , i.e. fo r δ 0 < 0 . 04 . W e finish this argumen t by n oting that 8 ξ 2 = 16 µ 1 log(1 /δ 0 ) < np 0 / 2 ; the re is in fact an O ( r log( n )) g ap between the two. Similarly for the first term in the max of (9), 8 3 rµ 0 log 2 r δ 0 < np 0 / 2 ; here the gap is O (log ( n )) . Now we pr ove (7), which fo llows from [1 2]. W ith | Ω | > 8 3 rµ 0 log 2 r δ 0 , we ha ve that U T Ω U Ω is inv ertible with probab ility at least 1 − δ 0 accordin g to Lemm a 3 of [12]. Th is implies that U T x = U T Ω U Ω − 1 U T Ω x Ω . (10) Call a 1 = U T x . Since x ∈ S , U a 1 = x , and a 1 is in fact the un ique solution to U a = x . Now con sider the equatio n U Ω a = x Ω . T he assumption that U T Ω U Ω is in vertible imp lies that a 2 = U T Ω U Ω − 1 U T Ω x Ω exists and is the unique solution to U Ω a = x Ω . Howe ver , U Ω a 1 = x Ω as well, meaning that a 1 = a 2 . Thus, we have k x Ω − P Ω , S 1 x Ω k 2 2 = k x Ω − U Ω U T x k 2 2 = 0 with probability at least 1 − δ 0 . Now we prove (8), paralleling Theor em 1 in [1 4]. W e use A ssumption A3 to ensure that x / ∈ S j , j = 2 , . . . , k . This along with (9) and Theorem 1 from [12] guarantee s t hat k x Ω − P Ω , S j x Ω k 2 2 ≥ | Ω | (1 − α ) − rµ 0 (1+ ξ ) 2 1 − γ n k x − P S j x k 2 2 > 0 for each j = 2 , . . . , k with probab ility at least 1 − 3 δ 0 . W ith a unio n bou nd this holds simultaneously for all k − 1 alternative sub spaces with probability at least 1 − 3( k − 1 ) δ 0 . When we also include the e vents that (7 ) holds and that | Ω | > np 0 / 2 , we get that the entire theorem holds with probability at least 1 − (3( k − 1) + 2 ) δ 0 . Finally , d enote the column to be completed by x Ω . T o co mplete x Ω we first determine which subspa ce it belo ngs to using the results ab ove. For a given column we can use the inco mplete da ta pr ojectio n residual of (7). W ith probability at least 1 − (3( k − 1) + 2) δ 0 , the residual will b e zero fo r the correct sub space and strictly positive for all oth er subspaces. Using the span of the chosen subspace, U , we can then complete the column by using b x = U U T Ω U Ω − 1 U T Ω x Ω . W e reiterate that Lemma 8 allows us to complete a single column x with probab ility 1 − (3( k − 1) + 2 ) δ 0 . If we wish to complete the entire matrix , we will need another un ion bou nd over all N colum ns, leadin g t o a log N factor in our req uirement on p 0 . Since N may be quite lar ge in applications, we prefer to state our result in terms of per-column completion bound . The con fidence level stated in T heorem 2. 1 is th e re sult of applying the union bo und to all the steps req uired in the Sections 3, 4, and 6. All hold simultaneously with probab ility at least 1 − (6 + 3( k − 1) + 12 s 0 ) δ 0 < 1 − (6 + 15 s 0 ) δ 0 , which proves the theore m. 7 Experiments The fo llowing experiments ev aluate the perf ormanc e of the proposed high- rank matrix comp letion p rocedu re and compare results with standard low-rank matrix com pletion based on nuclear norm minimization. 12 7.1 Numerical Simulations W e begin by e xamining a highly synthesized exper iment where the data exactly matches the ass umption s of our high- rank m atrix com pletion pro cedure. The key parameters w ere ch osen as follows: n = 1 00 , N = 50 0 0 , k = 10 , and r = 5 . Th e k subspaces were r -dimen sional, and each was gener ated by r vectors drawn from the N (0 , I n ) d istribution and tak ing their span. The r esulting sub spaces are highly incoheren t with the canonica l basis f or R n . For each subspace, we ge nerate 50 0 p oints d rawn fro m a N (0 , U U T ) distribution, where U is a n × r matrix whose orth onor mal columns span the subspace. Ou r procedure was impleme nted using ⌈ 3 k log k ⌉ seeds. The matrix completion software called GR OUSE (av a ilable here [15]) was u sed in our procedu re an d to implement the standard low-rank ma trix completion s. W e ran 50 independe nt trials of ou r procedu re and compared it to standard low-rank matrix completion. The results are summarized in the figur es below . T he key message is that our n ew pr ocedur e can provid e acc urate completion s fro m far fewer observations co mpared to standard low-rank completio n, which is precisely what ou r main result predicts. Figure 2: The number of correctly comp leted columns (with tolerances sho wn above, 10 e- 5 or 0 . 