PC-Cluster based Storage System Architecture for Cloud Storage
Design and architecture of cloud storage system plays a vital role in cloud computing infrastructure in order to improve the storage capacity as well as cost effectiveness. Usually cloud storage system provides users to efficient storage space with elasticity feature. One of the challenges of cloud storage system is difficult to balance the providing huge elastic capacity of storage and investment of expensive cost for it. In order to solve this issue in the cloud storage infrastructure, low cost PC cluster based storage server is configured to be activated for large amount of data to provide cloud users. Moreover, one of the contributions of this system is proposed an analytical model using M/M/1 queuing network model, which is modeled on intended architecture to provide better response time, utilization of storage as well as pending time when the system is running. According to the analytical result on experimental testing, the storage can be utilized more than 90% of storage space. In this paper, two parts have been described such as (i) design and architecture of PC cluster based cloud storage system. On this system, related to cloud applications, services configurations are explained in detailed. (ii) Analytical model has been enhanced to be increased the storage utilization on the target architecture.
💡 Research Summary
The paper proposes a low‑cost cloud storage solution built on a cluster of ordinary personal computers (PCs). Recognizing that storage hardware represents a major expense in cloud infrastructures, the authors aim to achieve high storage capacity and elasticity without the need for expensive dedicated storage arrays. The architecture integrates an academic private cloud based on Ubuntu Enterprise Cloud (UEC) and the open‑source IaaS platform Eucalyptus. The front‑end consists of a Cloud Controller (CLC), Cluster Controllers (CC), and Walrus (object storage), while the back‑end comprises Node Controllers (NC) that host virtual machine (VM) instances.
The novel contribution lies in separating the storage tier into a “PC Cluster based Storage Server” (CCPS) that employs the Hadoop Distributed File System (HDFS). A single NameNode manages metadata and block‑to‑DataNode mappings, and multiple DataNodes store the actual data blocks. Files are split into 64 MB blocks, each replicated three times for fault tolerance. The PC cluster is assembled from existing university PCs (e.g., Pentium Dual‑Core, P4, 80 GB HDD, 512 MB–1 GB RAM) interconnected via a gigabit Ethernet switch, thereby reusing idle disk space (approximately 80 % of each PC’s capacity) and avoiding new hardware purchases.
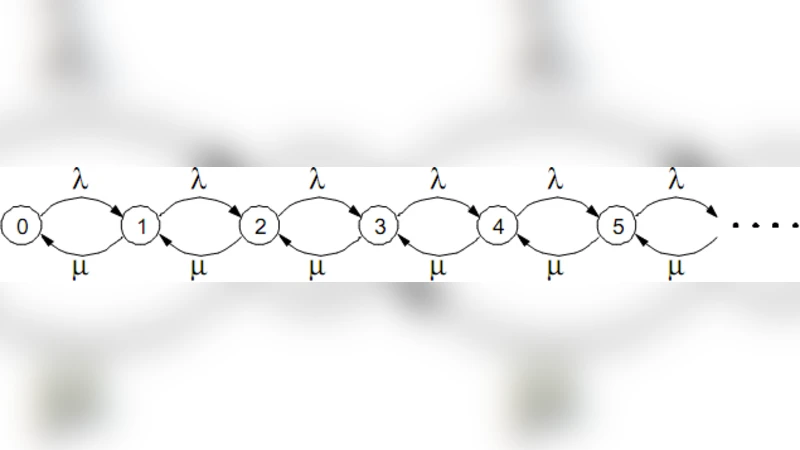
The authors present a performance model based on an M/M/1 queuing system. Arrival of I/O requests is assumed to follow a Poisson process with rate λ, and service times are exponentially distributed with rate μ. From this model they derive standard metrics: average number of jobs in the system, average waiting time, and server utilization ρ = λ/μ. Using the model they argue that the system can sustain a storage utilization above 90 % while keeping response times acceptable. Experimental validation consists of uploading and downloading files through the cloud interface; the measured utilization indeed exceeds 90 % and the system remains functional.
While the paper successfully demonstrates a cost‑effective way to build a terabyte‑scale storage pool from commodity PCs, several critical aspects are under‑explored. First, the queuing analysis treats the entire storage cluster as a single server, ignoring the parallelism inherent in HDFS where multiple DataNodes serve requests concurrently. Consequently, the model may underestimate throughput and overestimate latency for realistic workloads. Second, the paper provides limited quantitative performance data—no throughput (MB/s), latency distribution, or network bandwidth utilization is reported, making it difficult to assess scalability. Third, the architecture retains a single NameNode, which is a classic single point of failure; high‑availability (HA) configurations such as a standby NameNode are not discussed. Fourth, the impact of heterogeneous hardware (varying CPU speeds, RAM, disk I/O) on HDFS block placement and load balancing is not analyzed, although the cluster is explicitly described as heterogeneous. Fifth, replication factor is fixed at three without justification; a dynamic replication strategy could better balance storage overhead against reliability.
The discussion of related work correctly positions the proposal among existing solutions such as RAID‑based cloud storage, Amazon S3, and peer‑to‑peer storage systems, highlighting the trade‑off between cost and performance. However, the paper could benefit from a more thorough comparison with other low‑cost storage clusters that use commodity hardware, especially regarding fault tolerance, data consistency, and management overhead.
In conclusion, the study offers a practical blueprint for constructing a private cloud storage backend using readily available PCs and open‑source software. It validates the concept through a simple queuing model and basic experiments, showing that high storage utilization is achievable at minimal expense. To move from prototype to production‑grade service, future work should incorporate more realistic performance benchmarking, multi‑server queuing or network‑level modeling, NameNode HA, adaptive replication, and comprehensive security and access‑control mechanisms. Such enhancements would address the current gaps and make the solution viable for larger, more demanding cloud environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment