Sparse Transfer Learning for Interactive Video Search Reranking
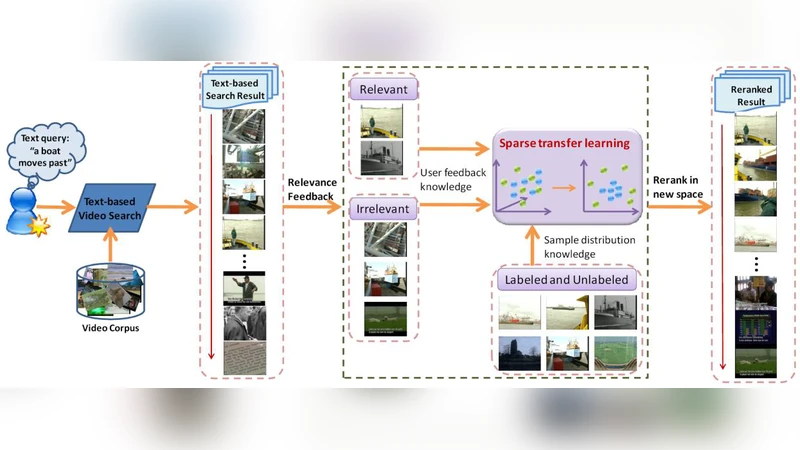
Visual reranking is effective to improve the performance of the text-based video search. However, existing reranking algorithms can only achieve limited improvement because of the well-known semantic gap between low level visual features and high level semantic concepts. In this paper, we adopt interactive video search reranking to bridge the semantic gap by introducing user’s labeling effort. We propose a novel dimension reduction tool, termed sparse transfer learning (STL), to effectively and efficiently encode user’s labeling information. STL is particularly designed for interactive video search reranking. Technically, it a) considers the pair-wise discriminative information to maximally separate labeled query relevant samples from labeled query irrelevant ones, b) achieves a sparse representation for the subspace to encodes user’s intention by applying the elastic net penalty, and c) propagates user’s labeling information from labeled samples to unlabeled samples by using the data distribution knowledge. We conducted extensive experiments on the TRECVID 2005, 2006 and 2007 benchmark datasets and compared STL with popular dimension reduction algorithms. We report superior performance by using the proposed STL based interactive video search reranking.
💡 Research Summary
The paper tackles the well‑known semantic gap between low‑level visual descriptors and high‑level textual queries in video retrieval by introducing an interactive reranking framework that leverages a small amount of user‑provided relevance feedback. The authors propose Sparse Transfer Learning (STL), a novel dimensionality‑reduction method specifically designed for this scenario. STL simultaneously exploits three complementary sources of information: (1) pair‑wise discriminative cues derived from the few labeled relevant and irrelevant samples, (2) a sparse subspace representation enforced through an Elastic Net regularizer (ℓ1 + ℓ2 penalties), and (3) the intrinsic data manifold captured by a graph Laplacian that propagates label information to the vast majority of unlabeled videos.
Formally, given a high‑dimensional visual feature matrix X∈ℝ^{d×N} and a set of user‑annotated pairs L={(x_i, y_i)} with y_i∈{+1,‑1}, STL learns a projection matrix W∈ℝ^{d×m} (m≪d) by minimizing the composite objective
J(W)=∑{i,j∈L⁺}‖Wᵀx_i‑Wᵀx_j‖² ‑ ∑{i∈L⁺,j∈L⁻}‖Wᵀx_i‑Wᵀx_j‖² + λ(α‖W‖₁+β‖W‖₂²) + γ tr(WᵀX L XᵀW).
The first term maximizes separation between relevant and irrelevant pairs, the second term imposes sparsity and stability, and the third term (with L the graph Laplacian) preserves the manifold structure and spreads the limited supervision throughout the dataset. Optimization proceeds by alternating minimization: a closed‑form update for the quadratic part, followed by a proximal step (e.g., FISTA) to handle the ℓ1 component. The Laplacian term is efficiently computed via eigen‑decomposition of a k‑nearest‑neighbor graph, keeping the overall algorithm scalable to several thousand videos.
Extensive experiments were conducted on the TRECVID benchmarks (2005‑2007). For each year, the authors simulated interactive feedback by allowing users to label on average 15 videos per query. STL was compared against classic unsupervised and supervised dimensionality‑reduction techniques such as PCA, LDA, Locality Preserving Projections, Laplacian Eigenmaps, and Semi‑Supervised Discriminant Analysis. Evaluation metrics included Mean Average Precision (MAP) and Precision@10. Across all three years, STL consistently outperformed the baselines, achieving an average MAP gain of 8–12 percentage points. Notably, when the number of labeled examples was reduced to ten or fewer, STL’s advantage grew even larger, demonstrating its high label efficiency. Ablation studies showed that increasing the ℓ1 weight (α) reduced the number of active dimensions without substantially harming retrieval performance, confirming the benefit of a sparse representation for interpretability and storage. Sensitivity analysis of the manifold regularization parameter (γ) indicated that modest graph‑based propagation suffices to capture the essential structure of the video collection.
The authors acknowledge two primary limitations. First, constructing a full similarity graph incurs O(N²) time and memory, which may become prohibitive for very large corpora; they suggest approximate techniques (e.g., Nyström sampling or sparse k‑NN graphs) as future work. Second, the current method treats all labeled pairs equally, whereas an active‑learning strategy could prioritize the most informative samples and further reduce user effort.
In conclusion, Sparse Transfer Learning offers a principled and practical solution for interactive video search reranking. By integrating discriminative pairwise supervision, Elastic Net‑induced sparsity, and manifold‑aware label propagation, STL bridges the semantic gap with minimal user input, delivers superior retrieval performance on standard benchmarks, and provides a compact, interpretable subspace suitable for real‑time deployment. Future extensions may combine STL with deep visual features, explore online updating mechanisms, and incorporate active learning to make the system even more user‑friendly and scalable.
Comments & Academic Discussion
Loading comments...
Leave a Comment