01 ), versus the average number of observ ations per column. As expected , our procedure (termed high rank M C in the plot) p rovides accu rate completion with only about 50 samples per column. Note that r log n ≈ 23 in this simulation, so this is quite close to our b ound. On the other hand, sinc e the rank of the full ma trix is r k = 50 , the standard lo w-rank matrix completion bound requires m > 50 log n ≈ 230 . Therefore, it is not surprising that the standard method (termed low rank M C abov e) requires almost all samples in each column. 7.2 Network T opology Inference Experimen ts The ability to recover Internet router-level connectivity is of impor tance to network man agers, network operators and the area of security . As a comp lement to the hea v y network load of standard active p robing method s ( e.g., [1 6]), which scale po orly for In ternet-scale networks, recent r esearch has f ocused on the ability to recover Internet connec ti vity from passiv ely o bserved measurem ents [17]. Using a p assi ve scheme, no additio nal pro bes ar e sent thro ugh the network; instead we place passi ve mo nitors on network link s to observe “ho p-cou nts” in the Internet ( i.e, the numbe r of routers between two Intern et resources) fr om traffic that n aturally traverses the link the mon itor is p laced on . An example of this measureme nt infr astructure can be seen in Figure 3. These hop count observations result in an n × N matrix, where n is the num ber of passi ve monitor s and N is the total uniq ue IP add resses ob served. Due to the pa ssi ve nature of th ese observations, specifically the req uirement that we only observe traffic that hap pens to b e trav ersing the link whe re a mo nitor is loca ted, this hop count matrix will be massively incomplete. A comm on goal is to impu te (or fill-in ) the missing compo nents of this hop cou nt matrix in order to infer network characteristics. Prior work o n analy zing passi vely observed hop matr ices have f ound a d istinct subspace m ixture structure [9 ], where the fu ll hop count matrix, while globally hig h ra nk, is generated from a series of low ran k su bcompo nents. These low r ank subcom ponen ts are the resu lt of the Internet top ology structure, whe re all IP ad dresses in a c ommon subnet exist beh ind a si ngle com mon bord er ro uter . This network structur e is such that any probe sent from a n IP in a a particular s ubnet to a monitor must tra verse throug h th e same border router . A result of this structure is a ran k-two h op count m atrix for all IP addresses in that subn et, consisting of the hop cou nt vector to th e bord er router and a co nstant offset relatin g to the distanc e from each IP addr ess to the bord er r outer . Using th is insight, we apply the hig h-rank 13 Passive Monitors Subnet Subnet Subnet Subnet Internet Core Border Router Border Router Border Router Border Router Figure 3: Internet topology example of subnets sending traffic to passive monitors throug h the Internet core and common border routers. matrix completio n approach on in complete hop count matrices. Using a Heuristically Op timal T o polog y from [18], we simulated a network topolog y and measure ment infr astruc- ture consisting of N = 2700 total IP ad dresses unifo rmly distributed over k = 12 different subnets. The h op counts are generated on the topology using shortest-pa th routing from n = 7 5 passiv e monitors located randomly throughout the network. As stated above, each s ubnet cor respond s to a subspace of dime nsion r = 2 . Observ ing only 40% of the total hop counts, in Figure 4 we present the r esults of the hop count m atrix completion exp eriments, comparing the perfor mance of th e high- rank p rocedu re with stand ard low-rank m atrix completio n. The experimen t shows d ramatic improvements, as over 70% of the missing ho p counts can be impu ted exactly using the h igh-ran k matrix completion methodo logy , and app roximately no missing elemen ts are i mputed exactly using standard low-rank matr ix completio n. 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 Approximation Error Cumulative Distribution High Rank MC Standard MC Figure 4: Hop coun t imputation results, using a synthetic netw ork with k = 12 subnets, n = 75 passi ve monitors, and N = 2700 IP addresses. The cumulati ve distribution of estimation error is sho wn wit h respect to observing 40% of the total elements. Finally , using real-world Intern et delay measure ments (cou rtesy of [19]) fr om n = 1 00 monito rs to N = 225 50 IP add resses, we test imputation p erforma nce when the under lying subnet structu re is not k nown. Using the estimate k = 15 , in Figure 5 we find a significant perfo rmance increase using the high-rank matr ix completion technique. Refer ences [1] B. Recht, “A Simpler Approach to Matrix Completion, ” in T o a p pear in Journal of Machine Learning R e sear ch, arXiv:091 0.065 1v2 . [2] E . J. Cand ` es and T . T ao, “The Power of Con vex Relax ation: Near-Optimal Matrix Completion .” in IEEE T rans- actions on Information Theo ry , v o l. 56, May 2010 , pp. 20 53–2 080. [3] R. V idal, “A T utor ial on Subspace Clustering, ” in Johns Ho pkins T echnical Rep ort , 2010. [4] K. Kanatani, “Motion Segmentation b y Subspace Separatio n and Model Selec tion, ” in Computer V ision, 2001. ICCV 2 0 01. Pr ocee dings. Eigh th IEEE International Confer ence on , vol. 2, 2001, pp. 586–5 91. 14 0 20 40 60 80 100 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Approximation Error (in ms) Cumulative Distribution High Rank MC Standard MC Figure 5: Real-world delay imputation results, using a network n = 100 monitors, N = 22550 IP addresses, and an unkno wn number of subnets. The cumulati ve distribution of estimation error is sho wn with respect to observing 40% of the total delay elements. [5] R. V id al, Y . Ma, and S. Sastry , “Generalized Principal Compon ent Analysis (GPCA), ” IEEE T ransactions on P attern A nalysis an d Machine Intelligence , vol. 27, December 2005. [6] G. Lerman and T . Zh ang, “Robust Recovery of Mu ltiple Subspaces by L p Minimization, ” 2011, Prepr int at http://arxiv .org/abs/110 4.3770 . [7] A. Gruber and Y . W eiss, “Multibody Factorization with Uncertainty and Missing Data using the EM Algorithm, ” in Pr oceeding s of the 200 4 IEEE Compute r Society Conference on Compu ter V ision and P attern Recogn ition (CVPR) , vol. 1, J une 2004 . [8] R. V idal, R. T ro n, and R. Hartley , “Mu ltiframe Motion Se g mentation with Missing Data Using Po wer F actoriza- tion and GPCA, ” Intern a tional Journal o f Comp uter V ision , vol. 79, pp. 85–105, 2008. [9] B. Er iksson, P . Barford , an d R. Nowak, “Network Discovery from Passiv e Measuremen ts, ” in Pr oceedin gs of AC M SIGCOMM Confer e n ce , Seattle, W A, August 2008. [10] E. Cand ` es an d B. Recht, “Exact Matrix Comp letion V ia Con vex Optimizatio n.” in F ou ndation s of Computatio nal Mathematics , vol. 9, 2009, pp. 71 7–77 2. [11] B. Eriksson, P . Barford, J. Sommer s, and R. Nowak, “Domain Impute: Inferrin g Unseen Com ponen ts in the Internet, ” in Pr oceeding s o f IEEE INFOCOM Mini-Conference , Shang hai, China, April 2011, pp. 171–175 . [12] L. Balzano, B. Recht, an d R. N ow ak, “High- Dimensional Matched Subspa ce De tection When Data are Missing, ” in Pr o ceedings o f the I nternation al Confer ence o n Information Theo ry , June 2010, av ailable at http://arxiv .org/abs/100 2.0852 . [13] G. Chen and M. Magg ioni, “Multiscale Geometric and Spectral An alysis o f Plan e Arrangem ents, ” in IEEE Confer ence on Computer V ision and P attern Recognitio n (CVPR ) , Colorado Springs, CO, June 2011. [14] L. Balzano, R. Nowak, A. Szlam, and B. Recht, “ k -Sub spaces with missing data, ” Un iv ersity of W isconsin, Madison, T ech . Rep. ECE-11-02 , Febru ary 2011. [15] L. Balzano and B. Recht, 2010 , http://sun beam.ece. wisc.edu/gro use/ . [16] N. Spring, R. Mahajan, and D. W etherall, “Measur ing ISP T opolog ies with R ocketfuel, ” in Pr oceedin gs of ACM SIGCOMM , Pittsb urgh, P A, Au gust 2002. [17] B. Eriksson, P . Barford, R. Nowak, and M. Crovella, “Lear ning Network Structure fr om Passi ve Measur ements, ” in Pr oceedin gs of A CM I nternet Mea sur e me nt Confer ence , San Diego, CA, October 2007. [18] L. Li, D. Alderson , W . Willinger , an d J. Doyle, “A First-Principles Appro ach to Understan ding the In ternet’ s Router-Le vel T op ology, ” in Pr o c eedings of AC M SIGCOMM Confer en ce , August 2004. [19] J. Led lie, P . Gard ner, and M. Seltzer, “Network Coo rdinates in the Wild, ” in Pr oceedings of NSDI Con fer en ce , April 2007. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment