Truncated Power Method for Sparse Eigenvalue Problems
This paper considers the sparse eigenvalue problem, which is to extract dominant (largest) sparse eigenvectors with at most $k$ non-zero components. We propose a simple yet effective solution called truncated power method that can approximately solve…
Authors: Xiao-Tong Yuan, Tong Zhang
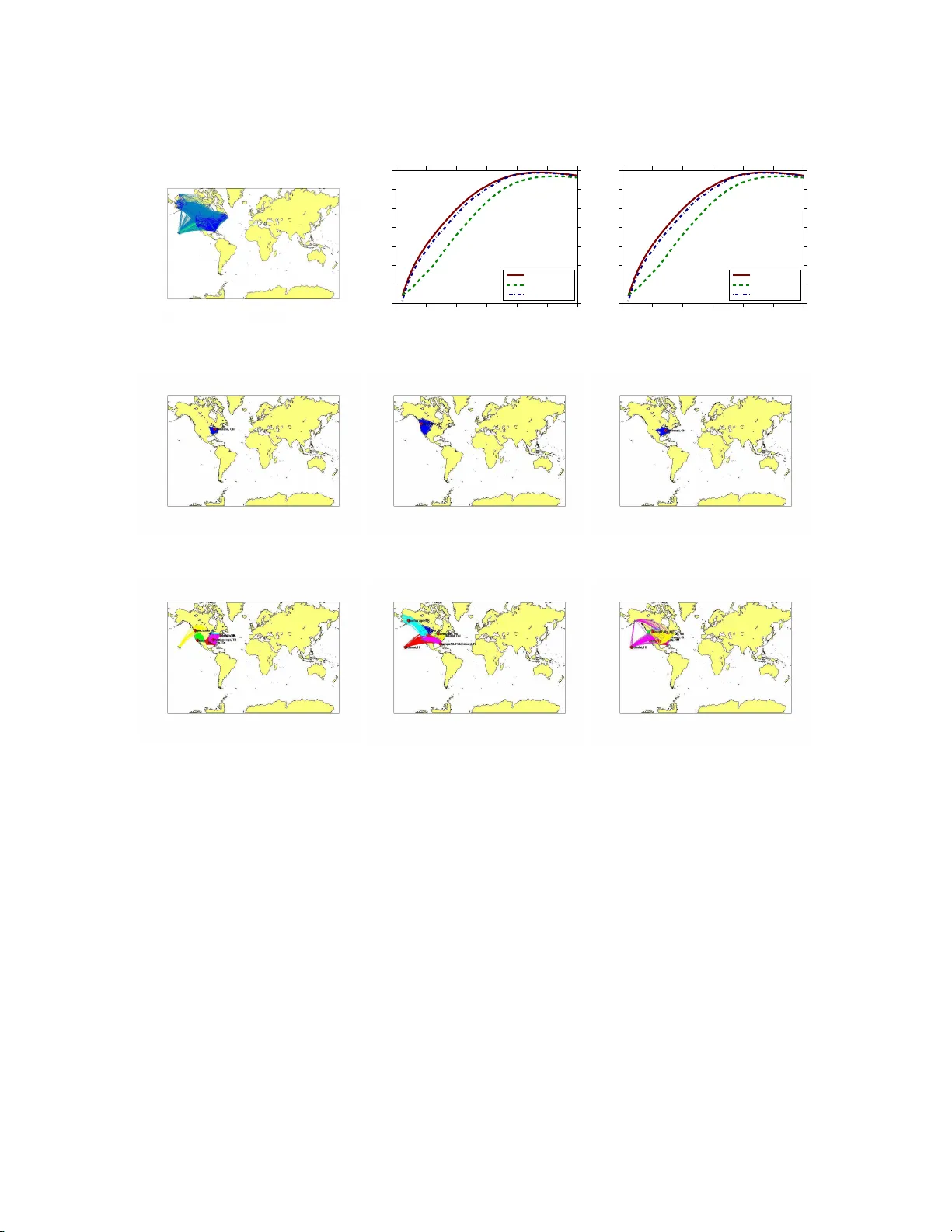
T runcated P o w er Metho d for Sparse Eigen v alue Problems Xiao-T ong Y uan Departmen t of Statistics Rutg ers Univ ersit y New Jersey , 08816 xyuan@stat. rutgers.edu T ong Zhang Departmen t of Statistics Rutg ers Univ ersit y New Jersey , 08816 tzhang@stat .rutgers.edu Abstract This pap er considers the spa rse eigenv alue pro blem, which is to extract dominant (largest) sparse eigenv ector s with at most k non-zero comp onents. W e pr op ose a simple yet effective solution ca lled trun c ate d p ower metho d tha t ca n approximately solve the underlying noncon- vex optimization pro ble m. A str ong spars e recov er y result is prov ed for the truncated p ow er metho d, and this theory is our key motiv ation fo r developing the new alg o rithm. The prop osed metho d is tes ted on applications such as sparse pr incipal comp onent ana ly sis and the dens- est k -subgr a ph problem. E xtensive exp eriments on several synthetic and r e al-world la rge scale datasets demonstr ate the comp etitive empirical p er formance of o ur method. 1 In tro d uction Giv en a p × p symm etric p ositiv e semidefinite matrix A , the lar gest k -sp arse eigenvalue problem aims to maximize the q u adratic form x ⊤ Ax w ith a spars e u nit v ector x ∈ R p with no more than k non-zero elemen ts: λ max ( A, k ) = max x ∈ R p x ⊤ Ax, sub ject to k x k = 1 , k x k 0 ≤ k , (1.1) where k · k denotes the ℓ 2 -norm, and k · k 0 denotes th e ℓ 0 -norm which count s the num b er of non-zero en tries in a v ector. The sparsit y is con trolled b y the v alues of k a n d can b e viewed as a design parameter. In mac hin e learning applications, e.g., pr incipal comp onent analysis, this p roblem is motiv ated from the follo wing p ertur bation f orm ulation of matrix A : A = ¯ A + E , (1.2) where A is the emp irical co v ariance matrix, ¯ A is the true co v ariance matrix, and E is a r andom p ertur bation due to ha ving only a fin ite n umb er of empirical samples. If w e assume that the largest eigen v ector ¯ x of ¯ A is sparse, then a natur al question is to reco ver ¯ x from the noisy observ ation A when the error E is “small”. In this context, th e problem (1.1 ) is also referred to as sp arse principal comp onent analysis (sparse PCA). 1 In general, problem (1.1) is n on-con ve x. In fact, it is also NP-hard because it can b e re- duced to the s ubset selection problem for ord inary least sq u ares r egression (Moghaddam et al., 2006), whic h is kn o wn to b e NP h ard. V arious researc h er s ha ve pr op osed app ro ximate optimiza- tion metho d s: some are based on greedy pro cedures (e.g., Moghaddam et al., 2006; Jolliffe et al., 2003; d’Aspr emon t et al., 2008), and some others are based on v arious types of conv ex relaxation or reformulatio n (e.g., d’Aspr emon t et al., 2007; Zou et al., 2006; Jour n ´ ee et al., 2010). Although man y algorithms ha ve b een prop osed, almost no satisfactory theoretical results exist for this pr ob- lem. The only exception is the analysis of the con v ex relaxation method (d’Aspremont et al., 2007) b y Amini & W ain wrigh t (2009) under the h igh d imensional sp ik ed co v ariance m o del (Johnstone, 2001). Ho w ever, the r esult w as concerned with v ariable selection consistency un der a v ery simple and sp ecific example with limited general applicabilit y . This pap er pr op oses a n ew computational pro cedure called trunc ate d p ower iter ation metho d that app ro ximately solv es (1.1). This metho d is similar to the classical p ow er metho d , with an additional tru ncation op eration t o ensure sparsit y . W e show that if t h e true m atrix ¯ A has a sparse (or app r o ximately sparse) dominant eige nv ector ¯ x , then u nder appropr iate assumptions, th is algorithm can reco ver ¯ x when the sp ectral norm of sparse subm atrices of the p ertu rbation E is small. Moreo v er, this result can b e prov ed under r elativ e generalit y without restricting our selv es to the rather sp ecific spik ed co v ariance mo d el. T herefore our analysis pro vid es strong th eoretical s u pp ort for this new metho d , and this d ifferentiat es our p r op osal from previous stud ies. W e hav e applied the prop osed metho d to sp ars e PCA and to the d ensest k -subgraph finding problem (with prop er mo dification). Extensive exp eriments on synthetic and r eal-w orld large scale datasets demonstrate b oth the comp etitiv e s parse reco ve r ing p erformance and the compu tational efficiency of our metho d. It is worth mentioning that the truncated p o w er metho d deve lop ed in this pap er can also b e applied to the smal lest k - sp arse eigenvalue problem giv en b y: λ min ( A, k ) = min x ∈ R p x ⊤ Ax, sub ject to k x k = 1 , k x k 0 ≤ k , whic h also has man y ap p lications in mac hine learning. 1.1 Notation Let S p = { A ∈ R p × p | A = A ⊤ } denote the set of symmetric matrices, and S p + = { A ∈ S p , A 0 } denote th e cone of sym metric, p ositiv e semidefinite (PSD) m atrices. F or any A ∈ S p , we denote its eigenv alues b y λ min ( A ) = λ p ( A ) ≤ · · · ≤ λ 1 ( A ) = λ max ( A ). W e use ρ ( A ) to denote the sp ectral norm of A , whic h is max {| λ min ( A ) | , | λ max ( A ) |} , and define ρ ( A, s ) := max {| λ min ( A, s ) | , | λ max ( A, s ) |} . The i -th en try of v ector x is denoted b y [ x ] i while [ A ] ij denotes the element on the i -th ro w and j -th column of matrix A . W e d en ote by A k an y k × k pr incipal submatrix of A and by A F the pr incipal sub matrix of A with ro ws and columns in dexed in set F . If necessary , w e also denote A F as the restriction of A on the ro ws and columns in d exed in F . Let k x k p b e th e ℓ p -norm of a vec tor x . In particular, k x k 2 = √ x ⊤ x denotes the Euclidean norm, k x k 1 = P d i =1 | [ x ] i | d en otes the ℓ 1 -norm, and k x k 0 = # { j : [ x ] j 6 = 0 } denotes the ℓ 0 -norm. F or sim- plicit y , w e also d enote the ℓ 2 norm k x k 2 b y k x k . In the rest of the pap er, we d efi ne Q ( x ) := x ⊤ Ax and let x ∗ b e the optimal solution of problem (1.1). W e let su pp( x ) := { j : | [ x ] j 6 = 0 } denote the supp ort set of the vecto r x . Giv en an in dex set F , we define x ( F ) := arg max x ∈ R p x ⊤ Ax, sub ject to k x k = 1 , supp( x ) ⊆ F . Finally , we denote by I p × p the p × p identit y matrix. 2 1.2 P ap er Organization The remaining of this pap er is organized as f ollo w s: Section 2 describ es the trun cated p o w er iteration algorithm that ap p ro ximately solve s problem (1.1). In Section 3 we analyze the solution qualit y of th e prop osed algo r ithm. Section 4 ev aluates the practical p erformance of the prop osed algorithm in applications of sparse P C A and th e densest k -su bgraph finding problems. W e conclude this wo r k and discuss p oten tial extensions in S ection 5. 2 T runcated P o w er Metho d Since λ max ( A, k ) equals λ max ( A ∗ k ) wh ere A ∗ k is the k × k principal s u bmatrix of A w ith the largest eigen v alue, one may solv e (1.1) b y exhaustiv ely en umerate all subs ets of { 1 , . . . , p } of size k in ord er to find A ∗ k . Ho wev er, this pr o cedure is impractical ev en for mo d erate sized k since the num b er of subsets is exp onent ial in k . Therefore in ord er to solv e the spare eigen v alue p roblem (1.1) more efficien tly , w e consid er an iterativ e pro cedu r e b ased on th e standard p ow er metho d for eigen v alue problems, while main tain- ing the desired sparsity for the inte r mediate solutions. The pro cedu r e, presented in Algorithm 2, generates a sequence of int erm ediate k -sp ars e eigen ve ctors x 0 , x 1 , . . . from an initial sparse app ro x- imation x 0 . A t eac h step t , the inte r mediate v ector x t − 1 is multiplie d b y A , and then the entries are truncated to zeros except for the largest k entries. Th e resu lting v ector is then n ormalized to unit length, whic h b ecomes x t . It will b e assumed throughout the pap er that the cardinalit y k of supp( x ∗ ) is a v ailable a prior; in p ractice this quant ity may b e regarded as a tu ning parameter of the algorithm. Definition 1. Given a ve ctor x and an index set F , we define the trunc ation op er ation T runc ate ( x, F ) to b e the ve ctor obtaine d by r estricting x to F , that is [ T runc ate ( x, F )] i = [ x ] i i ∈ F 0 otherwise . Algorithm 1: T ru ncated P ow er (TPo w er) Metho d Input : matrix A ∈ S p , initial v ector x 0 ∈ R p Output : x t P arameters : cardinalit y k ∈ { 1 , ..., p } Let t = 1. rep eat Compute x ′ t = Ax t − 1 / k Ax t − 1 k . Let F t = su pp( x ′ t , k ) b e the indices of x ′ t with the largest k absolute v alues. Compute ˆ x t = T run cate( x ′ t , F t ). Normalize x t = ˆ x t / k ˆ x t k . t ← t + 1 . un til Conver genc e ; Remark 1. Similar to the b ehavior of tr aditional p ower metho d, if A ∈ S p + , then TPower tries to find the (sp arse) e igenve ctor of A c orr e sp onding to the lar gest eige nv alue. Otherwise, it may find 3 the (sp arse) eigenve ctor with the smal lest eigenvalue if − λ p ( A ) > λ 1 ( A ) . However, this situation is e asily dete ctable b e c ause it c an only happ en when λ p ( A ) < 0 . In such c ase, we may r e start TPower with A r eplac e d by an appr opria tely shifte d version A + ˜ λI p × p . 3 Sparse Reco v ery Analysis W e consider the general noisy matrix m o del (1.2), and are sp ecially in terested in the high d imen- sional situation w here the dim en sion p of A is large. W e assu me that th e n oise matrix E is a dens e p × p matrix suc h that its sp arse su bmatrices ha ve small sp ectral norm ρ ( E , s ) for s in the same order of k . W e refer to this quant ity as r estricte d p erturb ation err or . Ho wev er, th e sp ectral n orm of the fu ll matrix p erturbation error ρ ( E ) can b e large. F or example, if the original co v ariance is corrupted by an additive standard Gaussian iid noise v ector, then ρ ( E , s ) = O ( p s log p/n ), w hic h gro ws linearly in √ s , instead of ρ ( E ) = O ( p p/n ), w hic h grows linearly in √ p . Th e main adv an tage of the sparse eigen v alue formulation (1.1) ov er the standard eigen v alue form ulation is that the es- timation er r or of its optimal solution dep ends on ρ ( E , s ) with resp ectiv ely a small s = O ( k ) rather than ρ ( E ). Th is linear dep en d ency on sparsit y k in stead of the original dimension p is analogous to similar results for sparse regression (or compressive s en sing) such as (Candes & T ao, 2005). In fact the restricted p erturbation error considered here is analogous to the id ea of restricted isometry prop erty (RIP) considered in (Candes & T ao, 2005). The purp ose of the section is to show th at if matrix ¯ A has a unique sparse (or approximate ly sparse) dominant eigen vec tor, then und er suitable conditions, TPo w er can (appr o ximately) reco ver this eigen vec tor from the noisy observ ation A . Assumption 1. Assume that the lar gest eigenvalue of ¯ A ∈ S p is λ = λ max ( ¯ A ) > 0 that is non- de ge ner ate, with a gap ∆ λ = λ − max j > 1 | λ j ( ¯ A ) | b etwe en the lar gest and the r emaining eigenvalues. Mor e over, assume that the eigenve ctor ¯ x c orr esp onding to the dominant eigenv alue λ is sp arse with c ar dinality ¯ k = k ¯ x k 0 . W e wa nt to show that under Assump tion 1, if the sp ectral n orm ρ ( E , s ) of the error m atrix is sm all for an appropr iately chosen s > ¯ k , then it is p ossible to appr o ximately reco v er ¯ x . Note that in the extreme case of s = p , this result follo ws directly from the standard eigenp ertur bation analysis (wh ich d o es not require Assu m ption 1). W e no w state our main result as b elo w, whic h sho ws th at und er app ropriate conditions, the TP ow er metho d can reco v er the sparse eigen v ector. Th e fin al error b ound is a direct generaliz ation of standard m atrix p ertur bation result that dep end s on th e f ull m atrix p ertur bation error ρ ( E ). Here this quan tit y is replaced by the restricted p erturbation error ρ ( E , s ). Theorem 1. We assume that Assumption 1 holds. L et s = 2 k + ¯ k with k ≥ 4 ¯ k . Assume that ρ ( E , s ) ≤ ∆ λ/ 2 . D e fine γ ( s ) := λ − ∆ λ + ρ ( E , s ) λ − ρ ( E , s ) < 1 , δ ( s ) := √ 2 ρ ( E , s ) p ρ ( E , s ) 2 + (∆ λ − 2 ρ ( E , s )) 2 . If | x ⊤ 0 ¯ x | ≥ u + δ ( s ) for some k x 0 k 0 ≤ k , k x 0 k = 1 , and u ∈ [0 , 1] such that µ 1 =(1 − γ ( s ) 2 ) u (1 − u 2 ) / 2 − 2 δ ( s ) + ( ¯ k /k ) 1 / 2 ∈ (0 , 1) , µ 2 = q (1 + 3( ¯ k /k ) 1 / 2 )(1 − 0 . 4 5(1 − γ ( s ) 2 )) < 1 , 4 then let µ = max( √ 1 − µ 1 , µ 2 ) , we have q 1 − | x ⊤ t ¯ x | ≤ µ t q 1 − | x ⊤ 0 ¯ x | + √ 5 δ ( s ) / (1 − µ 2 ) . Remark 2. W e only state our r esult with a r elatively simple b u t e asy to understand quantity ρ ( E , s ) , which we r ef e r to as r e stricte d p erturb ation err or. It is analo gous to the RIP c onc ept in (Candes & T ao, 2005), and is also dir e ctly c omp ar able to the tr aditional ful l matrix p erturb ation err or ρ ( E ) . W hile it is p ossible to obtain sharp er r esults with additional q uantities, we intentional ly ke ep the the or em simple so that its c onse qu enc e is r elatively e asy to interpr et. Remark 3. Although we state the r esult by assuming that the dominant eigenve ctor ¯ x is sp arse, the the or em c an also b e applie d to c ertain situations that ¯ x is only appr oximately sp arse. In su c h c ase, we simply let ¯ x ′ b e a ¯ k sp arse appr oximation of ¯ x . If ¯ x ′ − ¯ x is sufficiently smal l, then ¯ x ′ is the dominant eigenve ctor of a symmetric matrix ¯ A ′ that is close to ¯ A ; henc e the the or em c an b e applie d with the de c omp osition A = ¯ A ′ + E ′ wher e E ′ = E + A − ¯ A ′ . Note that w e did not mak e an y attempt to optimize th e constan ts in Theorem 1, wh ic h are relativ ely large. Th erefore in th e discu ssion, w e shall ignore the constan ts, and fo cus on the main message of Th eorem 1. If ρ ( E , s ) is smaller than the eigen-gap ∆ λ/ 2 > 0, then γ ( s ) < 1 and δ ( s ) = O ( ρ ( E , s )). It follo ws that u nder ap p ropriate cond itions, as long as we can fin d an initial x 0 suc h that | x ⊤ 0 ¯ x | ≥ c ( ρ ( E , s ) + ( ¯ k /k ) 1 / 2 ) for some constan t c , then 1 − | x ⊤ t ¯ x | conv erges geometrically until k x t − ¯ x k 2 = O ( ρ ( E , s ) 2 ) . This result is similar to the standard eigen ve ctor p erturbation resu lt stated in Lemma 2 of Ap- p end ix A, except that w e replace the s p ectral error ρ ( E , p ) of the fu ll matrix b y ρ ( E , s ) that can b e signifi can tly smaller wh en s ≪ p . T o our knowledge, this is the fi rst sparse reco v ery result for the sparse eigen v alue p roblem in a r elativ ely general setting. This theorem can b e considered as a strong theoretical j ustification of the p rop osed TP ow er algorithm that distinguishes it from earlier algorithms without theoretical guarantees. Sp ecifical ly , the replacemen t of the full m atrix p ertur bation err or ρ ( E ) 2 with ρ ( E , s ) 2 giv es the theoretical insigh ts on why TPo w er w ork s w ell in practice. T o illustrate our result, we briefly describ e a consequence of the theorem under the s p ik ed co v ariance mo del of (Johnstone, 2001) whic h wa s inv estiga ted b y Amini & W ainwrigh t (2009). W e assume that the observ ations are p dimensional v ectors x i = ¯ x + ǫ, for i = 1 , . . . , n , wh ere ǫ ∼ N (0 , I p × p ). F or simplicit y , we assume that k ¯ x k = 1. T he tru e co v ariance is ¯ A = ¯ x ¯ x ⊤ + I p × p , and A is the empir ical co v ariance A = 1 n n X i =1 x i x ⊤ i . 5 Let E = A − ¯ A , then random matrix th eory implies that with large probability , ρ ( E , s ) = O ( p s ln p/n ) . No w assume that max j | ¯ x j | is suffi cien tly large. In this case, w e can run TPo w er with a starting p oint x 0 = e j for some v ector e j (where e j is the v ector of zeros except the j -th en try b eing one) so that | e ⊤ j ¯ x | = | ¯ x j | is sufficiently large, and the assump tion f or the initial vec tor | x ⊤ 0 ¯ x | ≥ c ( ρ ( E , s ) + ( ¯ k /k ) 1 / 2 ) is satisfied with s = O ( ¯ k ). W e may run TPo wer with an appr opriate initial v ector to obtain an approxima te solution x t of error k x t − ¯ x k 2 = O ( ¯ k ln p/n ) . This is op timal. Note that our results are not d irectly comparable to those of Amini & W ain wrigh t (2009), which studied supp ort reco v ery . Nev ertheless, it is worth n oting that if max j | ¯ x j | is suffi- cien tly large, then our r esult b ecomes meaningful wh en n = O ( ¯ k ln p ); h o wev er their resu lt requires n = O ( ¯ k 2 ln p ) to b e meaningful, although th is is for the p essimistic case of ¯ x ha ving equal n onzero v alues of 1 / √ ¯ k . Finally we note that if w e cannot fi nd a large initial v alue with | x ⊤ 0 ¯ x | , then it may b e necessary to tak e a r elativ ely large k so that the requirement | x ⊤ 0 ¯ x | ≥ c (( ¯ k /k ) 1 / 2 ) is satisfied. With such a k , ρ ( E , s ) ma y b e relativ ely large and h ence the theorem indicates that x t ma y not con verge to ¯ x accurately . Nev ertheless, as long as | x ⊤ t ¯ x | conv erges to a v alue th at is not to o small (e.g., can b e muc h larger than | x ⊤ 0 ¯ x | ), we ma y redu ce k and reru n the algorithm with x t as initial v ector together with a small k . In this t wo stage pro cess, the ve ctor f ound from th e first stage (with large k ) is used to as the initial v alue of the second stage (with small k ). Therefore w e may also regard it as an initializa tion metho d to TP o wer. In practice, one ma y use other metho ds to obtain an appro ximate x 0 to initialize T P o wer, n ot necessarily restricted to ru nning TPo w er with larger k . Some practical alternativ es are discus sed in Section 4. 4 Applications In this section, w e illustrate the effectiv eness of TP ow er metho d wh en applied to sparse pr in cipal comp onent analysis (sparse PCA) (in Section 4.1) and th e densest k -subgraph (DkS) find ing prob- lem (in Section 4.2). The Matlab co de for repro d ucing the exp erimental results r ep orted in this section is online a v ailable at https: //sites .google. com/site/xtyuan1980/publications . 4.1 Sparse PCA Principal comp onent analysis (PCA) is a w ell established to ol for dim en sionalit y redu ction an d has a w ide r ange of applications in science and engineering wh ere high dimen s ional d atasets are encoun tered. Sparse prin cipal comp onen t analysis (sp arse PCA) is an extension of PCA that aims at fin ding sparse v ectors (loading vec tors) capturing the maximum amount of v ariance in the data. In recen t y ears, v arious researc hers h a ve prop osed v arious app roac hes to directly ad- dress the conflicting goals of explaining v ariance and ac hieving sparsity in sparse PCA. F or in- stance, Z ou et al. (2006) formulated s p arse PC A as a regression-t yp e optimizatio n p roblem and imp osed the Lasso (Tib shirani, 1996) p enalt y on the regression co efficien ts. T he DSPCA algo- rithm in (d ’Asp remon t et al., 2007) is an ℓ 1 -norm based semid efi nite relaxation for sp arse PCA. 6 Shen & Huang (2008 ) r esorted to the sin gular v alue decomp osition (SVD) to compute lo w-rank ma- trix approximat ions of the data matrix un der v arious sparsity- in ducing p enalties. Greedy searc h and br anc h-and-b ound metho d s were in vestig ated in (Moghaddam et al., 2006) to solve small in- stances of sparse P CA exactl y and to obtain approxima te solutions for larger scale problems. More recen tly , d’Asp remon t et al. (200 8 ) prop osed the use of greedy forwa r d selectio n with a certificate of optimalit y , and Journ´ ee et al. (2010) studied a generalized p o w er metho d to solv e spars e PCA with a certain dual r eformulation of the p roblem. In comparison, our metho d works directly in the primal domain, and the resulting algorithm is quite d ifferen t from that of Journ´ ee et al. (2010). Giv en a s amp le co v ariance matrix, Σ ∈ S p + (or equiv alen tly a cen tered d ata matrix D ∈ R n × p with n rows of p -dimensional observ ations vec tors suc h that Σ = D ⊤ D ) and the target cardin ality k , follo wing (Moghaddam et al. , 2006; d’Asp remon t et al., 2007, 2008), we formulate spars e PCA as: ˆ x = arg max x ∈ R p x ⊤ Σ x, sub ject to k x k = 1 , k x k 0 ≤ k . (4.1) The TPo w er metho d p rop osed in this pap er can b e directly app lied to solve the ab o v e p roblem. One adv antag e of TP o wer for Sparse PCA is that it d irectly addresses the constraint on cardin ality k . T o fin d the top m r ather than the top one sparse loading v ectors, a common approac h in the literature (d’Aspr emon t et al., 2007; Moghaddam et al., 2006; Mac k ey , 2008) is to use the iter ative deflation m etho d for PCA: subsequ ent sparse loading vec tors can b e obtained by recursive ly re- mo ving the cont r ibution of the previously foun d loading v ectors from the co v ariance matrix. Here w e employ a p ro jection deflation sc heme from (Mac k ey , 200 8 ), w hic h d eflates an vect or ˆ x using the form u la: Σ ′ = ( I p × p − ˆ x ˆ x ⊤ )Σ( I p × p − ˆ x ˆ x ⊤ ) . Ob v ious ly , Σ ′ remains p ositiv e semidefi n ite. Moreo v er, Σ ′ is rendered left and r igh t orthogonal to ˆ x . 4.1.1 Connection w ith Existing Sparse PCA Metho ds In the setup of sparse PCA, TP o we r is closely related to GP o we r (Journ´ ee et al., 2010) and sPCA-rSVD (S hen & Huan g, 2008) whic h are b oth p o we r -truncation-t yp e iterativ e algorithms. Indeed, GPo wer and sPCA-rSVD are identica l except for the initializatio n and p ost-pro cessing phases (Journ´ ee et al., 2010). Giv en a d ata matrix D ∈ R n × p , the ℓ 1 -norm v ersion of GPo w er (and equiv alen tly sPCA-rSVD) solv es the follo win g regularized rank-1 appro ximation problem: min x ∈ R p ,z ∈∈ R n k D − z x ⊤ k 2 F + γ k x k 1 , su b ject to k z k = 1 , while the ℓ 0 -norm v ersion of GPo w er (and sPCA-rSVD) solve s the follo win g optimization problem: min x ∈ R p ,z ∈∈ R n k D − z x ⊤ k 2 F + γ k x k 0 , su b ject to k z k = 1 . Giv en the cov ariance matrix Σ = D ⊤ D , it is easy to v erify that T Po w er optimizes the f ollo w ing constrained low-1 and semidefin ite approximati on problem min x ∈ R p k Σ − xx ⊤ k 2 F , su b ject to k x k = 1 , k x k 0 ≤ k . Essen tially , TP ow er, GPo w er and sPCA-rS VD all use certain p o wer-truncation t yp e pro cedure to generate sp ars e loadings. How ev er, th e difference b et we en TPo wer and GP o wer (sPCA-rS VD) is 7 also clea r : the former p erforms rank-1, semidefinite and sp arse ap p ro ximation to co v ariance matrix while the latter p erforms rank-1 and sparse appr o ximation to th e data matrix. On e imp ortan t b enefit of TPo w er is that w e are able to analyze solution qualit y s uc h as sparse reco v ery capabilit y , while analogous results are not a v ailable for GP o wer and sPCA-rSVD. Our metho d is also related to PathSPCA (d’Asp remon t et al., 2008) that directly addresses the form u lation (1.1). The PathSPCA metho d is a greedy f orw ard selectio n pro cedure whic h starts from the empt y set and at eac h iteratio n it selects the most relev ant v ariable and adds it to th e current v ariable set; it then r e-estimates the leading eigen v ector on th e augment ed v ariable set. Both TPo w er and Pa th SPCA outpu t sparse solutions with exact cardinalit y k . 4.1.2 On Initia lizat ion Theorem 1 suggests that the TP ow er algorithm can b enefit from a go o d initial v ector x 0 . In a practical imp lementat ion, the follo wing three initialization sc h emes can b e considered. 1: On e simple metho d is to set [ x 0 ] j = 1 on index j = arg max i [ A ] ii and 0 otherwise. Th is initializat ion pr o vides a 1 /k -appro ximation to the optimal v alue, i.e., Q ( x 0 ) ≥ λ max ( A, k ) /k . Indeed, if we let A ∗ k b e the k × k principle su b matrix of A su pp orted on sup p( x ∗ ), then it is easy to v erify that [ A ] j j ≥ T r( A ∗ k ) /k ≥ λ max ( A, k ) /k . In the setup of sp arse PC A, this corresp onds to initializing b y s electing the v ariable with the largest v ariance, whic h is kno w n to p erform we ll for PathSPCA (d’Aspremont et al., 2008). Alternativ ely , we m a y initialize x 0 as the indicator vect or of the top k v alues of the v ariances { [ A ] ii } , as is considered b y Amini & W ain wrigh t (2009). 2: A t wo-stag e warm-start strategy suggested at the end of Section 3. In th e fi rst stage we ma y run TPo w er w ith a relativ ely large k and use the output as the in itial v alue of the next s tage with a decreased k . Rep eat this p ro cedure if necessary until the desir ed cardinalit y is reac hed . More generally , one ma y use other algorithms to w arm start TPo w er. 3: When k ≈ p , an in itializa tion scheme s u ggested in (Moghaddam et al., 2006) can b e emplo y ed . This sc heme is m otiv ated f rom the follo wing obs er v ation: among all the m p ossible ( m − 1) × ( m − 1) principal submatrices of A m , obtained by deleting th e j -th ro w and column, th er e is at least one submatrix A m − 1 = A m \ j whose maximal eigen v alue is a ma jor f raction of its paren t (see, e.g., Horn & J oh n son, 1991): ∃ j ∈ { 1 , ..., m } , λ max ( A m \ j ) ≥ m − 1 m λ max ( A m ) . (4.2) A greedy backw ard elimination metho d is suggested using the ab ov e b ound (Moghaddam et al., 2006): start with the full index s et { 1 , ..., p } , and sequen tially delete the v ariable j which yields the maximum λ max ( A m \ j ) unt il only k elemen ts remain. It is immediate from the b ound (4.2 ) that this pro cedure will guaran tee a k /p -appr o ximation to the optimal ob jectiv e v alue. This sc heme works w ell f or relativ ely small p . When p is large, h o we ver, su c h a greedy initializa- tion sc heme will b e computationally prohibitiv e since it in volv es ( p − k ) p times of d ominan t eigen v alue calculatio n f or matrices of scale O ( p × p ). 4.1.3 Results on T o y Dat a set T o illustrate the sp arse reco v ering p erformance of TP ow er, we apply the algorithm to a syn th etic dataset dra w n from a sp arse PCA mo del. W e follo w th e same p ro cedure p rop osed b y (Shen & Huang, 8 2008) to generate random data with a co v ariance matrix ha ving sparse eigen v ectors. T o th is end , a co v ariance matrix is first synthesized through the eigenv alue d ecomp osition Σ = V D V ⊤ , where the fi r st m columns of V ∈ R p × p are pre-sp ecified sparse orthonormal v ectors. A data matrix X ∈ R n × p is then generated by dra w ing n samp les from a zero-mean normal d istr ibution with co v ariance matrix Σ , that is X ∼ N (0 , Σ). The emp irical co v ariance ˆ Σ matrix is then estimated from data X as the input for TPo w er. Consider a setup with p = 500, n = 50, and the first m = 2 domin ant eigen vect ors of Σ are sparse. Here the fir s t tw o dominan t eigen v ectors are sp ecified as follo ws: [ v 1 ] i = ( 1 √ 10 , i = 1 , ..., 10 0 , otherwise , [ v 2 ] i = ( 1 √ 10 , i = 11 , ..., 20 0 , otherwise . The remaining eigen v ectors v j for j ≥ 3 are chosen arbitrarily , and the eigen v alues are fixed at the follo wing v alues: λ 1 = 400 , λ 2 = 300 , λ j = 1 , j = 3 , ..., 500 . W e generate 500 data m atrices and emplo y the TPo w er to compute t wo unit-norm sparse load- ing v ectors u 1 , u 2 ∈ R 500 , whic h are h op efully close to v 1 and v 2 . Our metho d is compared on this d ataset with a greedy algorithm PathPCA (d’Aspr emont et al., 2008), a p o w er-iteration-t yp e metho d GPo wer (Journ´ ee et al., 2010), a sparse regression based metho d SPCA (Zou et al., 2006), and the standard PCA. F or GPo wer, we test its t wo blo c k ve r sions GPo w er ℓ 1 ,m and GP o wer ℓ 0 ,m with ℓ 1 -norm and ℓ 0 -norm p enalties, resp ectiv ely . Here we do not in vo lve t wo represen tativ e sparse PCA algorithms, the sPC A-rS VD (Sh en & Huang, 2008) and the DSPCA (d’Aspremont et al., 2007), in our comparison since the former is sho wn to b e iden tical to GPo wer u p to in itializa tion and p ost-pro cessing ph ases (Jour n ´ ee et al. , 2010), wh ile the latter is considered by the au th ors only as a second choic e after Pat h SPCA. All tested algorithms w ere implemented in Matlab 7.12 runn in g on a commo dity desktop. In this exp eriment, we r egard the true mo del to b e su ccessfully reco vered w h en b oth quan tities | v ⊤ 1 u 1 | and | v ⊤ 2 u 2 | are greater than 0 . 99. W e also assume that the cardinalit y k = 10 of the underlying sp arse eigen vec tors is kn o wn a p rior. T able 4.1 lists the reco v erin g resu lts by the tested metho ds. It can b e obs er ved that TPo w er, Pa thP CA and GPo wer all su ccessfully reco ver the ground truth sp arse PC vec tors with extremely high rate of success. SPCA fr equen tly fails to r eco v er the spares loadings on this dataset. T he p oten tial reason is that S P CA is in itialized with the ordinary principal comp onents w h ic h in man y random data matrices are far a wa y fr om the truth sparse solution. T raditional PCA alw a ys fails to reco v er the sp arse PC loadings on this dataset. The success of TP ow er and the failur e of traditional PCA can b e w ell explained b y our sp arse reco v ery result in T heorem 1 (for TPo w er) in comparison to the traditional eigenv ector p ertur bation theory in L emma 2 (for traditional PCA), which we hav e already discussed in Section 3. Ho w ever, the success of other metho ds suggests that it migh t b e p ossible to pro ve sparse r eco v ery results similar to Theorem 1 for some of these alternative algorithms. 4.1.4 Sp eed and Scaling T est T o s tu dy the computational efficiency of TPo w er, we list in T able 4.2 the CPU runnin g time (in seconds) by TP o wer on several datasets at different scales. The datasets are generalized as n × p 9 T able 4.1: Th e qu an titativ e results on a synt h etic d ataset. The v alues | u ⊤ 1 u 2 | , | v ⊤ 1 u 1 | , | v ⊤ 2 u 2 | are mean of the 500 ru nning. Algorithms P arameter | u ⊤ 1 u 2 | | v ⊤ 1 u 1 | | v ⊤ 2 u 2 | Probabilit y of su ccess TP ow er k = 10 0 0.9998 0.9997 1 P athSPC A k = 10 0 0.9998 0.9997 1 GP o wer ℓ 1 ,m γ = 0 . 8 0 0.9997 0.9996 0.99 GP o wer ℓ 0 ,m γ = 0 . 8 9 . 5 × 10 − 5 0.9997 0.9991 0.99 SPCA λ 1 = 10 − 3 2 . 4 × 10 − 3 0.9274 0.9250 0.25 PCA − 0 0.9146 0.9086 0 Gaussian random matrices with fixed n = 500, and exp onen tially increasing v alues of dimension p . W e set the termination criteria for TPo w er to b e k Q ( x t ) − Q ( x t − 1 ) k ≤ 10 − 4 . It can b e observed from T able 4.2 that TP ow er can exit within seconds or tens of seconds on all the datasets under a wider ran ge of cardinalit y k . T able 4.2: Av erage computational time for extracting one sparse comp onent (in seconds) by TP ow er under different setting of dimensionalit y p and cardinalit y k . n × p 500 × 1000 500 × 2000 500 × 4000 500 × 8000 500 × 16000 500 × 32000 k = 0 . 05 × p 0.07 0.13 0.39 0.88 2.52 7.03 k = 0 . 1 × p 0.07 0.14 0.55 1.00 3.31 20. 05 k = 0 . 2 × p 0.13 0.21 0.96 2.00 7.94 21. 78 k = 0 . 5 × p 0.12 0.43 2.06 5.08 19.63 25.19 4.1.5 Results on Pit Props Data The Pit p rops dataset (Jeffers, 1967), whic h consists of 180 observ ations with 13 measured v ariables, has b een a standard b enchmark to ev aluate algorithms for sp arse P C A (See, e.g., Zou et al., 2006; Shen & Huang, 2008; Journ´ ee et al. , 2010). F ollo wing th ese pr evious stu dies, we also consider to compute the first six s parse PCs of the data. In T able 4.3, we list th e total cardinalit y and the pro- p ortion of adjusted v ariance (Zou et al., 200 6 ) explained by six comp onent s computed with TP ow er, P athSPC A (d’Aspr emont et al., 2008), GP ow er (Journ´ ee et al., 2010) and SPCA (Zou et al., 2006). F rom these r esults we can see that on this relativ ely simple dataset, T P ow er, PathSPCA an d GP o wer p erform quite similarly . SPCA is inferior to the other three algorithms. T able 4.4 lists th e six extracted PCs b y TPo wer with cardinalit y setting 7-2-1- 1-1-1. W e can see that the imp ortan t v ariables asso ciated with the s ix pr incipal comp onents do not o verlap, whic h leads to a clear in terpr etation of th e extracted comp onents. T he s ame loadings are extracted by b oth PathSPCA and GPo w er und er the parameters listed in T able 4.3. 4.1.6 Results on Biological Data W e ha ve also ev aluated the p erformance of TP ow er on t wo gene expression datasets, one is the Colon cancer data from (Alon et al., 1999), the other is the Lymphoma data from (Alizadeh et al., 2000). 10 T able 4.3: The quan titativ e results on the PitProps dataset . The result of SPCA is tak en from (Zou et al., 2006). Metho d P arameters T otal cardinalit y Prop. of explained v ariance TP ow er cardinalities: 8-8-4-2 -2-2 26 0.8636 TP ow er cardinalities: 7-2-3-1 -1-1 15 0.8230 TP ow er cardinalities: 7-2-1-1 -1-1 13 0.7599 P athSPC A cardinalities: 8-8-4-2 -2-2 26 0.8615 P athSPC A cardinalities: 7-2-3-1 -1-1 15 0.8230 P athSPC A cardinalities: 7-2-1-1 -1-1 13 0.7599 GP o wer ℓ 1 ,m γ = 0 . 22 26 0.8438 GP o wer ℓ 1 ,m γ = 0 . 30 15 0.8230 GP o wer ℓ 1 ,m γ = 0 . 40 13 0.7599 SPCA see (Zou et al., 200 6 ) 18 0.7 580 T able 4.4: The extracted six PC s on PitProps dataset b y TPo wer with cardinalit y setting 7-2-1- 1- 1-1. Note that in this setting, the extracted six PCs are orthogonal and the significan t loadings are non-o ve r lapping. PCs x 1 topd x 2 length x 3 moist x 4 testsg x 5 o vensg x 6 ringt x 7 ringb x 8 bowm x 9 bowd x 10 whorls x 11 clear x 12 knots x 13 diaknot PC1 0.4235 0.4302 0 0 0 0.2680 0.4032 0.3134 0.3787 0.3994 0 0 0 PC2 0 0 0. 7071 0.7071 0 0 0 0 0 0 0 0 0 PC3 0 0 0 0 1 . 000 0 0 0 0 0 0 0 0 PC4 0 0 0 0 0 0 0 0 0 0 1.000 0 0 PC5 0 0 0 0 0 0 0 0 0 0 1.000 0 PC6 0 0 0 0 0 0 0 0 0 0 0 0 1.000 F ollo w in g th e exp erimental setup in (d’Asp r emon t et al., 2008), w e consider the 500 genes with the largest v ariances. W e plot the v ariance v ersu s cardinalit y tradeoff cur v es in Figure 4.1, together with the result from P athSPCA (d’Aspremon t et al., 2008) and the upp er b ounds of optimal v alues from (d’Asp remon t et al., 2008). Note that our m etho d p erforms almost ident ical to the P athSPCA whic h is demonstrated to hav e optimal or very close to optimal solutions in man y cardin alities. T he computational time of the t w o metho d s on b oth datasets is comparable and is less than tw o seconds. 4.1.7 Results on Do cumen t Dat a In this section we ev aluate the practical p erformance of TP ow er for k ey term s extraction on a do cument dataset 20 Newsgroups ( 20NG ). The 20NG 1 is a dataset collected and originally u sed for do cument classification b y Lang (1995). A total num b er of 18 , 846 do cum en ts, evenly distribu ted across 20 classes, are left after remo ving duplicates and n ewsgroup-identi f ying headers. This corpus con tains 26 , 214 distinct terms after s temmin g and stop w ord remo v al. Eac h do cum en t is then represent ed as a term-frequency vect or and n ormalized to one. W e u se the top 1,000 terms according to the DF (docum en t frequ ency) of the terms in the corpus. W e extract 5 sp arse PCs on this d ataset. The cardinalit y setting for the 5 s parse PCs is 20-20-10- 10-10. T able 4.5 lists the terms asso ciated 1 http://peo ple.csail.mit.edu/jrennie/ 2 0Newsgroups/ 11 0 100 200 300 400 500 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Cardinality Propotion of Explained Variance Sparse PCA TPower PathSPCA OptimalBound (a) Colon Cancer 0 100 200 300 400 500 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 Cardinality Propotion of Explained Variance Sparse PCA TPower PathSPCA OptimalBound (b) Lymphoma Figure 4.1: T he synthetic dataset and outlier remo v al result. F or b etter viewing, please see the original p df fi le. with the 1st, 2nd and 5th sparse PCs. Th e in terpr etation is quite clear: the 1st sparse PC is ab out figures, the 2nd is ab out compu ter science, and the 5th is on r eligion. W e hav e observed that quite similar terms are extracted by Pat h SPCA under the same cardinalit y setting. Here we do not list the 3rd and 4th PCs since they o v erlap with the listed ones due to the non-orthogonalit y of sp arse PCs. 4.1.8 Summary T o summarize this group of exp eriment s on sp arse PCA, the basic fin ding is that TPo wer p er- forms quite comp etitiv ely in te r ms of the trade-o ff b et wee n explained v ariance and represen- tation sparsity . Th e p erformance is comparable to Pat h SPCA (d’Aspremont et al., 2008) and GP o wer (Journ´ ee et al., 2010) b oth on the synthetic and on the real datasets. It is observed th at TP ow er, PathSPCA and GPo w er outp erform SP C A (Zou et al., 2006) on the b enc hmark d ata Pitp rops . Although p erforming quite similarly , TP ow er, P athSPC A and GP ow er are d ifferen t algo- rithms: TPo w er is a p o wer iteratio n metho d wh ile P athSPCA is a greedy forw ard selection metho d, b oth directly address the cardinalit y constrained sparse eigen v alue problem (1.1), while GPo w er is a p o wer iteration metho d for certain regularized v ers ions of sparse eige nv alue problem (see the pre- vious Section 4.1.1). Wh ile strong theoretical guaran tee can b e established for the TP o wer metho d , it remains op en to sh ow th at Pa th SPCA and GP o we r ha ve a similar sparse reco v ery p erformance. 4.2 Densest k -Subgrap h Finding As another concrete app lication, w e sh o w th at with pr op er m o dification, TP ow er can b e applied to the den s est k -subgraph fi nding prob lem. Giv en an un directed graph G = ( V , E ), | V | = n , and integ er 1 ≤ k ≤ n , the densest k -sub graph (DkS) problem is to fi nd a set of k vertice s with maxim um a verage d egree in the subgraph in duced b y th is set. In the we ighted v ersion of DkS we are also giv en nonn egativ e weig hts on th e edges an d the goal is to fin d a k -vertex indu ced sub graph of 12 T able 4.5: T erms asso ciated with the first 1st, 2nd, 5th sp ars e PCs. Dataset: 20NG . 1st PC (20 terms) 2nd P C (20 terms) 5th PC (10 terms) “1” “edu” “don t” “2” “system” “time” “3” “inform” “p eople” “4” “includ” “b eliev” “5” “supp ort” “god ” “10” “program” “exist” “20” “ve r sion” “c hristan” “15” “set” “jesus” “8” “windo w” “c hr ist” “6” “soft w ar” “atheist” “16” “a v ail” “12” “ fi le” “14” “data” “7” “user” “18” “grafic” “9” “color” “13” “imag” “11” “displai” “0” “format” “la” “ftp” maxim um a verag e edge we ight. Algorithms for finding DkS are useful to ols for analyzing net wo r ks. In p articular, they hav e b een us ed to select features for ran k in g (Geng et al., 2007), to iden tify cores of comm unities (Kumar et al., 1999), and to com b at link spam (Gibson et al., 2005). It has b een sho w n that the DkS problem is NP hard for bipartite graphs and chordal graphs (Corneil & P erl, 1984), and even for graphs of maximum degree thr ee (F eige et al., 200 1 ). A large b o dy of algo r ithms ha ve b een prop osed based on a v ariet y of tec hn iques including greedy algorithms (F eige et al. , 2001 ; Asahiro et al., 2002; Ra vi et al. , 1994), linear programming (Billionnet & Roupin, 2004; Khuller & Saha, 2009), and s emid efinite p rogramming (Sriv asta v & W olf, 1998; Y e & Zhang, 2003). F or general k , the algorithm dev elop ed by F eige et al. (2001) ac hiev es the b est appro ximation ratio of O ( n ǫ ) w here ǫ < 1 / 3. Ra vi et al. (1994) prop osed 4-appro ximation algorithms for weigh ted DkS on complete graphs for whic h the weigh ts satisfy the triangle in equalit y . Liazi et al. (2008) has pr esen ted a 3-appro ximation algorithm for DkS f or c hord al graphs. Recen tly , Jiang et al. (2010) p rop osed to reformulat e DkS as a 1-mean clusterin g p roblem and deve lop ed a 2-appr o ximation to the re- form u lated clustering problem. Moreo ver, based on this reform ulation, Y ang (2010) pr op osed a 1 + ǫ -appr oximati on algorithm with certain exhaustive (and thus exp ensiv e) initialization p ro ce- dure. In general, how ev er, Kh ot (2006) sh o wed that DkS has no p olynomial time appr o ximation sc heme (PT AS), assuming that there are no su b-exp onential time algo r ithms for pr oblems in NP . Mathematica lly , DkS can b e restated as the follo wing binary qu adratic programming p roblem: max π ∈ R n π ⊤ W π , sub ject to π ∈ { 1 , 0 } n , k π k 0 = k , (4.3) 13 where W is the (non-negativ e w eigh ted) adjacency matrix of G . If G is an undirected graph, then W is symmetric. If G is directed, then A could b e asymm etric. In this latter case, from the fact that π ⊤ W π = π ⊤ W + W ⊤ 2 π , we may equiv alen tly solve Pr oblem (4.3) by replacing W with W + W ⊤ 2 . Therefore, in the follo wing discuss ion, we alw a ys assume th at the affin it y matrix W is symm etric (or G is und irected). 4.2.1 The TP ow er-DkS Algorithm W e pr op ose the TPo w er-DkS algorithm as a sligh t m o dification of TPo wer, to s olv e the DkS prob- lem. The pro cess generates a sequence of in termediate ve ctors π 0 , π 1 , ... from a starting vect or π 0 . A t eac h step t the v ector π t − 1 is multiplied by the matrix W , then π t is set to b e the ind icator v ector of the top k entries in W π t − 1 . The T Po w er-Dks is form ally giv en in Algorithm 2. Algorithm 2: T ru ncated P ow er Metho d for DkS (TP ow er-DkS) Input : W ∈ S n + ,, initial v ector π 0 ∈ R n Output : π t P arameters : cardinalit y k ∈ { 1 , ..., n } Let t = 1. rep eat Compute π ′ t = W π t − 1 . Iden tify F t = su pp( π ′ t , k ) the ind ex set of π ′ t with top k v alues. Set π t to b e 1 on the index set F t , and 0 otherwise. t ← t + 1. un til Conver genc e ; Remark 4. By r elaxing the c onstr aint π ∈ { 0 , 1 } n to k π k = √ k , we may c onvert the densest k -sub gr aph pr oblem (4.3) to the standar d sp arse eigenvalue pr oblem (1.1) (up to a sc aling) and then dir e ctly apply TPower (in Algorithm 1) for solution. Our numeric al exp erienc e shows that such a r elaxation str ate gy also works satisfactory in pr actic e, although is slightly infe rior to TPower-DkS (in Algorithm 2) which dir e ctly addr esses the original pr oblem. Note that in Algorithm 2 we require that W is p ositiv e semidefinite. The motiv ation of this requirement is to guarant ee the conv exit y of the ob jectiv e in problem (4.3), and thus follo win g the similar arguments in (Journ ´ ee et al., 2010) it can b e sho wn that the ob jectiv e v alue will b e monotonically increasing du ring the iterations. In many r eal-w orld DkS p roblems, ho wev er, it is often the case that the affinit y matrix W is not p ositiv e s emi-definite. In this case, the ob jectiv e is non-con ve x and thus th e monotonicit y of TPo w er-DkS do es not hold. Ho w ever, this complication can b e circumv en ted by in s tead ru nning the algorithm with the shifted quadr atic function: max π ∈ R n π ⊤ ( W + ˜ λI p × p ) π , sub ject to π ∈ { 0 , 1 } n , k π k 0 = k . where ˜ λ > 0 is large enough s u c h th at ˜ W = W + ˜ λI p × p ∈ S n + . On the d omain of in terest, this c hange only adds a constan t term to the ob jectiv e function. Th e TPo w er-DkS, h o wev er, pro d u ces a differen t sequence of iterates, and ther e is a clear trade-off. If th e second term dominates the first term (sa y b y c h o osing a very large ˜ λ ), the ob jectiv e fu n ction b ecomes appr oximate ly a squared norm, and 14 the algorithm tends to terminate in ve r y few iterations. In the limiting case of ˜ λ → ∞ , the metho d will n ot mo ve aw a y from th e in itial iterate. T o hand le this iss ue, w e prop ose to gradually in crease ˜ λ during the iterations and we do s o only when the monotonicit y is violated. T o b e p recise, if at a time instance t , π ⊤ t W π t < π ⊤ t − 1 W π t − 1 , then we add ˜ λI p × p to W with a gradually increased ˜ λ by rep eating the current iteration w ith the up dated matrix u n til π ⊤ t ( W + ˜ λI p × p ) π t ≥ π ⊤ t − 1 ( W + λI p × p ) π t − 1 2 , whic h implies π ⊤ t W π t ≥ π ⊤ t − 1 W π t − 1 . 4.2.2 On Initia lizat ion Since TP ow er-DkS is a monotonically increasing p ro cedure, it guaran tees to improv e the initial p oint π 0 . Basically , any existing appro ximation DkS m etho d, e.g., greedy algorithms (F eige et al., 2001; Ravi et al., 1994), can b e used to initialize TPo w er-DkS. In our numerical exp erimen ts, we observ e that by simply setting π 0 as the indicator vect or of the ve r tices w ith the top k (weigh ted) degrees, our metho d can ac h iev e v ery comp etitiv e results on all the real-w orld datasets w e ha ve tested on. 4.2.3 Results on W eb Graphs W e hav e tested T P ow er on fou r page-lev el w eb graphs: cnr-20 00 , amazon-2008 , ljournal -2008 , hollyw o o d-200 9 , f r om the W ebGraph framew ork provided by th e Lab oratory for W eb Algorithms 3 . W e treated eac h d irected arc as an undir ected edge. T able 4.6 lists the statistics of the datasets used in the exp eriment. T able 4.6: The statistics of the w eb graph datasets. Graph No des ( | V | ) T otal Ar cs ( | E | ) Average Degree cnr-2000 325,55 7 3,216, 152 9.88 amazon-2008 735,32 3 5,158,3 88 7.02 ljournal-2008 5,363, 260 79 ,023,142 14.73 hollyw o o d-200 9 1,139, 905 113,89 1,327 99.9 1 W e compare our T P ow er-DkS metho d with t wo greedy m etho ds for the DkS problem. One greedy metho d is p rop osed by Ra vi et al. (1994) whic h is referr ed to as Gr eedy-Ra vi in our exp eri- men ts. The Greedy-Ra vi algorithm works as follo ws: it starts from a hea viest ed ge and rep eatedly adds a v ertex to the curr en t s u bgraph to maximize the wei ght of the r esulting n ew subgrap h ; this pro cess is rep eated u nt il k v ertices are c hosen. The other greedy metho d is dev elop ed b y F eige et al. (2001, Pr o cedure 2) which is referred as Greedy-F eige in our exp erimen ts. Th e pro cedur e works as follo ws: let S denote th e k / 2 ve r tices with the highest degrees in G ; let C denote the k / 2 v ertices in the remaining v ertices with largest num b er of neigh b ors in S ; r eturn S ∪ C . Figure 4.2 shows the d ensit y v alue π ⊤ W π /k and CPU time v ersu s the cardinalit y k . F rom the d en sit y curves w e can observe that on cnr-2000 , ljournal-2008 and hollywoo d-2009 , TPo w er- DkS consisten tly outp uts denser subgraph s than the t wo greedy algorithms, while on amaz on-2008 , TP ow er-DkS and Greedy-Ra vi are comparable and b oth are b etter than Greedy-F eige. F or CPU 2 Note t h at th e inequality π ⊤ t ( W + ˜ λI p × p ) π t ≥ π ⊤ t − 1 ( W + ˜ λI p × p ) π t − 1 is deemed to b e satisfied when ˜ λ is large enough, e.g., when W + ˜ λI p × p ∈ S n + . 3 Datasets are av ailable at http://lae .dsi.unimi.it/data set s.php 15 runn in g time, it can b e seen from the right column of Figure 4.2 that Greedy-F eige is the fastest among the three metho d s while TP ow er-DkS is only s lightly slo we r . This is due to the fact that TP ow er-DkS n eeds iterativ e m atrix-v ector pr o ducts while Greedy-F eige only needs a few degree sorting outputs. Although TPo w er-DkS is slightly slow er than Greedy-F eig e, it is still qu ite efficien t. F or example, on hollyw o o d-200 9 wh ic h has hundreds of millions of arcs, for eac h k , Greedy-F eige terminates within ab out 1 s econd while TPo wer terminates within ab out 10 seconds. The Greedy- Ra vi metho d is ho wev er muc h slo w er than the other tw o on all the graph s wh en k is large. 4.2.4 Results on Air-T ra vel Routine W e hav e ap p lied TP ow er-DkS to identify su bsets of American and C anadian cities that are most easily connected to eac h other, in terms of estimated commercial airline tra vel time. T h e graph 4 is of size | V | = 456 and | E | = 71 , 959: the v ertices are 456 bu siest commercial airp orts in United States and Canada, wh ile the weigh t w ij of edge e ij is set to the in verse of the mean time it take s to trav el from city i to cit y j b y airline, in cluding estimated stop o v er dela ys. Due to th e h eadwind effect, the trans it time can dep end on th e direction of trav el; thus 36% of the w eigh t are asymmetric. Figure 3(a) sho ws a map of air-tra v el routin e. As in the p r evious exp erimen t, w e compare TPo w er-DkS to Greedy-Ra vi and Greedy-F eige on this dataset. F or all the thr ee algorithms, the d en sities of k -subgraphs under different k v alues are sho wn in Figure 3(b), and the CPU runn ing time curves are giv en in Figure 3(c). F rom the former figure we observe th at TP ow er-DkS consisten tly outp erforms the other t wo greedy algorithms in terms of the dens ity of the extracted k -subgraphs . F rom the latter figure w e can see that T P ow er- DkS is sligh tly slo wer than Greed-F eige but m u ch faster than Greedy-Ra vi. Figure 3(d),3(e), and 3(f ) illustr ate the dens est k -subgraph with k = 30 outputted by the three algorithms. In eac h of these th r ee subgrap h , the red dot in dicates the representing cit y with the largest (we ighted) d egree. Both TPo wer-DkS and Gr eedy-F eige rev eal 30 cities in east US. Th e former tak es Cleveland as the represent in g cit y while the latter Cincinnati . Greedy-Ra vi rev eals 30 cities in w est US and CA and tak es V anc ouver as the represen ting cit y . Visu al insp ection shows that the subgraph reco v ered by TP ow er-DkS is the d ensest among the three. After disco vering the densest k -sub graph, we can eliminate their n o des and edges from the graph and then apply the algorithms on the reduced graph to searc h for the n ext d ensest sub graph. Suc h a sequentia l pro cedure can b e rep eated to find m ultiple densest k -sub grap h s. Figure 3(g),3(h), and 3(i) illustrate sequen tially estimated six densest 30-subgraphs b y the three algorithms. Again, visual insp ection shows that our metho d output more geographically compact subsets of cities than the other t wo . As a qu an titativ e r esult, the total density of the six subgraphs d isco v ered by the three algorithms is: 1.14 (TPo w er-DkS), 0.90 (Greedy-F eige) and 0.99 (Greedy-Ra vi), resp ectiv ely . 5 Conclusion and F uture W ork The sp arse eigen v alue problem h as b een widely stud ied in machine learning with app lications such as sparse PCA. TPo w er is a trun cated p ow er iteration metho d that app r o ximately solves the non- con v ex sparse eigen v alue problem. Our analysis sho ws that when the underlying matrix has sparse eigen v ectors, under prop er conditions TPo w er can appro ximately reco ver the true sparse solution. The theoretical b enefit of this metho d is that with app r opriate initializat ion, the reconstruction 4 The d ata is av ailable at www.psi .toronto.edu/affin itypropogation 16 0 2000 4000 6000 8000 10000 0 10 20 30 40 50 60 70 Cardinality Density Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige 0 2000 4000 6000 8000 10000 10 −2 10 −1 10 0 10 1 10 2 10 3 Cardinality CPU Time (Sec.) Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige (a) cnr-2000 0 2000 4000 6000 8000 10000 3 4 5 6 7 8 9 Cardinality Density Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige 0 2000 4000 6000 8000 10000 10 −1 10 0 10 1 10 2 10 3 Cardinality CPU Time (Sec.) Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige (b) amazon-2008 0 2000 4000 6000 8000 10000 0 50 100 150 200 250 Cardinality Density Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige 0 2000 4000 6000 8000 10000 10 0 10 1 10 2 10 3 10 4 Cardinality CPU Time (Sec.) Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige (c) ljournal-2008 0 2000 4000 6000 8000 10000 0 500 1000 1500 2000 Cardinality Density Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige 0 2000 4000 6000 8000 10000 10 −1 10 0 10 1 10 2 10 3 10 4 Cardinality CPU Time (Sec.) Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige (d) hollywood- 2009 Figure 4.2: I den tifyin g den s est k -su bgraph on four we b graphs . Left: densit y cur ves as a fu nction of k . Righ t: CPU time curve s as a function of k . 17 (a) The air-tra vel route map 0 50 100 150 200 250 300 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Cardinality Density Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige (b) Den sity 0 50 100 150 200 250 300 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Cardinality Density Densest k−Subgraph TPower Greedy−Ravi Greedy−Feige (c) CPU Time (d) TP ow er-Dk S (e) Greedy-R a v i (f ) Greedy-F eige (g) TPo w er-D k S (h) Greedy-R a v i (i) Greedy- F eige Figure 4.3: Iden tifying d ensest k -subgraph of air-trav el routing. R ow 1: Ro u te map, and the densit y and C P U time ev olving cu r v es. Ro w 2: T he dens est 30-subgraph disco vered by the three algorithms. Row 3: S equen tially disco v ered six densest 30-subgraph b y the three algorithms. qualit y dep en d s on the restricted m atrix p ertur bation error at size s that is comparable to th e sparsit y ¯ k , instead of the full matrix d imension p . This explains why this metho d h as go o d emp ir- ical p erf ormance. T o our kno w ledge, this is the fir st th eoretical result of this kind , although our empirical stud y suggests that it migh t b e p ossib le to prov e related sparse reco v ery r esults for some other algorithms w e ha ve tested. W e ha v e applied TPo wer to t wo concrete applications: sparse PCA and the densest k -subgraph finding problem. Extensiv e exp erimen tal results on synthetic and real-w orld datasets v alidate the effectiv eness and efficiency of the TP o wer algorithm. 18 References Alizadeh, A., Eisen, M., Da vis, R., Ma, C., Lossos, I., and Rosenw ald, A. Distinct t yp es of diffuse large b-cell lymphoma identified by gene expression profilin g. Natur e , 403:503 –511, 2000. Alon, A., Bark ai, N., Notterman, D. A., Gish, K., Ybarra, S., Mac k, D., and Levine, A. J. Broad patterns of gene expression rev ealed by clustering analysis of tu mor and normal colon tissues prob ed by oligon ucleotide arra ys . Cel l Biolo gy , 96:6745–67 50, 1999. Amini, A. A. and W ainwrigh t, M. J. High-dim en sional analysis of semidefin ite relaxiatio n for sparse principal comp onen ts. Annals of Statistics , 37:2877–29 21, 2009. Asahiro, Y., Hassin, R., and Iw ama, K . Complexit y of finidng dense sub graphs. Di scr e te Appl. Math. , 211(1-3): 15–26, 2002. Billionnet, A. and Roup in, F. A deterministic algorithm for the densest k-sub graph problem using linear programming. T ec hn ical rep ort, T ec hnical Rep ort, No. 486 , CEDRIC, CNAM-I IE, P aris, 2004. Candes, Emmanuel J . and T ao, T erence. Decodin g by linear p rogramming. IEEE T r ans. on Information The ory , 51:4203–4 215, 2005. Corneil, D. G. and P erl, Y. Clustering and domination in p erfect graphs. Discr ete Appl. Math. , 9: 27–39 , 1984. d’Aspremont, A., Ghaoui, L. El, Jord an, M. I., an d Lanc kriet, G. R. G. A dir ect form ulation for sparse p ca u sing semidefin ite programming. Siam R eview , 49:434–4 48, 2007. d’Aspremont, A., Bac h , F., and Ghaoui, L. El. Optimal solutions for sparse prin cipal comp onent analysis. Journal of Machine L e arning R ese ar ch , 9:1269–1 294, 2008. F eig e, U., K ortsarz, G., and P eleg, D. The dens e k -subgraph problem. Algorithmic a , 29(3):4 10–421, 2001. Geng, X., Liu, T., Qin, T., and Li, H. F eature selection f or ranking. In Pr o c e e dings of SIGIR’07 , 2007. Gibson, D., Kumar, R., and T omkins, A. Disco v ering large dense subgraph s in massive graphs. In Pr o c e e dings of the 31st International Confer enc e on V ery L ar ge Data Bases (VLD B05) , pp. 721–7 32, 2005. Golub, G.H. and V an Loan, C .F. Matrix c omputations . Johns Hopkins Univ ersity Press, Baltimore, MD, third edition, 1996. Horn, R.A. and Johnson, C.R. T opics in M atrix Anal ysis . Canbridge Univ ersity Press, 1991 . Jeffers, J. Tw o case studies in the app lication of principal comp onents. Appl i e d Statistics , pp. 225–2 36, 1967. Jiang, P ., P en g, J., Heath, M., and Y ang, R. Finding densest k-su bgraph v ia 1-mean clustering and lo w -dimension appro ximation. T ec hnical rep ort, 2010. 19 Johnstone, I. M. On the distribution of the largest eigen v alue in p rincipal comp onen ts analysis. Anna ls of Statistics , 29:295–32 7, 2001. Jolliffe, I. T., T rendafilo v, N. T., and Uddin, M. A mo dified p rincipal comp onen t tec h nique based on the lasso. J. Comput.Gr aph.Statist. , p p. 531–547, 2003. Journ´ ee, Mic hel, Nesterov, Y urii, Rich t´ arik, P eter, and Sepulc h r e, Ro d olph e. Generalized p o w er metho d f or sp arse p rincipal comp onent analysis. J ournal of M achine L e arning R ese ar ch , 11: 517–5 53, 2010. Khot, S. Ruling out ptas for graph min-bisection, dens e k-su b graph, and bipartite clique. SIAM J. Comput. , 36(4):1025– 1071, 2006. Kh u ller, S. and Saha, B. On fi n ding dens e subgraph s. In Pr o c e e dings of the 36th International Col lo quium on Automata, L anguages and Pr o gr amming (ICALP’09) , p p . 597–608 , 2009. Kumar, R., Ragha v an, P ., Ra jagopala n , S., and T omkins, A. T ra wlin g the w eb for emerging cyb er- comm unities. In Pr o c e e dings of the 8th W orld Wide Web Confer enc e (W W W’99) , pp. 403–4 10, 1999. Lang, K. Newsw eeder: Leanring to filter netnews. In International Confer enc e on M achine L e arn- ing , pp. 331– 339, 1995. Liazi, M., Milis, I., and Zissimop oulos, V. A constan t approximati on algorithm for the densest k-subgraph pr oblem on chordal graphs. Information Pr o c essing L etters , 108(1):29 –32, 2008. Mac k ey , L. Deflation m etho ds for s p arse p ca. In NIPS , 2008. Moghaddam, B., W eiss, Y., and Avidan, S. Generalized sp ectral b ound s f or sp arse lda. In ICML , pp. 641–64 8, 2006. Ra vi, S. S ., Rosenkran tz, D. J., and T a yi, G. K. Heur istic and sp ecial case algo r ithms for disp er s ion problems. Op er. R es. , 42:2 99–310, 1994. Shen, H. and Huang, J. Z . Spars e principal comp onen t analysis via regularized low rank matrix appro ximation. Journal of M ultivariate Analysis , 99(6):1015– 1034, 2008. Sriv asta v, A. and W olf, K. Finding dense subgraphs with semidefinite p rogramming. In Pr o c. International Workshop Appr ox. , pp. 181–1 91, 1998. Tibshirani, R. Regression shrin k age and selection via the lasso. Journal of the R oyal Statistic al So cie ty. Series B , 58:2 67–288, 1996. Y ang, R. New appro ximation m etho ds for solving binary quadratic programming problem. T ec h- nical rep ort, Master Thesis, Department of Indu strial and Enterprise Sy s tems Engineering, Uni- v ersity of Illnois at Urbana-Ch ampaign, 2010. Y e, Y. Y. and Zhang, J. W. App ro ximation of d ense-n/2-subgraph and th e complemen t of m in- bisection. J. Glob al Optimization , 25:55–73, 2003. Zou, H., Hastie, T ., and Tibshirani, R. S p arse pr incipal comp onent analysis. Journal of Computa- tional and Gr aph ic al Statistics , 15(2):265– 286, 2006. 20 App endix A Pro of of T heorem 1 W e state the follo wing standard result fr om the p erturbation th eory of sym metric eigen v alue prob- lem. It can b e found for example in (Golub & V an Loan, 1996). Lemma 1. If B and B + U ar e p × p symmetric matric es, then ∀ 1 ≤ k ≤ p , λ k ( B ) + λ p ( U ) ≤ λ k ( B + U ) ≤ λ k ( B ) + λ 1 ( U ) , wher e λ k ( B ) denotes the k -th lar gest eigenvalue of matrix B . Lemma 2. Consider set F such that su pp ( ¯ x ) ⊆ F with | F | = s . If ρ ( E , s ) ≤ ∆ λ/ 2 , then the r atio of the se c ond lar gest (in absolute value) to the lar gest eigenvalue of sub matrix A F is no mor e than γ ( s ) . Mor e over, k ¯ x ⊤ − x ( F ) k ≤ δ ( s ) := √ 2 ρ ( E , s ) p ρ ( E , s ) 2 + (∆ λ − 2 ρ ( E , s )) 2 . Pr o of. W e m a y use Lemma 1 with B = ¯ A F and U = E F to obtain λ 1 ( A F ) ≥ λ 1 ( ¯ A F ) + λ p ( E F ) ≥ λ 1 ( ¯ A F ) − ρ ( E F ) ≥ λ − ρ ( E , s ) and ∀ j ≥ 2, | λ j ( A F ) | ≤ | λ j ( ¯ A F ) | + ρ ( E F ) ≤ λ − ∆ λ + ρ ( E , s ) . This imp lies the fi rst statemen t of th e lemma. No w let x ( F ), the largest eigen vecto r of A F , b e α ¯ x + β x ′ , where k ¯ x k 2 = k x ′ k 2 = 1, ¯ x ⊤ x ′ = 0 and α 2 + β 2 = 1, with eigen v alue λ ′ ≥ λ − ρ ( E , s ). This implies that αA F ¯ x + β A F x ′ = λ ′ ( α ¯ x + β x ′ ) , implying αx ′⊤ A F ¯ x + β x ′⊤ A F x ′ = λ ′ β . That is, | β | = | α | x ′⊤ A F ¯ x λ ′ − x ′⊤ A F x ′ ≤ | α | | x ′⊤ A F ¯ x | λ ′ − x ′⊤ A F x ′ = | α | | x ′⊤ E F ¯ x | λ ′ − x ′⊤ A F x ′ ≤ t | α | , where t = ρ ( E , s ) / (∆ λ − 2 ρ ( E , s )). This implies th at α 2 (1 + t 2 ) ≥ α 2 + β 2 = 1, and thus α 2 ≥ 1 / (1 + t 2 ). Without loss of generalit y , we ma y assume that α > 0, b ecause otherwise w e can replace ¯ x with − ¯ x . It follo ws that k x ( F ) − ¯ x k 2 = 2 − 2 x ( F ) ⊤ ¯ x = 2 − 2 α ≤ 2 √ 1 + t 2 − 1 √ 1 + t 2 ≤ 2 t 2 1 + t 2 . This imp lies the d esired b ound. The follo win g resu lt measures the progress of un tru n cated p ow er metho d . 21 Lemma 3. L et y b e the eigenve ctor with the lar gest (in absolute value) eige nvalue of a symmetric matrix A , and let γ < 1 b e the r atio of the se c ond lar gest to lar gest eigenvalue in absolute values. Given any x such that k x k = 1 and y ⊤ x > 0 ; let x ′ = Ax/ k Ax k , then | y ⊤ x ′ | ≥ | y ⊤ x | [1 + (1 − γ 2 )(1 − ( y ⊤ x ) 2 ) / 2] . Pr o of. Without loss of generalit y , we ma y assum e that λ 1 ( A ) = 1 is the largest eigen v alue in absolute v alue, and | λ j ( A ) | ≤ γ wh en j > 1. W e can d ecomp ose x as x = αy + β y ′ , where y ⊤ y ′ = 0, k y k = k y ′ k = 1, and α 2 + β 2 = 1. Th en | α | = | x ⊤ y | . Let z ′ = Ay ′ , then k z ′ k ≤ γ and y ⊤ z ′ = 0. This means Ax = αy + β z ′ , and | y ⊤ x ′ | = | y ⊤ Ax | k Ax k = | α | p α 2 + β 2 k z ′ k 2 ≥ | α | p α 2 + β 2 γ 2 = | y ⊤ x | p 1 − (1 − γ 2 )(1 − ( y ⊤ x ) 2 ) ≥| y ⊤ x | [1 + (1 − γ 2 )(1 − ( y ⊤ x ) 2 ) / 2] . The last inequalit y is due to 1 / √ 1 − z ≥ 1 + z / 2 for z ∈ [0 , 1). This p ro ves the d esired b oun d. Lemma 4. Consider ¯ x with supp ( ¯ x ) = ¯ F and ¯ k = | ¯ F | . Cons i der y and let F = supp ( y , k ) b e the indic es of y with the lar gest k absolute values. If k ¯ x k = k y k = 1 , then | T runc ate ( y , F ) ⊤ ¯ x | ≥ | y ⊤ ¯ x | − ( ¯ k /k ) 1 / 2 min h 1 , (1 + ( ¯ k /k ) 1 / 2 ) (1 − ( y ⊤ ¯ x ) 2 ) i . Pr o of. Without loss of generalit y , w e assu m e that y ⊤ ¯ x = ∆ > 0. W e can also assum e that ∆ ≥ p ¯ k / ( ¯ k + k ) b ecause otherw ise the right hand side is smaller than zero, and th us the result holds trivially . Let F 1 = ¯ F \ F , and F 2 = ¯ F ∩ F , and F 3 = F \ ¯ F . Now, let ¯ α = k ¯ x F 1 k , ¯ β = k ¯ x F 2 k , α = k y F 1 k , β = k y F 2 k , and γ = k y F 3 k . let k 1 = | F 1 | , k 2 = | F 2 | , and k 3 = | F 3 | . I t follo ws th at α 2 /k 1 ≤ γ 2 /k 3 . Therefore ∆ 2 ≤ [ ¯ αα + ¯ β β ] 2 ≤ α 2 + β 2 ≤ 1 − γ 2 ≤ 1 − ( k 3 /k 1 ) α 2 . This imp lies that α 2 ≤ ( k 1 /k 3 )(1 − ∆ 2 ) ≤ ( ¯ k /k )(1 − ∆ 2 ) ≤ ∆ 2 , (A.1) where the second inequalit y follo ws f rom ¯ k < k and the last inequalit y follo ws fr om the assumption ∆ ≥ p ¯ k / ( ¯ k + k ). No w b y solving th e follo wing inequalit y for ¯ α : α ¯ α + p 1 − α 2 p 1 − ¯ α 2 ≥ α ¯ α + β ¯ β ≥ ∆ ≥ α ≥ α ¯ α, w e obtain that ¯ α ≤ α ∆ + p 1 − α 2 p 1 − ∆ 2 ≤ min h 1 , α + p 1 − ∆ 2 i ≤ min h 1 , (1 + ( ¯ k /k ) 1 / 2 ) p 1 − ∆ 2 i , (A.2) where the second inequalit y follo ws from the Cauch y-Sc hw artz inequality and ∆ ≤ 1, √ 1 − α 2 ≤ 1, while the last inequalit y follo ws from (A.1 ). Fin ally , | y ⊤ ¯ x | − | T run cate( y, F ) ⊤ ¯ x | ≤ | ( y − T run cate( y , F )) ⊤ ¯ x | ≤ α ¯ α ≤ ( ¯ k /k ) 1 / 2 min h 1 , (1 + ( ¯ k /k ) 1 / 2 ) (1 − ( y ⊤ ¯ x ) 2 ) i , where the last inequalit y follo ws from (A.1) and (A.2 ). Th is leads to the desired b ound . 22 Next is our main lemma, w hic h sa ys eac h step of sparse p ow er metho d impr o ve s eigen ve ctor estimation. Lemma 5. L et s = 2 k + ¯ k . We have | ˆ x ⊤ t ¯ x | ≥ ( | x ⊤ t − 1 ¯ x | − δ ( s ))[1 + (1 − γ ( s ) 2 )(1 − ( | x ⊤ t − 1 ¯ x | − δ ( s )) 2 ) / 2] − δ ( s ) − ( ¯ k /k ) 1 / 2 . If | x ⊤ t − 1 ¯ x | > 1 / √ 3 + δ ( s ) , then q 1 − | ˆ x ⊤ t ¯ x | ≤ µ 2 q 1 − | x ⊤ t − 1 ¯ x | + √ 5 δ ( s ) . Pr o of. Let F = F t − 1 ∪ F t ∪ sup p( ¯ x ). Consid er the follo w in g v ector ˜ x ′ t = A F x t − 1 / k A F x t − 1 k , (A.3) where A F denotes the r estriction of A on the rows and columns indexed by F . W e note that replacing x ′ t with ˜ x ′ t in Algorithm 2 d o es not affect the output iteration sequence { x t } b ecause of the sparsity of x t − 1 and the f act that the truncation op eration is inv arian t to scaling. T h erefore for notation simplicit y , in the follo wing p ro of w e will simply assu m e th at x ′ t is redefin ed as x ′ t = ˜ x ′ t according to (A.3 ). Based on the ab ov e notation, w e ha v e | x ′⊤ t x ( F ) | ≥ | x ⊤ t − 1 x ( F ) | [1 + (1 − γ ( s ) 2 )(1 − ( x ⊤ t − 1 x ( F )) 2 ) / 2] ≥ ( | x ⊤ t − 1 ¯ x | − δ ( s ))[1 + (1 − γ ( s ) 2 )(1 − ( | x ⊤ t − 1 ¯ x | − δ ( s )) 2 ) / 2] , where the first in equalit y follo ws fr om Lemma 3, and th e second is from Lemma 2 and | x ⊤ t − 1 ¯ x | ≥ | x ⊤ t − 1 x ( F ) | − δ ( s ), and the fact that x (1 + (1 − γ 2 )(1 − x 2 ) / 2) is increasing when x ∈ [0 , 1]. W e can no w use Lemma 2 again, and the pr eceding inequalit y implies that | x ′⊤ t ¯ x | ≥ ( | x ⊤ t − 1 ¯ x | − δ ( s ))[1 + (1 − γ ( s ) 2 )(1 − ( | x ⊤ t − 1 ¯ x | − δ ( s )) 2 ) / 2] − δ ( s ) . Next we can apply Lemm a 4 to obtain | ˆ x ⊤ t ¯ x | ≥ | x ′ t ⊤ ¯ x | − ( ¯ k /k ) 1 / 2 ≥ ( | x ⊤ t − 1 ¯ x | − δ ( s ))[1 + (1 − γ ( s ) 2 )(1 − ( | x ⊤ t − 1 ¯ x | − δ ( s )) 2 ) / 2] − δ ( s ) − ( ¯ k /k ) 1 / 2 . This leads to the fi rst desired in equalit y . Next w e will prov e the second inequalit y . Without loss of generalit y and for simplicit y , w e ma y assume that x ′⊤ t x ( F ) ≥ 0 an d x ⊤ t − 1 ¯ x ≥ 0, b ecause otherwise we can simply do appr op r iate sign c hanges in the pro of. W e obtain from Lemma 3 that x ′⊤ t x ( F ) ≥ x ⊤ t − 1 x ( F ) [1 + (1 − γ ( s ) 2 )(1 − ( x ⊤ t − 1 x ( F )) 2 ) / 2] . This imp lies that [1 − x ′⊤ t x ( F )] ≤ [1 − x ⊤ t − 1 x ( F )] [1 − (1 − γ ( s ) 2 )(1 + x ⊤ t − 1 x ( F ))( x ⊤ t − 1 x ( F )) / 2] ≤ [1 − x ⊤ t − 1 x ( F )] [1 − 0 . 45(1 − γ ( s ) 2 )] , 23 where in the deriv ation of the second inequalit y , we ha v e used Lemma 2 and the assu m ption of the lemma that implies x ⊤ t − 1 x ( F ) ≥ x ⊤ t − 1 ¯ x − δ ( s ) ≥ 1 / √ 3. W e th us ha v e k x ′ t − x ( F ) k ≤ k x t − 1 − x ( F ) k p 1 − 0 . 45(1 − γ ( s ) 2 ) . Therefore usin g Lemma 2, w e ha v e k x ′ t − ¯ x k ≤ k x t − 1 − ¯ x k p 1 − 0 . 45(1 − γ ( s ) 2 ) + 2 δ ( s ) . This is equiv alent to q 1 − | x ′ t ⊤ ¯ x | ≤ q 1 − | x ⊤ t − 1 ¯ x | p 1 − 0 . 45(1 − γ ( s ) 2 ) + √ 2 δ ( s ) . Next we can apply Lemm a 4 and use ¯ k /k ≤ 0 . 25 to obtain q 1 − | ˆ x ⊤ t ¯ x | ≤ q 1 − | x ′ t ⊤ ¯ x | + (( ¯ k /k ) 1 / 2 + ¯ k /k )(1 − | x ′ t ⊤ ¯ x | 2 ) ≤ q 1 − | x ′ t ⊤ ¯ x | q 1 + 3( ¯ k /k ) 1 / 2 ≤ µ 2 q 1 − | x t − 1 ⊤ ¯ x | + √ 5 δ ( s ) . This p ro ve s the second desired inequalit y . Pro of of Theorem 1 W e know if | x ⊤ t − 1 ¯ x | ≥ u + δ ( s ), then Lemma 5 implies: | ˆ x ⊤ t ¯ x | ≥ ( | x ⊤ t − 1 ¯ x | − δ ( s ))[1 + (1 − γ ( s ) 2 )(1 − ( | x ⊤ t − 1 ¯ x | − δ ( s )) 2 ) / 2] − ( δ ( s ) + ( ¯ k /k ) 1 / 2 ) ≥ u [1 + (1 − γ ( s ) 2 )(1 − u 2 ) / 2] − ( δ ( s ) + ( ¯ k /k ) 1 / 2 ) ≥ u + δ ( s ) . The fir s t inequality uses Lemm a 5; the second in equalit y uses z (1 + (1 − γ 2 )(1 − z 2 ) / 2) is an increasing function of z ∈ [0 , 1]; and the third inequalit y uses the assump tion of u in the th eorem. This imp lies (b y an easy induction argument) that we ha ve | ˆ x ⊤ t ¯ x | ≥ u + δ for all t ≥ 0. No w w e can prov e the theorem by induction. T he b ound clearly holds at t = 0. Assume it holds at some t − 1. If we ha ve | ˆ x ⊤ t − 1 ¯ x | ≤ 1 / √ 3 + δ ( s ), th en since z (1 − z 2 ) is increasing in [0 , 1 / √ 3], and from Lemma 5 w e ha ve | ˆ x ⊤ t ¯ x | ≥ ( | x ⊤ t − 1 ¯ x | − δ ( s ))[1 + (1 − γ ( s ) 2 )(1 − ( | x ⊤ t − 1 ¯ x | − δ ( s )) 2 ) / 2 − ( δ ( s ) + ( ¯ k /k ) 1 / 2 ) ≥| x ⊤ t − 1 ¯ x | − δ ( s ) + (1 − γ ( s ) 2 ) u (1 − u 2 ) / 2 − ( δ ( s ) + ( ¯ k /k ) 1 / 2 ) ≥| x ⊤ t − 1 ¯ x | + µ 1 . Com bin g this inequalit y w ith | x ⊤ t ¯ x | = | ˆ x ⊤ t ¯ x | / k ˆ x t k ≥ | ˆ x ⊤ t ¯ x | w e get 1 − | x ⊤ t ¯ x | ≤ 1 − | ˆ x ⊤ t ¯ x | ≤ (1 − µ 1 )[1 − | x ⊤ t − 1 ¯ x | ] , whic h implies the theorem at t . If | ˆ x ⊤ t − 1 ¯ x | ≥ 1 / √ 3 + δ ( s ), then we ha ve from Lemma 5 q 1 − | x ⊤ t ¯ x | ≤ q 1 − | ˆ x ⊤ t ¯ x | ≤ µ 2 q 1 − | x ⊤ t − 1 ¯ x | + √ 5 δ ( s ) , whic h implies the theorem at t . Th is finishes ind u ction. 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment