Entropy Search for Information-Efficient Global Optimization
Contemporary global optimization algorithms are based on local measures of utility, rather than a probability measure over location and value of the optimum. They thus attempt to collect low function values, not to learn about the optimum. The reason…
Authors: Philipp Hennig, Christian J. Schuler
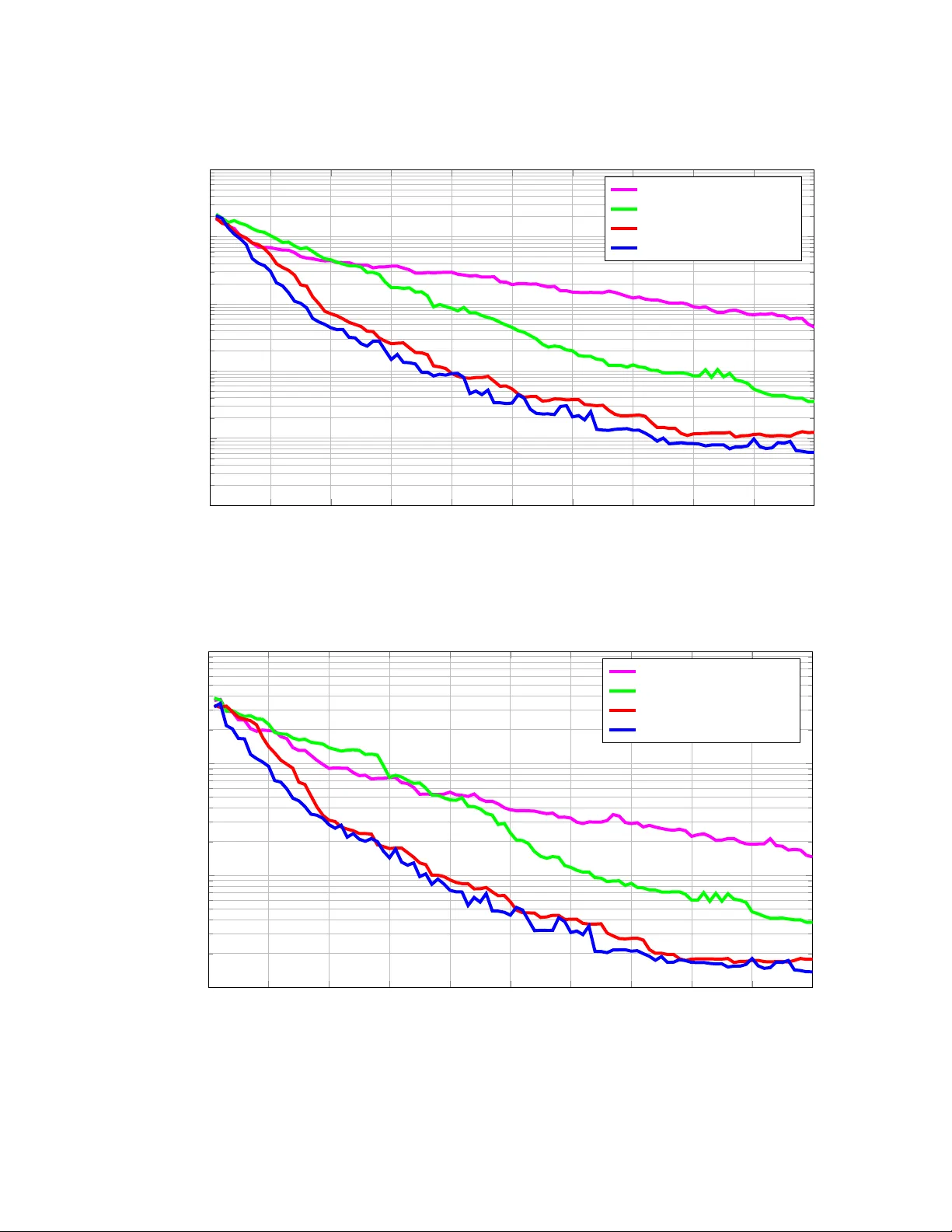
En trop y Searc h for Information-Efficien t Global Optimization Philipp Hennig phennig@tuebingen.mpg.de Christian J. Sc huler cschuler@tuebingen.mpg.de Dep artment of Empiric al Infer enc e Max Planck Institute for Intel ligent Systems Sp emannstr aße 38, T¨ ubingen, Germany Abstract Con temp orary global optimization algorithms are based on local measures of utilit y , rather than a probabilit y measure ov er lo cation and v alue of the optimum. They th us attempt to collect lo w function v alues, not to learn ab out the optim um. The reason for the absence of probabilistic global optimizers is that the corresponding inference problem is in tractable in sev eral wa ys. This pap er develops desiderata for probabilistic optimization algorithms, then presents a concrete algorithm which addresses eac h of the computational intractabil- ities with a sequence of appro ximations and explicitly adresses the decision problem of maximizing information gain from each ev aluation. Keyw ords: Optimization, Probabilit y , Information, Gaussian Pro cesses, Expectation Propagation 1. In tro duction Optimization problems are ubiquitous in science, engineering, and economics. Ov er time the requirements of many separate fields hav e led to a heterogenous set of settings and al- gorithms. Speaking very broadly , how ever, there are tw o distinct regimes for optimization. In the first one, relatively cheap function ev aluations take place on a numerical machine and the goal is to find a “go od” region of lo w or high function v alues. Noise tends to b e small or negligible, and deriv ativ e observ ations are often av ailable at lo w additional cost; but the parameter space may b e very high-dimensional. This is the regime of numeric al, lo c al or c onvex optimization, often encountered as a sub-problem of mac hine learning al- gorithms. P opular algorithms for suc h settings include quasi-Newton metho ds (Broyden et al., 1965; Fletc her, 1970; Goldfarb, 1970; Shanno, 1970), the conjugate gradien t metho d (Hestenes and Stiefel, 1952), and sto chastic optimization and evolutionary searc h metho ds (e.g. Hansen and Ostermeier (2001)), to name only a few. Since these algorithms p erform lo cal searc h, constrain ts on the solution space are often a crucial part of the problem. Thor- ough in tro ductions can b e found in the textb ooks b y No cedal and W right (1999) and Bo yd and V anden b erghe (2004). This pap er will utilize algorithms from this domain, but it is not its primary sub ject. In the second milieu, whic h this paper addresses, the function itself is not kno wn and needs to b e learned during the searc h for its glob al minim um within some measurable (usually: bounded) domain. Here, the parameter space is often relativ ely lo w-dimensional, c 2012 Philipp Hennig and Christian J. Sch uler. Hennig and Schuler but ev aluating the function in volv es a monetarily or morally exp ensiv e physical pro cess – building a prototype, drilling a b orehole, killing a ro dent, treating a patient. Noise is often a non trivial issue, and deriv ative observ ations, while p oten tially av ailable, cannot b e exp ected in general. While algorithms for such applications need to b e tractable, their most imp ortan t desideratum is efficient use of data, rather than raw computational cost. This domain is often called glob al optimization , but is also closely asso ciated with the field of exp erimental design and related to the concept of explor ation in reinforcement learning. The learned mo del of the function is also kno wn as a r esp onse surfac e in some comm unities. The tw o con tributions of this pap er are a probabilistic view on this field, and a concrete algorithm for suc h problems. 1.1 Problem Definition W e define the problem of pr ob abilistic glob al optimization : Let I ⊂ R D b e some b ounded domain of the real v ector space. There is a function f : I _ R , and our kno wledge about f is described by a probabilit y measure p ( f ) o v er the space of functions I _ R . This induces a measure p min ( x ) ≡ p [ x = arg min f ( x )] = Z f : I _ R p ( f ) Y ˜ x ∈ I ˜ x 6 = x θ [ f ( ˜ x ) − f ( x )] d f (1) w ere θ is Heaviside’s step function. The exact meaning of the “infinite pro duct” o v er the en tire domain I in this equation should b e intuitiv ely clear, but is defined properly in the App endix. Note that the integral is ov er the infinite-dimensional space of functions. W e assume we can ev aluate the function 1 at any p oint x ∈ I within some bounded domain I , obtaining function v alues y ( x ) corrupted b y noise, as described by a lik eliho o d p ( y | f ( x )). Finally , let L ( x ∗ , x min ) b e a loss function describing the cost of naming x ∗ as the result of optimization if the true minim um is at x min . This loss function induces a loss functional L ( p min ) assigning utilit y to the uncertain kno wledge ab out x min , as L ( p min ) = Z I [min x ∗ L ( x ∗ , x min )] p min ( x min ) d x min . (2) The goal of global optimization is to decrease the expected loss after H function ev aluations at lo cations x = { x 1 , . . . , x H } ⊂ I . The exp ected loss is hLi H = Z p ( y | x ) L ( p min ( x | y , x )) d y = Z Z p ( y | f ( x )) p ( f ( x ) | x ) L ( p min ( x | y , x )) d y d f (3) where L ( p min ( x | y , x )) should b e understo o d as the cost assigned to the measure p min ( x ) induced by the p osterior b elief o ver f after observ ations y = { y 1 , . . . , y H } ⊂ R at the lo cations x . The remainder of this pap er will replace the symbolic ob jects in this general definition with concrete measures and mo dels to construct an algorithm w e call Entr opy Se ar ch . But it is useful to pause at this p oint to contrast this definition with other concepts of optimization. 1. W e may further consider observ ations of linear op erations on f . This includes deriv ative and integral observ ations of an y order, if they exist. Section 2.8.1 addresses this p oin t; it is unproblematic under our c hosen prior, but clutters the notation, and is th us left out elsewhere in the pap er. 2 Entropy Search Probabilistic Optimization The distinctiv e aspect of our definition of “optimization” is Equation (1), an explicit role for the function’s extremum. Previous work did not consider the extremum so directly . In fact, many framew orks do not ev en use a measure ov er the function itself. An example of optimizers that only implicitly enco de assumptions ab out the function are genetic algorithms (Sc hmitt, 2004) and evolutionary search (Hansen and Ostermeier, 2001). If suc h formulations feature the global minim um x min at all, then only in statemen ts ab out the limit b ehavior of the algorithm after many ev aluations. Not explicitly writing out the prior o ver the function space can ha ve adv antages: Probabilistic analyses tend to in volv e in tractable integrals; a less explicit formulation thus allows to construct algorithms with interesting prop erties that w ould be en tirely in tractable from a probabilistic viewp oin t. But non-probabilistic algorithms cannot mak e explicit statements ab out the lo cation of the minim um. At b est, they may be able to pro vide b ounds. F undamentally , reasoning ab out optimization of functions on con tinuous domains after finitely many evaluations , like an y other inference task on spaces without natural measures, is imp ossible without prior assumptions. F or in tuition, consider the follo wing though t ex- p erimen t: Let ( x 0 , y 0 ) b e a finite, p ossibly empty , set of previously collected data. F or simplicit y , and without loss of generalit y , assume there w as no measurement noise, so the true function actually passes through each data p oin t. Say we wan t to suggest that the minim um of f ma y b e at x ∗ ∈ I . T o make this argument, w e prop ose a num b er of functions that pass through ( x 0 , y 0 ) and are minimized at x ∗ . W e may ev en suggest an uncountably infinite set of suc h functions. Whatever our prop osal, a critic can alw ays suggest another uncoun table set of functions that also pass through the data, and are not minimized at x ∗ . T o argue with this p erson, we need to reason ab out the relativ e size of our set v ersus their set. Assigning size to infinite sets amounts to the aforemen tioned normalized mea- sure o v er admissible functions p ( f ), and the consisten t w ay to reason with such measures is probability theory (Kolmogorov, 1933; Cox, 1946). Of course, this amoun ts to imp osing assumptions on f , but this is a fundamental epistemological limitation of inference, not a sp ecial asp ect of optimization. Relationship to the Bandit Setting There is a considerable amoun t of prior work on con tinuous bandit problems, also sometimes called “global optimization” (e.g. Kleinberg, 2005; Gr ¨ unew¨ alder et al., 2010; Sriniv as et al., 2010). The bandit concept differs from the setting defined ab ov e, and bandit regret b ounds do not apply here: Bandit algorithms seek to minimize r e gr et , the sum ov er function v alues at ev aluation p oints, while probabilistic optimizers seek to infer the minimum, no matter what the function v alues at ev aluation p oin ts. An optimizer gets to ev aluate H times, then has to make one single decision regard- ing L ( p min ). Bandit pla y ers ha v e to make H ev aluations, suc h that the ev aluations produce lo w v alues. This forces bandits to fo cus their ev aluation policy on function v alue, rather than the loss at the horizon (see also Section 3.1). In probabilistic optimization, the only quan tity that counts is the quality of the b elief on p min under L , after H ev aluations, not the sum of the function v alues returned during those H steps. Relationship to Heuristic Gaussian Pro cess Optimization and Response Surface Optimization There are also a n umber of w orks emplo ying Gaussian process measures to construct heuristics for search, also known as “Gaussian process global optimization” (Jones et al., 1998; Lizotte, 2008; Osborne et al., 2009). As in our definition, these metho ds explic- 3 Hennig and Schuler itly infer the function from observ ations, constructing a Gaussian pro cess p osterior. But they then ev aluate at the location maximizing a heuristic u [ p ( f ( x ))] that turns the mar ginal b elief o ver f ( x ) at x , which is a univ ariate Gaussian p ( f ( x )) = N [ f ( x ); µ ( x ) , σ 2 ( x )], into an ad ho c utility for ev aluation, designed to ha ve high v alue at locations close to the function’s minim um. Two p opular heuristics are the pr ob ability of impr ovement (Lizotte, 2008) u PI ( x ) = p [ f ( x ) < η ] = Z η −∞ N ( f ( x ); µ ( x ) , σ ( x ) 2 ) d f ( x ) = Φ η − µ ( x ) σ ( x ) (4) and exp e cte d impr ovement (Jones et al., 1998) u EI ( x ) = E [min { 0 , ( η − f ( x )) } ] = ( η − µ )Φ η − µ ( x ) σ ( x ) + σ φ η − µ ( x ) σ ( x ) (5) where Φ( z ) = 1 / 2[1 + erf ( z / √ 2)] is the standard Gaussian cumulativ e density function, φ ( x ) = N ( x ; 0 , 1) is the standard Gaussian probabilit y densit y function, and η is a current “b est guess” for a low function v alue, e.g. the low est ev aluation so far. These tw o heuristics ha ve differen t units of measure: probabilit y of improv emen t is a probabilit y , exp ected impro vemen t has the units of f . Both utilities differ mark edly from Eq. (1), p min , which is a probability me asur e and as such a glob al quantit y . See Figure 2 for a comparison of the three concepts on an example. The adv antage of the heuristic approac h is that it is computationally light weigh t, b ecause the utilities ha v e analytic form. But lo cal measures cannot capture general decision problems of the t yp e describ ed ab ov e. F or example, these algorithms do not capture the effect of ev aluations on knowledge: A small region of high density p min ( x ) may be less interesting to explore than a broad region of lo wer density , b ecause the expected change in knowledge from an ev aluation in the broader region may b e muc h larger, and ma y thus ha v e muc h stronger effect on the loss. If the goal is to infer the lo cation of the minimum (more generally: minimize loss at the horizon), the optimal strategy is to ev aluate where we exp ect to le arn most ab out the minim um (reduce loss tow ard the horizon), rather then where we think the minimum is (recall Section 1.1). The former is a nonlo cal problem, because ev aluations affect the belief, in general, ev erywhere. The latter is a lo cal problem. 2. Entrop y Searc h The probable reason for the absence of global optimization algorithms from the literature is a n um b er of in tractabilities in an y concrete realisation of the setting of Section 1.1. This section mak es some c hoices and constructs a series of appro ximations, to arriv e at a tangible algorithm, which w e call Entr opy Se ar ch . The deriv ations evolv e along the follo wing path. c ho osing p ( f ) W e commit to a Gaussian pro cess prior on f (Section 2.1). Limitations and implications of this c hoice are outlined, and p ossible extensions suggested, in Sections 2.8.1 and 2.8.3. discretizing p min W e discretize the problem of calculating p min , to a finite set of represen- ter p oints c hosen from a non-uniform measure, which deals gracefully with the curse of dimensionality . Artefacts created by this discretization are studied in the tractable one-dimensional setting (Section 2.2). 4 Entropy Search − 5 − 4 − 3 − 2 − 1 0 1 2 3 4 5 f x Figure 1: A Gaussian pro cess measure (rational quadratic kernel), conditioned on three previous observ ations (black crosses). Mean function in solid red, marginal stan- dard deviation at each lo cation (t wo standard deviations) as ligh t red tube. Five sampled functions from the curren t belief as dashed red lines. Arbitrary ordinate scale, zero in gray . appro ximating p min W e construct an efficient appro ximation to p min , whic h is required b ecause Eq. (1), even for finite-dimensional Gaussian measures, is not analytically tractable, (Section 2.3). W e compare the approximation to the (asymptotically exact, but more exp ensiv e) Monte Carlo solution. predicting c hange to p min The Gaussian process measure affords a straightforw ard but rarely used analytic probabilistic formulation for the change of p ( f ) as a function of the next ev aluation p oin t (Section 2.4). c ho osing loss function W e commit to relativ e entr opy from a uniform distribution as the loss function, as this can b e in terpreted as a utility on gained information ab out the lo cation of the minim um (Section 2.5). predicting exp ected information gain F rom the predicted c hange, w e construct a first- order expansion on hLi from future ev aluations and, again, compare to the asymptot- ically exact Mon te Carlo answer (Section 2.6). c ho osing greedily F aced with the exp onen tial cost of the exac t dynamic problem to the horizon H , w e accept a greedy approach for the reduction of hLi at ev ery step. W e illustrate the effect of this shortcut in an example setting (Section 2.7). 2.1 Gaussian Pro cess Measure on f The remainder of the pap er commits to Gaussian pro cess measures for p ( f ). These are con venien t for the task at hand due to their descriptive generality and their con venien t analytic prop erties. Since this pap er is aimed at readers from several comm unities, this section con tains a very brief introduction to some relev ant asp ects of Gaussian pro cesses; 5 Hennig and Schuler readers familiar with the sub ject can safely skip ahead. A thorough in tro duction can b e found in a textb o ok of Rasmussen and Williams (2006). Some readers from other fields ma y find it helpful to kno w that more or less special cases of Gaussian pro cess inference are elsewhere kno wn under names lik e Kriging (Krige, 1951) and Kolmo gor ov-Wiener pr e diction (Wiener and Masani, 1957), but while these frameworks are essen tially the same idea, the generality of their definitions v aries, so restrictions of those framew orks should not b e assumed to carry ov er to Gaussian pro cess inference as understo o d in machine learning. A Gaussian pro cess is an infinite-dimensional probability densit y , suc h that each linear finite-dimensional restriction is multiv ariate Gaussian. The infinite-dimensional space can b e though t of as a space of functions, and the finite-dimensional restrictions as values of those functions at lo cations { x ∗ i } i =1 ,...,N . Gaussian pro cess b eliefs are parametrized b y a me an function m : I _ R and a c ovarianc e function k : I × I _ R . F or our particular analysis, we restrict the domain I to finite, compact subsets of the real v ector spaces R D . The cov ariance function, also known as the kernel , has to b e p ositiv e definite, in the sense that an y finite-dimensional matrix with elemen ts K ij = k ( x i , x j ) has to b e positive definite ∀ x i , x j ∈ I . A num b er of such kernel functions are known in the literature, and differ- en t kernel functions induce differen t kinds of Gaussian pro cess measures ov er the space of functions. Among the most widely used k ernels for regression are the squar e d exp onential k ernel k SE ( x, x 0 ; S , s ) = s 2 exp − 1 2 ( x − x 0 ) | S − 1 ( x − x 0 ) (6) whic h induces a measure that puts nonzero mass on only smo oth functions of char acteristic length-sc ale S and signal varianc e s 2 (MacKa y, 1998b), and the r ational quadr atic k ernel (Mat ´ ern, 1960; Rasmussen and Williams, 2006) k RQ ( x, x 0 ; S , s, α ) = s 2 1 + 1 2 α ( x − x 0 ) | S − 1 ( x − x 0 ) − α (7) whic h induces a b elief ov er smo oth functions whose characteristic length scales are a scale mixture ov er a distribution of width 1 /α and lo cation S . Other kernels can b e used to induce b eliefs ov er non-smo oth functions (Mat´ ern, 1960), and even ov er non-contin uous functions (Uhlenbeck and Ornstein, 1930). Exp erimen ts in this pap er use the tw o kernels defined abov e, but the results apply to all k ernels inducing b eliefs o ver c ontinuous functions. While there is a straigh tforward relationship betw een k ernel con tinuit y and the mean square con tinuit y of the induced pr o c ess , the relationship b et ween the k ernel function and the con tinuit y of each sample is considerably more inv olved (Adler, 1981, § 3). Regularity of the k ernel also plays a nontrivial role in the question wether the distribution of infima of samples from the pro cess is well-defined at all (Adler, 1990). In this w ork, w e side-step this issue by assuming that the c hosen k ernel is sufficien tly regular to induce a well-defined b elief p min as defined b y Equation (26). Kernels form a semiring: pro ducts and sums of k ernels are kernels. These op erations can b e used to generalize the induced beliefs o ver the function space (Section 2.8.3). Without loss of generality , the mean function is often set to m ≡ 0 in theoretical analyses, and this pap er will k eep with this tradition, except for Section 2.8.3. Where m is nonzero, its effect is a straigh tforward off-set p ( f ( x )) _ p ( f ( x ) − m ( x )). 6 Entropy Search F or the purp ose of regression, the most imp ortan t asp ect of Gaussian pro cess priors is that they are conjugate to the likelihoo d from finitely many observ ations ( X , Y ) = { x i , y i } i =1 ,...,N of the form y i ( x i ) = f ( x i ) + ξ with Gaussian noise ξ ∼ N (0 , σ 2 ). The p osterior is a Gaussian pro cess with mean and cov ariance functions µ ( x ∗ ) = k x ∗ , X [ K X , X + σ 2 I ] − 1 y ; Σ( x ∗ , x ∗ ) = k x ∗ , x ∗ − k x ∗ , X [ K X , X + σ 2 I ] − 1 k X , x ∗ (8) where K X , X is the k ernel Gram matrix K ( i,j ) X , X = k ( x i , x j ), and other ob jects of the form k a , b are also matrices with elements k ( i,j ) a , b = k ( a i , b j ). Finally , for what follo ws it is imp ortan t to kno w that it is straigh tforw ard to sample “functions” (p oin t-sets of arbitrary size from I ) from a Gaussian pro cess. T o sample the v alue of a particular sample at the M lo cations X ∗ , ev aluate mean and v ariance function as a function of an y previously collected datap oin ts, using Eq. (8), dra w a vector ζ ∼ Q M N (0 , 1) of M random n umbers i.i.d. from a standard one-dimensional Gaussian distribution, then ev aluate ˜ f ( X ∗ ) = µ ( X ∗ ) + C [Σ( X ∗ , X ∗ )] | ζ (9) where the op erator C denotes the Cholesky decomp osition (Benoit, 1924). 2.2 Discrete Represen tations for Contin uous Distributions Ha ving established a probability measure p ( f ) on the function, w e turn to constructing the b elief p min ( x ) o ver its minim um. Insp ecting Equation (1), it b ecomes apparen t that it is c hallenging in tw o w ays: First, b ecause it is an in tegral ov er an infinite-dimensional space, and second, because even on a finite-dimensional space it ma y be a hard in tegral for a particular p ( f ). This section deals with the former issue, the following Section 2.3 with the latter. It may seem daunting that p min in volv es an infinite-dimensional in tegral. The crucial observ ation for a meaningful appro ximation in finite time is that regular functions can be represen ted meaningfully on finitely man y p oin ts. If the stochastic pro cess representing the b elief o ver f is sufficien tly regular, then Equation (1) can b e appro ximated arbitrarily well with finitely man y representer points. The discretization grid need not b e regular – it ma y b e sampled from an y distribution whic h puts non-zero measure on ev ery op en neigh b orho o d of I . This latter p oin t is centr al to a graceful handling of the curse of dimensionalit y: The na ¨ ıv e approach of appro ximately solving Equation (1) on a regular grid, in a D -dimensional domain, w ould require O (exp( D )) p oin ts to ac hieve any giv en resolution. This is obviously not efficient: Just lik e in other n umerical quadrature problems, any given resolution can be ac hieved with fewer representer p oints if they are chosen irregularly , with higher resolution in regions of greater influence on the result of integration. W e thus choose to sample represen ter p oin ts from a prop osal measure u , using a Mark ov chain Monte Carlo sampler (our implementation uses shrinking rank slice sampling (Thompson and Neal, 2010)). What is the effect of this sto c hastic discretization? A non-uniform quadrature measure u ( ˜ x ) for N representer lo cations { ˜ x i } i =1 ,...,N leads to v arying widths in the “steps” of the represen ting staircase function. As N _ ∞ , the width of each step is approximately prop ortional to ( u ( ˜ x i ) N ) − 1 . Section 2.3 will construct a discretized ˆ q min ( ˜ x i ) that is an appro ximation to the probabilit y that f min o ccurs within the step at ˜ x i . So the appro ximate 7 Hennig and Schuler − 5 − 4 − 3 − 2 − 1 0 1 2 3 4 5 f x Figure 2: p min induced by p ( f ) from Figure 1. p ( f ) rep eated for reference. Blue solid line: Asymptotically exact representation gained from exact sampling of functions on a regular grid. F or comparison, the plot also shows the local utilities pr ob ability of impr ovement (dashed magen ta) and exp e cte d impr ovement (solid magenta) often used for Gaussian process global optimization. Blue circles: Approximate represen tation on represen ter p oin ts, sampled from probabilit y of impro vemen t measure. Sto chastic error on sampled v alues, due to only asymptotically correct assignmen t of mass to samples, and v arying densit y of p oin ts, fo cusing on relev ant areas of p min . This plot uses arbitrary scales for each ob ject: The tw o heuristics ha ve differen t units of measure, differing from that of p min . Notice the in teresting features of p min at the b oundaries of the domain: The prior b elief enco des that f is smo oth, and puts finite probabilit y mass on the hypothesis that f has negative (p ositiv e) deriv ative at the right (left) boundary of the domain. With nonzero probabilit y , the minimum th us lies exactly on the b oundary of the domain, rather than within a T aylor radius of it. 8 Entropy Search f N ( f ; ˜ µ , ˜ Σ ) θ [ f ( ˜ x j ) − f ( ˜ x i )] i 6 = j Figure 3: Graphical mo del pro viding motiv ation for EP appro ximation on p min . See text for details. ˆ p min on this step is proportional to ˆ q min ( ˜ x i ) u ( ˜ x i ), and can b e easily normalized numerically , to b ecome an appro ximation to p min . Ho w should the measure u b e c hosen? Unfortunately , the result of the in tegration, b eing a density rather than a function, is itself a function of u , and the loss-function is also part of the problem. So it is non trivial to construct an optimal quadrature measure. Intuitiv ely , a go o d prop osal measure for discretization points should put high resolution on regions of I where the shap e of p min has strong influence on the loss, and on its change. F or our c hoice of loss function (Section 2.5), it is a go o d idea to c ho ose u such that it puts high mass on regions of high v alue for p min . But for other functions, this need not alwa ys b e the case. W e hav e exp erimen ted with a num b er of ad-ho c c hoices for u , and found the aforemen- tioned “exp ected impro vemen t” and “probabilit y of improv emen t” (Section 1.1) to lead to reasonably go o d p erformance. W e use these functions for a similar reason as their original authors: Because they tend to hav e high v alue in regions where p min is also large. T o av oid confusion, ho w ever, note that we use these functions as unnormalized measures to sample discr etization p oints for our c alculation of p min , not as an appro ximation for p min itself, as w as done in previous work by other authors. Defects in these heuristics hav e weak er effect on our algorithm than in the cited w orks: In our case, if u is not a go o d proposal measure, w e simply need more samples to construct a go o d represen tation of p min . In the limit of N _ ∞ , all c hoices of u perform equally well, as long as they put nonzero mass on all op en neigh b orho ods of the domain. 2.3 Appro ximating p min with Exp ectation Propagation The previous Section 2.2 provided a wa y to construct a non-uniform grid of N discrete lo cations ˜ x i , i = 1 , . . . , N . The restriction of the Gaussian pro cess b elief to thes e lo cations is a m ultiv ariate Gaussian density with mean ˜ µ ∈ R N and cov ariance ˜ Σ ∈ R N × N . So Equation (1) reduces to a discrete probability distribution (as opp osed to a densit y) ˆ p min ( x i ) = Z f ∈ R N N ( f ; ˜ µ , ˜ Σ ) N Y i 6 = j θ ( f ( x j ) − f ( x i )) d f . (10) This is a multiv ariate Gaussian in tegral o ver a half-op en, conv ex, piecewise linearly con- strained integration region – a p olyhedral cone. Unfortunately , suc h in tegrals are kno wn to be intractable (Plac k ett, 1954; Lazard-Holly and Holly, 2003). How ever, it is p ossible to construct an effectiv e appro ximation ˆ q min based on Expectation Propagation (EP) (Mink a, 2001): Consider the b elief p ( f ( ˜ x )) as a “prior message” on f ( ˜ x ), and eac h of the terms in 9 Hennig and Schuler the pro duct as one factor providing another message. This gives the graphical mo del sho wn in Figure 3. Running EP on this graph pro vides an approximate Gaussian marginal, whose normalisation constant ˆ q min ( x i ), whic h EP also pro vides, appro ximates p ( f | x min = x i ). The EP algorithm itself is somewhat inv olv ed, and there are a n umber of algorithmic tec hnical- ities to take into account for this particular setting. W e refer in terested readers to recent w ork b y Cunningham et al. (2011), which gives a detailed description of these asp ects. The cited w ork also establishes that, while EP’s approximations to Gaussian integrals are not alw ays reliable, in this particular case, where there are as man y constraints as dimensions to the problem, the appro ximation is generally of high quality (see Figure 4 for an exam- ple). An imp ortan t adv antage of the EP approximation o ver b oth n umerical integration and Monte Carlo integration (see next Section) is that it allows analytic differentiation of ˆ q min with resp ect to the parameters ˜ µ and ˜ Σ (Cunningham et al., 2011; Seeger, 2008). This fact will b ecome imp ortan t in Section 2.6. The computational cost of this approximation is considerable: Each computation of ˆ q min ( ˜ x i ), for a giv en i , in volv es N factor up dates, which each hav e rank 1 and th us cost O ( N 2 ). So, o verall, the cost of calculating ˆ q min ( ˜ x ) is O ( N 4 ). This means N is effectively limited to well b elow N = 1000. Our implemen tation uses a default of N = 50, and can calculate next ev aluation points in ∼ 10 seconds. Once again, it is clear that this algorithm is not suitable for simple numerical optimization problems; but a few seconds are arguably an acceptable w aiting time for physical optimization problems. 2.3.1 An al terna tive: Sampling An alternativ e to EP is Mon te Carlo integration: sample S functions exactly from the Gaussian b elief on p ( f ), at cost O ( N 2 ) p er sample, then find the minimum for eac h sample in O ( N ) time. This technique was used to generate the asymptotically exact plots in Figures 2 and follo wing. It has o verall cost O ( S N 3 ), and can b e implemen ted efficien tly using Matrix-Matrix m ultiplications, so each ev aluation of this algorithm is considerably faster than EP . It also has the adv antage of asymptotic exactness. But, unfortunately , it pro vides no analytic deriv atives, b ecause of strong discontin uity in the step functions of Eq. (1). So the choice is b et ween a first-order expansion using EP (see Section 2.6) whic h is exp ensive, but pro vides a re-usable, differentiable function, and rep eated calls to a cheaper, asymptotically exact sampler. In our exp eriments, the former option app eared to b e considerably faster, and of acceptable appro ximative qualit y . But for relatively high- dimensional optimization problems, where one would expect to require relativ ely large N for acceptable discretization, the sampling approac h can b e exp ected to scale b etter. The co de w e plan to publish up on acceptance offers a choice b et ween these tw o approaches. 2.4 Predicting Inno v ation from F uture Observ ations As detailed in Equation (3), the optimal c hoice of the next H ev aluations is suc h that the exp e cte d change in the loss hLi x is minimal, i.e. effects the biggest possible expected drop in loss. The loss is a function of p min , whic h in turn is a function of p ( f ). So predicting c hange in loss requires predicting change in p ( f ) as a function of the next ev aluation p oin ts. It is another conv enient asp ect of Gaussian pro cesses that they allow suc h predictions in analytic form (Hennig, 2011): Let previous observ ations at X 0 ha ve yielded observ ations 10 Entropy Search − 5 − 4 − 3 − 2 − 1 0 1 2 3 4 5 f x Figure 4: EP-approximation to p min (green). Other plots as in previous figures. EP achiev es go od agreement with the asymptotically exact Mon te Carlo approximation to p min , including the p oin t masses at the b oundaries of the domain. − 5 − 4 − 3 − 2 − 1 0 1 2 3 4 5 f x Figure 5: Innov ation from tw o observ ations at x = − 3 and x = 3. Curren t b elief in red, as in Figure 1. Samples from the b elief ov er p ossible b eliefs after observ ations at x in blue. F or each sampled innov ation, the plot also shows the induced inno v ated p min (lo wer sampling resolution as previous plots). Innov ations from sev eral (here: t wo) observ ations can b e sampled jointly . 11 Hennig and Schuler Y 0 . Ev aluating at lo cations X will giv e new observ ations Y , and the mean will b e given b y µ ( x ∗ ) = [ k x ∗ , X 0 , k x ∗ , X ] K X 0 , X 0 k X 0 , X k X , X 0 K X , X − 1 Y 0 Y = k x ∗ , X 0 K − 1 X 0 , X 0 Y 0 + ( k x ∗ , X − k x ∗ , X 0 K − 1 X 0 , X 0 k X 0 , X ) × ( k X , X − k X , X 0 K − 1 X 0 , X 0 k X 0 , X ) − 1 ( Y − k X , X 0 K − 1 X 0 , X 0 Y 0 ) = µ 0 ( x ∗ ) + Σ 0 ( x ∗ , X )Σ − 1 0 ( X , X )( Y − µ 0 ( X )) (11) where K ( i,j ) a,b = k ( a i , b j ) + δ ij σ 2 . The step from the first to the second line inv olves an application of the matrix inv ersion lemma, the last line uses the mean and co v ariance functions conditioned on the dataset ( X 0 , Y 0 ) so far. Since Y is presumed to come from this very Gaussian pro cess b elief, we can write Y = µ ( X )+ C [Σ( X , X )] | Ω 0 + σ ω = µ ( X )+ C [Σ( X , X )+ σ 2 I H ] | Ω Ω , Ω 0 , ω ∼ N (0 , I H ) , (12) and Equation (11) simplifies. An ev en simpler construction can b e made for the co v ariance function. W e find that mean and cov ariance function of the p osterior after observ ations ( X , Y ) are mean and cov ariance function of the prior, incremented b y the innovations ∆ µ X , Ω ( x ∗ ) = Σ( x ∗ , X )Σ − 1 ( X , X ) C [Σ( X , X ) + σ 2 I H ] Ω ∆Σ X ( x ∗ , x ∗ ) = Σ( x ∗ , X )Σ − 1 ( X , X )Σ( X , x ∗ ) . (13) The c hange to the mean function is sto c hastic, while the change to the cov ariance function is deterministic. Both innov ations are functions b oth of X and of the ev aluation p oin ts x ∗ . One use of this result is to sample hLi X b y sampling innov ations, then ev aluating the inno v ated p min for each innov ation in an inner lo op, as describ ed in Section 2.3.1. An alter- nativ e, described in the next section, is to construct an analytic first order approximation to hLi X from the EP prediction constructed in Section 2.3. As men tioned abov e, the ad- v antage of this latter option is that it pro vides an analytic function, with deriv atives, which allo ws efficien t numerical lo cal optimization. 2.5 Information Gain – the Log Loss T o solv e the decision problem of where to ev aluate the function next in order to learn most ab out the lo cation of the minim um, w e need to sa y what it means to “learn”. Th us, we require a loss functional that ev aluates the information conten t of inno v ated b eliefs p min . This is, of course, a core idea in information theory . The seminal pap er b y Shannon (1948) sho wed that the negative exp ectation of probability logarithms, H [ p ] = −h log p i p = − X i p i log p i (14) kno wn as entrop y , has a num b er of prop erties that allow its interpretation as a measure of uncertaint y represen ted b y a probabilit y distribution p . It’s v alue can b e b e in terpreted as the n umber of natural information units an optimal compression algorithm requires to enco de a sample from the distribution, giv en kno wledge of the distribution. How ever, 12 Entropy Search − 5 − 4 − 3 − 2 − 1 0 1 2 3 4 5 f x Figure 6: 1-step predicted loss impro vemen t for the log loss (relativ e entrop y). Upp er part of plot as before, for reference. Mon te Carlo prediction on regular grid as solid blac k line. Mon te Carlo prediction from sampled irregular grid as dot-dashed blac k line. EP prediction on regular grid as black dashed line. EP prediction from samples as black dashed line. The minima of these functions, where the algorithm will ev aluate next, are mark ed b y v ertical lines. While the predictions from the v arious approximations are not identical, they lead to similar next ev aluation p oin ts. Note that these next ev aluation p oin ts differ qualitatively from the choice of the GP optimization heuristics of Figure 2. Since eac h approximation is only tractable up a multiplicativ e constan t, the scales of these plots are arbitrary , and only chosen to ov erlap for conv enience. 13 Hennig and Schuler it has since b een p oin ted out rep eatedly that this concept do es not trivially generalize to probability densities. A density p ( x ) has a unit of measure [ x ] − 1 , so its logarithm is not well-defined, and one cannot simply replace summation with in tegration in Equation (14). A functional that is w ell-defined on probability densities and preserves many of the information-con tent interpretations of entrop y (Ja ynes and Bretthorst, 2003) is r elative entr opy , also kno wn as Kullback-Leibler divergence (Kullbac k and Leibler, 1951). W e use its negative v alue as a loss function emphasizing information gain. L KL ( p ; b ) = − Z p ( x ) log p ( x ) b ( x ) d x (15) As base measure b w e choose the uniform measure U I ( x ) = | I | − 1 o ver I , which is well- defined b ecause I is presumed to b e bounded 2 . With this choice, the loss is maximized (at L = 0) for a uniform b elief ov er the minimum, and diverges to ward negativ e infinity if p approac hes a Dirac p oin t distribution. The resulting algorithm, Entrop y Searc h, will th us c ho ose ev aluation points such that it exp ects to mov e aw ay from the uniform base measure to ward a Dirac distribution as quickly as p ossible. The reader may wonder: What ab out the alternative idea of maximizing, at each ev al- uation, en trop y relativ e to the curr ent p min ? This w ould only encourage the algorithm to attempt to c hange the current b elief, but not necessarily in the right direction. F or ex- ample, if the curren t b elief puts v ery low mass on a certain region, an ev aluation that has ev en a small chance of increasing p min in this region could app ear more fav orable than an alternativ e ev aluation predicted to hav e a large effect on regions where the current p min has larger v alues. The p oint is not to just c hange p min , but to change it such that it mov es a wa y from the base measure. Recall that w e approximate the density p ( x ) using a distribution ˆ p ( x i ) on a finite set { x i } of represen ter p oin ts, which define steps of width proportional, up to sto c hastic error, to an unnormalized measure ˜ u ( x i ). In other w ords, w e can approximate p min ( x ) as p min ( x ) ≈ ˆ p ( x i ) N ˜ u ( x i ) Z u Z u = Z ˜ u ( x ) d x x i = arg min { x j } k x − x j k . (16) W e also note that after N samples, the unit element of measure has size, up to sto c hastic error, of ∆ x i ≈ Z u ˜ u ( x i ) N . So we can approximately represen t the loss L KL ( p min ; b ) ≈ − X i p min ( x i )∆ x i log p min ( x i ) b ( x i ) = − X i ˆ p min ( x i ) log ˆ p min ( x i ) N ˜ u ( x i ) Z u b ( x i ) = − X i ˆ p min ( x i ) log ˆ p min ( x i ) ˜ u ( x i ) b ( x i ) + log Z u N X i ˆ p min ( x i ) = H [ ˆ p min ] − h log ˜ u i ˆ p min + h log b i ˆ p min + log Z u − log N (17) 2. Although uniform measures app eal as a natural representation of ignorance, they do enco de an as- sumption ab out I b eing represented in a “natural” wa y . Under a nonlinear transformation of I , the distribution w ould not remain uniform. F or example, uniform measures on the [0,1] simplex appear b ell-shaped in the softmax basis (MacKay, 1998a). So, while b here does not represent prior knowledge on x min p er se, it do es provide a unit of measure to information and as such is nontrivial. 14 Entropy Search whic h means we do not require the normalization constan t Z u for optimization of L KL . F or our uniform base measure, the third term in the last line is a constant, too; but other base measures would con tribute nontrivially . 2.6 First-Order Appro ximation to hLi Since EP provides analytic deriv atives of p min with resp ect to mean and co v ariance of the Gaussian measure o ver f , we can construct a first order expansion of the expected c hange in loss from ev aluations. T o do so, w e consider, in turn, the effect of ev aluations at X on the measure on f , the induced c hange in p min , and finally the c hange in L . Since the c hange to the mean is Gaussian sto c hastic, It¯ o’s Lemma (It¯ o, 1951) applies. The following Equation uses the summation conv ention: double indices in pro ducts are summed o ver. h ∆ Li X = Z L p 0 min + ∂ p min ∂ Σ( ˜ x i , ˜ x j ) ∆Σ X ( ˜ x i , ˜ x j ) + ∂ 2 p min ∂ µ i ∂ µ j ∆ µ X , 1 ( ˜ x i )∆ µ X , 1 ( ˜ x j ) + ∂ p min ∂ µ ( ˜ x i ) ∆ X , Ω µ ( ˜ x i ) + O ((∆ µ ) 2 , (∆Σ) 2 ) N (Ω; 0 , 1) dΩ − L [ p 0 min ] . (18) The first line contains deterministic effects, the first term in the second line cov ers the sto c hastic asp ect. Mon te Carlo integration ov er the sto c hastic effects can b e p erformed appro ximately using a small n umber of samples Ω . These samples should b e drawn only once, at first calculation, to get a differen tiable function h ∆ Li X that can b e re-used in subsequen t optimization steps. The ab o ve formulation is agnostic with resp ect to the loss function. Hence, in principle, En tropy Searc h should b e easy to generalize to different loss functions. But recall that the fidelit y of the calculation of Equation (18) depends on the in termediate appro ximate steps, in particular the choice of discretization measure ˜ u . W e ha ve experimented with other loss functions and found it difficult to find a go od measure ˜ u pro viding go o d performance for man y suc h loss functions. So this pap er is limited to the sp ecific c hoice of the relativ e en tropy loss function. Generalization to other losses is future w ork. 2.7 Greedy Planning, and its Defects The previous sections constructed a means to predict, approximately , the exp ected drop in loss from H new ev aluations at lo cations X = { x i } i =1 ,...,N . The remaining task is to optimize these lo cations. It may seem p ointless to construct an optimization algorithm whic h itself contains an optimization problem, but note that this new optimization problem is quite differen t from the initial one. It is a numerical optimization problem, of the form describ ed in Section 1: W e can ev aluate the utility function numerically , without noise, with deriv atives, and at hopefully relativ ely low cost compared to the physical pro cess we are ultimately trying to optimize. Nev ertheless, one issue remains: Optimizing ev aluations o v er the en tire horizon H is a dynamical programming problem, whic h, in general, has cost exp onen tial in H . How ev er, this problem has a particular structure: Apart from the fact that ev aluations dra wn from Gaussian pro cess measures are exchangeable, there is also other evidence that optimization problems are b enign from the p oin t of view of planning. F or example, Sriniv as et al. (2010) 15 Hennig and Schuler − 4 − 2 0 2 4 − 4 − 2 0 2 4 Figure 7: Exp ected drop in relativ e en tropy (see Section 2.5) from t wo additional ev alua- tions to the three old ev aluations shown in previous plots. First new ev aluation on abscissa, second new ev aluation on ordinate, but due to the exc hangeability of Gaussian pro cess measures, the plot is symmetric. Diagonal elements excluded for numerical reasons. Blue regions are more b eneficial than red ones. The rela- tiv ely complicated structure of this plot illustrates the complexity of finding the optimal H -step ev aluation lo cations. 16 Entropy Search sho w that the information gain ov er the function v alues is submo dular, so that greedy learning of the function comes close to optimal learning of the function. While is is not immediately clear whether this statemen t extends to our issue of learning ab out the func- tion’s minimum, it is ob vious that the greedy c hoice of whatev er ev aluation lo cation most reduces exp ected loss in the immediate next step is guaran teed to never b e catastrophically wrong. In contrast to general planning, there are no “dead ends” in inference problems. A t worst, a greedy algorithm ma y choose an ev aluation p oin t rev ealed as redundan t b y a later step. But thanks to the consistency of Bay esian inference in general, and Gaussian pro cess priors in particular (v an der V aart and v an Zan ten, 2011), no decision can lead to an ev aluation that someho w mak es it imp ossible to learn the true function afterw ard. In our appro ximate algorithm, we thus adopt this greedy approac h. It remains an op en question for future researc h whether appro ximate planning techniques can b e applied efficien tly to impro ve p erformance in this planning problem. 2.8 F urther Issues This section digresses from the main line of thought to briefly touch up on some extensions and issues arising from the c hoices made in previous sections. F or the most part, we point out w ell-known analytic properties and approximations that can b e used to generalize the algorithm. Since they apply to Gaussian pro cess regression rather than the optimizer itself, they will not play a role in the empirical ev aluation of Section 3. 2.8.1 Deriv a tive Obser v a tions Gaussian pro cess inference remains analytically tractable if instead of, or in addition to direct observ ations of f , we observ e the result of any line ar op erator acting on f . This includes observ ations of the function’s deriv atives (Rasm ussen and Williams, 2006, § 9.4) and, with some ca veats, to in tegral observ ations (Mink a, 2000). The extension is pleas- ingly straigh tforward: The k ernel defines co v ariances b et ween function v alues. Cov ariances b et w een the function and its deriv ativ es are simply giv en b y co v ∂ n f ( x ) Q i ∂ x i , ∂ m f ( x 0 ) Q j ∂ x 0 j ! = ∂ n + m k ( x , x 0 ) Q i ∂ x i Q j ∂ x 0 j (19) so kernel ev aluations simply ha v e to be replaced with deriv ativ es (or in tegrals) of the kernel where required. Ob viously , this op eration is only v alid as long as the deriv atives and in tegrals in question exist for the kernel in question. Hence, all results derived in previous sections for optimization from function ev aluations can trivially be extended to optimization from function and deriv ative observ ations, or from only deriv ative observ ations. 2.8.2 Learning Hyperp arameters Throughout this pap er, w e ha ve assumed k ernel and lik eliho o d function to b e giv en. In real applications, this will not usually b e the case. In such situations, the hyperparameters defining these tw o functions, and if necessary a mean function, can be learned from the data, either b y setting them to maximum lik eliho od v alues, or by full-scale Bay esian inference using Mark ov chain Monte Carlo metho ds. See Rasm ussen and Williams (2006, § 5) and 17 Hennig and Schuler − 2 0 2 − 10 − 5 0 5 10 x f ( x ) base k ernel p oly lik − 2 0 2 − 50 0 50 100 150 200 x f ( x ) base k ernel p oly lik Figure 8: Generalizing GP regression. Left: Samples from differen t priors. Righ t: P os- teriors (mean, t wo standard deviations) after observing three datap oin ts with negligible noise (k ernel parameters differ b et w een the tw o plots). base : standard GP regression with Mat ´ ern k ernel. kernel : sum of t wo k ernels (square exp onen tial and rational quadratic) of differen t length scales and strengths. p oly : p olynomial (here: quadratic) mean function. lik : Non-Gaussian lik eliho o d (here: logarithmic link function). The scales of b oth x and f ( x ) are functions of kernel param- eters, so the n umerical v alues in this plot ha ve relev ance only relative to eac h other. Note the strong differences in both mean and co v ariance functions of the p osteriors. Murra y and Adams (2010) for details. In the latter case, the b elief p ( f ) ov er the function is a mixture of Gaussian pro cesses. T o still b e able to use the algorithm derived so far, w e appro ximate this b elief with a single Gaussian pro cess b y calculating exp ected v alues of mean and co v ariance function. Ideally , one would wan t to tak e accoun t of this hierarchical learning pro cess in the decision problem addressed by the optimizer. This adds another la y er of computation com- plexit y to the problem, and is outside of the scop e of this pap er. Here, we con tend ourselv es with considering the uncertain ty of the Gaussian pro cess conditioned on a particular set of h yp erparameters. 2.8.3 Limit a tions and Extensions of Gaussian Processes f or Optimiza tion Lik e any probability measure ov e r functions, Gaussian pro cess measures are not arbitrarily general. In particular, the most widely used k ernels, including the tw o men tioned ab o ve, are stationary , meaning they only dep end on the difference b et ween lo cations, not their absolute v alues. Lo osely sp eaking, the prior “lo oks the same everywhere”. One may argue that many real optimization problems do not hav e this structure. F or example, it ma y b e 18 Entropy Search kno wn that the function tends to ha ve larger functions v alues to ward the boundaries of I or, more v aguely , that it is roughly “b o wl-shap ed”. F ortunately , a num b er of extensions readily suggest themselv es to address such issues (Figure 8). P arametric Means As p oin ted out in Section 2.1, we are free to add any parametric general linear mo del as the mean function of the Gaussian pro cess. m ( x ) = X i φ i ( x ) w i (20) Using Gaussian beliefs on the w eights w i of this model, this mo del may be learned at the same time as the Gaussian process itself (Rasm ussen and Williams, 2006, § 2.7). P olynomials suc h as the quadratic φ ( x ) = [ x ; xx | ] are b eguiling in this regard, but they create an explicit “origin” at the cen ter of I , and induce strong long-range cor- relations b etw een opp osite ends of I . This seems pathological: In most settings, observing the function on one end of I should not tell us muc h ab out the v alue at the opp osite end of I . But w e ma y more generally c ho ose an y feature set for the linear mo del. F or example, a set of radial basis functions φ i ( x ) = exp( k x − c i k 2 /` 2 i ) around lo cations c i at the rims of I can explain large function v alues in a region of width ` i around suc h a feature, without ha ving to predict large v alues at the center of I . This idea can b e extended to a nonparametric version, describ ed in the next p oin t. Comp osite Kernels Since k ernels form a semiring, w e may sum a k ernel of large length scale and large signal v ariance and a kernel of short length scale and low signal v ari- ance. F or example k ( x, x 0 ) = k SE ( x, x 0 ; s 1 , S 1 ) + k RQ ( x, x 0 , s 2 , S 2 , α 2 ) s 1 s 2 ; S ij 1 S ij 2 ∀ i, j (21) yields a kernel ov er functions that, within the b ounded domain I , lo ok lik e “rough troughs”: global curv ature paired with lo cal stationary v ariations. A disadv antage of this prior is that it thinks “domes” just as likely as “b o wls”. An adv antage is that it is a v ery flexible framework, and do es not induce un wan ted global correlations. Nonlinear Lik eliho o ds An altogether differen t effect can b e ac hiev ed by a non-Gaussian, non-linear likelihoo d function. F or example, if f is kno wn to b e strictly p ositiv e, one ma y assume the noise mo del p ( y | g ) = N ( y ; exp( g ) , σ 2 ); f = exp( g ) (22) and learn g instead of f . Since the logarithm is a con vex function, the minim um of the latent g is also a minium of f . Of course, this likelihoo d leads to a non-Gaussian p osterior. T o retain a tractable algorithm, appro ximate inference metho ds can be used to construct appro ximate Gaussian p osteriors. In our example (labeled lik in Figure 8), we used a Laplace appro ximation: It is straightforw ard to show that Equation (22) implies ∂ log p ( y | g ) ∂ g g =ˆ g ! = 0 ⇒ ˆ g = log y ∂ 2 log p ( y | g ) ∂ 2 g g =ˆ g = y 2 σ 2 (23) 19 Hennig and Schuler − 3 − 2 . 5 − 2 − 1 . 5 − 1 − 0 . 5 0 0 . 5 1 1 . 5 2 2 . 5 3 g = log( f ) p ( y | f ) Figure 9: Laplace approximation for a logarithmic Gaussian lik eliho od. T rue lik eliho od in red, Gaussian approximation in blue, maxim um likelihoo d solution marked in grey . F our log relative v alues a = log( y /σ ) of sample y and noise σ (scaled in heigh t for readability). a = − 1 (solid); a = 0 (dash-dotted); a = 1 (dashed); a = 2 (dotted). The approximation is go o d for a 0. so a Laplace appro ximation amoun ts to a heteroscedastic noise mo del, in whic h an observ ation ( y , σ 2 ) is incorp orated into the Gaussian pro cess as (log( y ) , ( σ /y ) 2 ). This appro ximation is v alid if σ y (see Figure 3). F or functions on logarithmic scales, ho wev er, finding minima smaller than the noise lev el, at logarithmic resolution, is a considerably harder problem anyw ay . The righ t part of Figure 8 sho ws p osteriors pro duced using the three approac hes detailed ab o v e, and the base case of a single kernel with strong signal v ariance, when presented with the same three data p oin ts, with very lo w noise. The strong difference b et ween the p osteriors ma y b e disapp oin ting, but it is a fundamental asp ect of inference: Different prior assumptions lead to different p osteriors, and function space inference is imp ossible without priors. Each of the four b eliefs shown in the Figure ma y b e preferable o ver the others in particular situations. The p olynomial mean describ es functions that are almost parab olic. The exp onential lik eliho o d approximation is appropriate for functions with an intrinsic logarithmic scale. The sum k ernel approac h is p ertinen t for the search for lo cal minima of globally stationary functions. Classic metho ds based on p olynomial appro ximations are a lot more restrictiv e than any of the mo dels describ ed ab o ve. P erhaps the most general option is to use additional prior information I giving p ( x min | I ), indep enden t of p ( f ), to enco de outside information ab out the lo cation of the minim um. Unfortunately , this is intractable in general. But it may be approac hed through approxi- mations. This option is outside of the scope of this pap er, but will b e the sub ject of future w ork. 20 Entropy Search Algorithm 1 Entrop y Search 1: pro cedure EntropySear ch ( k , l = p ( y | f ( x )) , u, H , ( x , y )) 2: ˜ x ∼ u ( x , y ) B discretize using measure u (Section 2.2) 3: [ µ , Σ , ∆ µ x , ∆ Σ x ] ^ GP ( k , l , x , y ) B infer function, innov ation, from GP prior (2.1) 4: [ ˆ q min ( ˜ x ) , ∂ ˆ q min ∂ µ , ∂ 2 ˆ q min ∂ µ∂ µ , ∂ ˆ q min x ∂ Σ ] ^ EP ( µ , Σ ) B appro ximate ˆ p min (2.3) 5: if H=0 then 6: return q min B A t horizon, return b elief for final decision 7: else 8: x 0 ^ arg min hLi x B predict information gain; Eq. (18) 9: y 0 ^ Ev alua te ( f ( x 0 )) B tak e measurement 10: EntropySear ch ( k , l , u, H − 1 , ( x , y ) ∪ ( x 0 , y 0 )) B mov e to next ev aluation 11: end if 12: end pro cedure 2.9 Summary – the En tire Algorithm Algorithm 1 sho ws pseudo code for En tropy Search. It takes as input the prior, describ ed b y the k ernel k , and the lik eliho o d l = p ( y | f ( x )), as well as the discretization measure u (whic h may itse lf b e a function of previous data, the Horizon H , and an y previously col- lected observ ations ( x , y ). T o choose where to ev aluate next, w e first sample discretization p oin ts from u , then calculate the curren t Gaussian b elief ov er f on the discretized domain, along with its deriv atives. W e construct an approximation to the b elief ov er the minimum using Exp ectation Propagation, again with deriv atives. Finally , we construct a first order appro ximation on the exp ected information gain from an ev aluation at x 0 and optimize nu- merically . W e ev aluate f at this lo cation, then the cycle rep eats. Up on publication of this w ork, ma tlab source co de for the algorithm and its sub-routines will b e made av ailable online. 3. Exp erimen ts Figures in previous sections pro vided some intuition and anecdotal evidence for the effi- cacy of the v arious approximations used by En trop y Searc h. In this section, w e compare the resulting algorithm to t w o Gaussian pro cess global optimization heuristics: Exp ected Impro vemen t, Probability of Impro vemen t (Section 1.1), as w ell as to a con tin uous armed bandit algorithm: GP-UCB (Sriniv as et al., 2010). F or reference, we also compare to a n umber of numerical optimization algorithms: T rust-Region-Reflectiv e (Coleman and Li, 1996, 1994), Activ e-Set (Po well, 1978b,a), interior p oin t (Byrd et al., 1999, 2000; W altz et al., 2006), and a na ¨ ıvely pro jected version of the BFGS algorithm (Bro yden et al., 1965; Fletc her, 1970; Goldfarb, 1970; Shanno, 1970). W e av oid implementation bias b y using a uniform co de framew ork for the three Gaussian process-based algorithms, i.e. the algorithms share co de for the Gauss ian process inference and only differ in the wa y they calculate their utilit y . F or the local numerical algorithms, w e used third part y co de: The pro jected BF GS 21 Hennig and Schuler metho d is based on co de by Carl Rasm ussen 3 , the other metho ds come from version 6.0 of the optimization to olbox of ma tlab 4 . In some comm unities, optimization algorithms are tested on hand-crafted test functions. This runs the risk of in tro ducing bias. Instead, w e compare our algorithms on a num b er of functions sampled from a generativ e mo del. In the first exp eriment, the function is sampled from the mo del used by the GP algorithms themselv es. This eliminates all mo del-mismatc h issues and allo ws a direct comparison of other GP optimizers to the probabilistic optimizer. In a second exp erimen t, the functions were sampled from a mo del strictly more general than the mo del used by the algorithms, to sho w the effect of mo del mismatch. 3.1 Within-Mo del Comparison The first exp erimen t w as carried out ov er the 2-dimensional unit domain I = [0 , 1] 2 . T o generate test functions, 1000 function v alues w ere jointly sampled from a Gaussian pro cess with a squared-exp onen tial cov ariance function of length scale ` = 0 . 1 in each direction and unit signal v ariance. The resulting p osterior mean w as used as the test function. All algorithms had access to noisy ev aluations of the test functions. F or the b enefit of the n umerical optimizers, noise was kept relatively low: Gaussian with standard deviation σ = 10 − 3 . All algorithms w ere tested on the same set of 40 test functions, all Figures in this section are av erages ov er those sets of functions. It is non trivial to provide error bars on these av erage estimates, b ecause the data sets ha ve no parametric distribution. But the regular structure of the plots, giv en that individual exp erimen ts were drawn i.i.d., indicates that there is little remaining sto c hastic error. After eac h function ev aluation, the algorithms were asked to return a b est guess for the minim um x min . F or the lo cal algorithms, this is simply the p oin t of their next ev aluation. The Gaussian pro cess based methods returned the global minim um of the mean b elief o v er the function (found by lo cal optimization with random restarts). Figure 10 shows the dif- ference b et w een the global optim um of the function and the function v alue at the rep orted b est guesses. Since the best guesses do not in general lie at a datap oin t, their qualit y can actually decrease during optimization. The most obvious feature of this plot is that lo cal optimization algorithms are not adept at finding global minima, which is not surprising, but giv es an intuition for the difficult y of problems sampled from this generative mo del. The plot shows a clear adv antage for Entrop y Search ov er its competitors, even though the algorithm do es not directly aim to optimize this particular loss function. The flattening out of the error of all three global optimizers tow ard the right is due to ev aluation noise (recall that ev aluations include Gaussian noise of standard deviation 10 − 3 ). In terestingly , En tropy Searc h flattens out at an error almost an order of magnitude low er than that of the nearest comp etitor, Exp ected Improv emen t. One p ossible explanation for this b eha v- ior is a pathology in the classic heuristics: Both Exp ected Improv ement and Probabilit y of Improv ement require a “current best guess” η , which has to b e a p oin t estimate, b e- cause prop er marginalization ov er an uncertain b elief is not tractable. Due to noise, it can 3. http://www.gaussianprocess.org/gpml/code/matlab/util/minimize.m , version using BFGS: p er- sonal comm unication 4. http://www.mathworks.de/help/toolbox/optim/rn/bsqj zi.html 22 Entropy Search 0 10 20 30 40 50 60 70 80 90 100 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 10 1 # of ev aluations | f min − ˆ f min | trust region reflective activ e set in terior p oin t BF GS GP UCB prob. of improv ement exp ected improv ement en tropy search Figure 10: Distance of function v alue at optimizers’ b est guess for x min from true global minim um. Log scale. 23 Hennig and Schuler 0 10 20 30 40 50 60 70 80 90 100 10 − 4 10 − 3 10 − 2 10 − 1 10 0 # of ev aluations | x min − ˆ x min | trust region reflective activ e set in terior p oin t BF GS GP UCB prob. of improv ement exp ected improv ement en tropy search Figure 11: Euclidean distance of optimizers’ b est guess for x min from truth. Log scale. th us happ en that this b est guess is o v erly optimistic, and the algorithm then explores too aggressiv ely in later stages. Figure 11 s ho ws data from the same exp erimen ts as the previous figure, but plots Eu- clidean distance from the true global optimum in input space, rather than in function v alue space. The results from this view are qualitativ ely similar to those sho wn in Figure 10. Since Entrop y Search attempts to optimize information gain from ev aluations, one w ould also lik e to compare to algorithms on the en tropy loss function. Ho wev er, this is c hallenging. First, the lo cal optimization algorithms provide no probabilistic mo del of the function and can thus not pro vide this loss. But even for the optimization algorithms based on Gaussian pro cess measures, it is c hallenging to ev aluate this loss glob al ly with go o d resolution. The only option is to approximately calculate entrop y , using the v ery algorithm in tro duced in this pap er. Doing so amounts to a kind of circular experiment that En tropy Search wins b y definition, so we omit it here. W e pointed out in Section 1.1 that the bandit setting differs considerably from the kind of optimization discussed in this pap er, b ecause bandit algorithms try to minimize regret, rather than improv e an estimate of the function’s optimum. T o clarify this p oin t further, Figure 12 sho ws the regret r ( T ) = T X t =1 [ y t − f min ] (24) for each of the algorithms. Notice that probabilit y of impro vemen t, whic h p erforms worst among the global algorithms as seen from the previous t wo measures of p erformance, ac hieves the low est regret. The intuition here is that this heuristic fo cusses ev aluations 24 Entropy Search 0 10 20 30 40 50 60 70 80 90 100 0 50 100 150 200 250 300 # of ev aluations regret GP UCB prob. of improv ement exp ected improv ement en tropy search Figure 12: Regret as a function of num b er of ev aluations. on regions known to giv e lo w function v alues. In con trast, the actual v alue of the function at the evaluation p oint has no sp ecial role in Entrop y Search. The utility of an ev aluation p oin t only dep ends on its exp ected effect on knowledge ab out the minimum of the function. Surprisingly , the one algorithm explicitly designed to ac hieve low regret, GP-UCB, per- forms w orst in this comparison. This algorithm chooses ev aluation p oin ts according to (Sriniv as et al., 2010) x next = arg min x [ µ ( x ) − β 1 / 2 σ ( x )] where β = 4( D + 1) log T + C ( k , δ ) (25) with T , the num b er of previous ev aluations, D , the dimensionality of the input domain, and C ( k , δ ) is a constant that dep ends on some analytic prop erties of the kernel k and a free parameter, 0 < δ < 1. W e found it hard to find a go od setting for this δ , which clearly has influence on the algorithm’s p erformance. The results sho wn here represent the b est p erformance ov er a set of 4 exp erimen ts with differen t c hoices for δ . They appear to b e sligh tly worse than, but comparable to the empirical p erformance rep orted by the original pap er on this algorithm (Sriniv as et al., 2010, Figure 5a). 3.2 Out-of-Mo del Comparison In the previous section, the algorithms attempted to find minima of functions sampled from the prior used b y the algorithms themselves. In real applications, one can rarely hop e to b e so lucky , but hierarc hical inference can b e used to generalize the prior and construct a relativ ely general algorithm. But what if ev en the hierarchically extended prior class do es not contain the true function? Qualitatively , it is clear that, b ey ond a certain 25 Hennig and Schuler 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 0 . 2 0 . 4 0 . 6 0 . 8 1 − 2 0 2 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 0 . 2 0 . 4 0 . 6 0 . 8 1 − 1 0 1 2 3 Figure 13: Left: A sample from the GP prior with squared exponential kernel used in the on-mo del exp erimen ts of Section 3.1. Righ t: Sample from prior with the rational quadratic k ernel used for the out of mo del comparison of Section 3.2. p oin t of mo del-mismatc h, all algorithms can b e made to p erform arbitrarily badly . The p oor p erformance of lo cal optimizers (which may b e in terpreted as building a quadratic mo del) in the previous section is an example of this effect. In this section, w e present results of the same kind of exp erimen ts as in the previous section, but on a set of 30 tw o- dimensional functions sampled from a Gaussian proces s prior with r ational quadr atic k ernel, with the same length scale and signal v ariance as ab ov e, and scale mixture parameter α = 1 (see Equation (7)). This means samples evolv e o ver an infinite n um b er of differen t length scales, including b oth longer and shorter scales than those cov ered b y the priors of the algorithms (Figure 13). Figure 14 shows error on function v alues, Figure 15 Euclidean error in input space, Figure 16 regret. Note the different scales for the ordinate axes relative to the corresp onding previous plots: While Entrop y Searc h still (barely) outp erforms the comp etitors, all three algorithms p erform worse than b efore; and their errors b ecome more similar to each other. Ho wev er, they still manage to disco ver go o d regions in the domain, demonstrating a certain robustness to mo del-mismatc h. 4. Conclusion This pap er presen ted a new probabilistic paradigm for global optimization, as an inference problem on the minimum of the function, rather than the problem of collecting iteratively lo wer and low er function v alues. W e argue that this description is closer to practitioners’ requiremen ts than classic resp onse surface optimization, bandit algorithms, or other, heuris- tic, global optimization algorithms. In the main part of the pap er, w e constructed En tropy Searc h, a practical probabilistic global optimization algorithm, using a series of analytic assumptions and numerical appro ximations: A particular family of priors ov er functions 26 Entropy Search 0 10 20 30 40 50 60 70 80 90 100 10 − 4 10 − 3 10 − 2 10 − 1 10 0 10 1 # of ev aluations | f min − ˆ f min | GP UCB prob. of improv ement exp ected improv ement en tropy search Figure 14: F unction v alue error, off-mo del tasks. 0 10 20 30 40 50 60 70 80 90 100 10 − 3 10 − 2 10 − 1 10 0 # of ev aluations | x min − ˆ x min | GP UCB prob. of improv ement exp ected improv ement en tropy search Figure 15: Error on x min , off-mo del tasks. 27 Hennig and Schuler 0 10 20 30 40 50 60 70 80 90 100 0 50 100 150 200 # of ev aluations regret GP UCB prob. of improv ement exp ected improv ement en tropy search Figure 16: Regret, off-mo del tasks. (Gaussian pro cesses); constructing the b elief p min o ver the lo cation of the minimum on an irregular grid to deal with the curse of dimensionality; and using Exp ectation Propagation to ward an efficien t analytic appro ximation. The Gaussian b elief allows analytic probabilis- tic predictions of the effect of future datap oin ts, from whic h w e constructed a first-order appro ximation of the exp ected c hange in relative en trop y of p min to a base measure. F or completeness, we also pointed out some already kno wn analytic prop erties of Gaussian pro cess measures that can be used to generalize this algorithm. W e show ed that the re- sulting algorithm outp erforms b oth directly and distan tly related comp etitors through its more elab orate, probabilistic description of the problem. This increase in p erformance is exc hanged for somewhat increased computational cost (Entrop y Search costs are a constan t m ultiple of that of classic Gaussian pro cess global optimizers). So this algorithm is more suited for problems w ere e v aluating the function itself carries considerable cost. Never- theless, it pro vides a natural description of the optimization problem, by fo cusing on the p erformance under a loss function at the horizon, rather than function v alues returned dur- ing the optimization pro cess. It allows the practitioner to explicitly enco de prior knowledge in a flexible wa y , and adapts its b ehavior to the user’s loss function. Ac kno wledgments W e w ould lik e to thank Martin Kiefel for v aluable feedbac k, as well as T om Mink a for an in teresting discussion. 28 Entropy Search App endix A. Mathematical App endix The notation in Equation (1) can b e read, sloppily , to mean “ p min ( x ) is the probabilit y that the v alue of f at x is low er than at an y other ˜ x ∈ I ”. F or a contin uous domain, though, there are uncoun tably man y other ˜ x . T o giv e more precise meaning to this notation, consider the follo wing argument. Let there b e a sequence of lo cations { x i } i =1 ,...,N , such that for N _ ∞ the densit y of p oints at each lo cation conv erges to a measure m ( x ) nonzero on every op en neigh b orho od in I . If the sto c hastic pro cess p ( f ) is sufficiently regular to ensure samples are almost surely con tinuous (see footnote in Section 2.1), then almost ev ery sample can b e approximated arbitrarily w ell by a staircase function with steps of width m ( x i ) / N at the locations x i , in the sense that ∀ > 0 ∃ N 0 > 0 suc h that, ∀ N > N 0 : | f ( x ) − f (arg min x j ,j =1 ,...,N | x − x j | ) | < , where | · | is a norm (all norms on finite-dimensional v ector spaces are equiv alent). This is the original reason wh y samples from sufficiently regular Gaussian pro cesses can b e plotted using finitely man y p oin ts, in the wa y used in this pap er. W e no w define the notation used in Equation (1) to mean the follo wing limit, where it exists. p min ( x ) = Z p ( f ) Y ˜ x 6 = x θ ( f ( ˜ x ) − f ( x )) d f ≡ lim N _ ∞ | x i − x i − 1 |· N _ m ( x ) Z p [ f ( { x i } i =1 ,...,N )] N Y i =1; i 6 = j θ [ f ( x i ) − f ( x j )]d f ( { x i } i =1 ,...,N ) ·| x i − x i − 1 |· N (26) In w ords: The “infinite product” is mean t to be the limit of finite-dimensional in tegrals with an increasing num b er of factors and dimensions, where this limit exists. In doing so, w e ha ve side-stepped the issue of whether this limit exists for any particular Gaussian pro cess (i.e. kernel function). W e do so b ecause the theory of suprema of sto c hastic pro cesses is highly nontrivial. W e refer the reader to a friendly but demanding in tro duction to the topic by Adler (1990). F rom our applied standp oin t, the issue of whether (26) is w ell defined for a particular Gaussian prior is secondary: If it is known that the true function is con tinuous and b ounded, than it has a well-defined supremum, and the prior should reflect this knowledge by assigning sufficiently regular beliefs. If the actual prior is such that w e exp ect the function to b e discontin uous, it should be clear that optimization is extremely c hallenging anyw a y . W e conjecture that the finer details of the region betw een these tw o domains hav e little relev ance for comm unities in terested in optimization. References R.J. Adler. The ge ometry of r andom fields . Wiley , 1981. R.J. Adler. An in tro duction to con tinuit y , extrema, and related topics for general Gaussian pro cesses. L e ctur e Notes-Mono gr aph Series , 12:i–iii+v–vii+ix+1–55, 1990. Benoit. Note sˆ ure une m ´ etho de de r ´ esolution des ´ equations normales pro venan t de l’application de la m ´ etho de des moindres carr ´ es a un syst` eme d’ ´ equations lin ´ eaires en nom bre inf ´ erieure a celui des inconnues. Application de la m´ etho de a la r ´ esolution d’un 29 Hennig and Schuler syst ` eme d ´ efini d’ ´ equations lin ´ eaires. (proc´ ed´ e du Commandan t Cholesky). Bul letin ge o de- sique , 7(1):67–77, 1924. S.P . Boyd and L. V andenberghe. Convex Optimization . Cambridge Univ Press, 2004. C.G. Bro yden et al. A class of metho ds for solving nonlinear simultaneous equations. Math. Comp , 19(92):577–593, 1965. R.H. Byrd, M.E. Hribar, and J. No cedal. An interior p oin t algorithm for large-scale non- linear programming. SIAM Journal on Optimization , 9(4):877–900, 1999. R.H. Byrd, J.C. Gilb ert, and J. No cedal. A trust region metho d based on interior point tec hniques for nonlinear programming. Mathematic al Pr o gr amming , 89(1):149–185, 2000. T.F. Coleman and Y. Li. On the conv ergence of interior-reflectiv e newton metho ds for nonlinear minimization sub ject to b ounds. Mathematic al pr o gr amming , 67(1):189–224, 1994. T.F. Coleman and Y. Li. An interior trust region approach for nonlinear minimization sub ject to b ounds. SIAM Journal on Optimization , 6(2):418–445, 1996. R.T. Co x. Probability , frequency and reasonable exp ectation. Americ an Journal of Physics , 14(1):1–13, 1946. J. Cunningham, P . Hennig, and S. Lacoste-Julien. Gaussian probabilities and exp ectation propagation. under r eview. Pr eprint at arXiv:1111.6832 [stat.ML] , Nov ember 2011. R. Fletc her. A new approach to v ariable metric algorithms. The Computer Journal , 13(3): 317, 1970. D. Goldfarb. A family of v ariable metric up dates derived by v ariational means. Mathematics of Computing , 24(109):23–26, 1970. S. Gr ¨ unew¨ alder, J.Y. Audibert, M. Opper, and J. Sha we-T a ylor. Regret b ounds for Gaussian pro cess bandit problems. In Pr o c e e dings of the 14th International Confer enc e on Artificial Intel ligenc e and Statistics (AIST A TS) , 2010. N. Hansen and A. Ostermeier. Completely derandomized self-adaptation in evolution strate- gies. Evolutionary c omputation , 9(2):159–195, 2001. P . Hennig. Optimal reinforcement learning for Gaussian systems. In A dvanc es in Neur al Information Pr o c essing Systems , 2011. M.R. Hestenes and E. Stiefel. Metho ds of conjugate gradien ts for solving linear systems. Journal of R ese ar ch of the National Bur e au of Standar ds , 49(6):409–436, 1952. K. It¯ o. On sto c hastic differen tial equations. Memoirs of the Americ an Mathematic al So ciety , 4, 1951. E.T. Jaynes and G.L. Bretthorst. Pr ob ability The ory: the L o gic of Scienc e . Cam bridge Univ ersity Press, 2003. 30 Entropy Search D.R. Jones, M. Sc honlau, and W.J. W elc h. Efficien t global optimization of exp ensiv e black- b o x functions. Journal of Glob al optimization , 13(4):455–492, 1998. R. Klein b erg. Nearly tigh t b ounds for the con tinuum-armed bandit problem. A dvanc es in Neur al Information Pr o c essing Systems , 18, 2005. A.N. Kolmogorov. Grundb egriffe der W ahrsc heinlichk eitsrec hnung. Er gebnisse der Mathe- matik und ihr er Gr enzgebiete , 2, 1933. D.G. Krige. A statistical approac h to some basic mine v aluation and allied problems at the Wit watersrand. Master’s thesis, Universit y of Witw atersrand, 1951. S. Kullback and R.A. Leibler. On information and sufficiency. Annals of Mathematic al Statistics , 22(1):79–86, 1951. H. Lazard-Holly and A. Holly . Computation of the probabilit y that a d -dimensional normal v ariable b elongs to a p olyhedral cone with arbitrary vertex. T echnical rep ort, Mimeo, 2003. D.J. Lizotte. Pr actic al Bayesian Optimization . PhD thesis, Univ ersity of Alb erta, 2008. D.J.C. MacKa y . Choice of basis for Laplace appro ximation. Machine L e arning , 33(1):77–86, 1998a. D.J.C. MacKa y . In tro duction to Gaussian pro cesses. NA TO ASI Series F Computer and Systems Scienc es , 168:133–166, 1998b. B. Mat ´ ern. Spatial v ariation. Me ddelanden fr an statens Sko gsforskningsinstitut , 49(5), 1960. T.P . Mink a. Deriving quadrature rules from Gaussian pro cesses. T echnical report, Statistics Departmen t, Carnegie Mellon Universit y , 2000. T.P . Mink a. Exp ectation Propagation for approximate Bay esian inference. In Pr o c e e d- ings of the 17th Confer enc e in Unc ertainty in A rtificial Intel ligenc e , pages 362–369, San F rancisco, CA, USA, 2001. Morgan Kaufmann. ISBN 1-55860-800-1. I. Murray and R.P . Adams. Slice sampling cov ariance h yp erparameters of latent Gaussian mo dels. , 2010. J. No cedal and S.J. W right. Numeric al optimization . Springer V erlag, 1999. M.A. Osborne, R. Garnett, and S.J. Roberts. Gaussian processes for global optimization. In 3r d International Confer enc e on L e arning and Intel ligent Optimization (LION3) , 2009. R.L. Plack ett. A reduction formula for normal m ultiv ariate integrals. Biometrika , 41(3-4): 351, 1954. M.J.D. Po well. The conv ergence of v ariable metric metho ds for nonlinearly constrained optimization calculations. Nonline ar pr o gr amming , 3(0):27–63, 1978a. M.J.D. P o well. A fast algorithm for nonlinearly constrained optimization calculations. Nu- meric al analysis , pages 144–157, 1978b. 31 Hennig and Schuler C.E. Rasmussen and C.K.I. Williams. Gaussian Pr o c esses for Machine L e arning . MIT Press, 2006. L.M. Schmitt. Theory of genetic algorithms ii: models for genetic op erators o v er the string- tensor representation of p opulations and con v ergence to global optima for arbitrary fitness function under scaling. The or etic al Computer Scienc e , 310(1-3):181–231, 2004. M. Seeger. Exp ectation propagation for exp onential families. T echnical rep ort, U.C. Berke- ley , 2008. D.F. Shanno. Conditioning of quasi-Newton metho ds for function minimization. Mathe- matics of c omputation , 24(111):647–656, 1970. C.E. Shannon. A mathematical theory of comm unication. Bel l System T e chnic al Journal , 27, 1948. N. Sriniv as, A. Krause, S. Kak ade, and M. Seeger. Gaussian pro cess optimization in the ban- dit setting: No regret and exp erimen tal design. In International Confer enc e on Machine L e arning , 2010. M.B. Thompson and R.M. Neal. Slice sampling with adaptive multiv ariate steps: The shrinking-rank metho d. A rxiv pr eprint arXiv:1011.4722 , 2010. G.E. Uhlen b eck and L.S. Ornstein. On the theory of the Bro wnian motion. Physic al R eview , 36(5):823, 1930. A.W. v an der V aart and J.H. v an Zanten. Information rates of nonparametric Gaussian pro cess metho ds. Journal of Machine L e arning R ese ar ch , 12:2095–2119, 2011. R.A. W altz, J.L. Morales, J. No cedal, and D. Orban. An in terior algorithm for nonlinear op- timization that com bines line searc h and trust region steps. Mathematic al Pr o gr amming , 107(3):391–408, 2006. N. Wiener and P . Masani. The prediction theory of multiv ariate sto c hastic pro cesses. A cta Mathematic a , 98(1):111–150, 1957. 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment