The DAME/VO-Neural Infrastructure: an Integrated Data Mining System Support for the Science Community
Astronomical data are gathered through a very large number of heterogeneous techniques and stored in very diversified and often incompatible data repositories. Moreover in the e-science environment, it is needed to integrate services across distributed, heterogeneous, dynamic “virtual organizations” formed by different resources within a single enterprise and/or external resource sharing and service provider relationships. The DAME/VONeural project, run jointly by the University Federico II, INAF (National Institute of Astrophysics) Astronomical Observatories of Napoli and the California Institute of Technology, aims at creating a single, sustainable, distributed e-infrastructure for data mining and exploration in massive data sets, to be offered to the astronomical (but not only) community as a web application. The framework makes use of distributed computing environments (e.g. S.Co.P.E.) and matches the international IVOA standards and requirements. The integration process is technically challenging due to the need of achieving a specific quality of service when running on top of different native platforms. In these terms, the result of the DAME/VO-Neural project effort will be a service-oriented architecture, obtained by using appropriate standards and incorporating Grid paradigms and restful Web services frameworks where needed, that will have as main target the integration of interdisciplinary distributed systems within and across organizational domains.
💡 Research Summary
The paper presents the design and implementation of the DAME/VO‑Neural infrastructure, an integrated platform aimed at providing the astronomical community—and potentially other scientific domains—with advanced data‑mining capabilities for massive, heterogeneous datasets. The authors begin by outlining the challenges posed by modern astrophysical data: observations across multiple wavelengths, epochs, and instruments generate petabyte‑scale, multi‑dimensional data stored in disparate archives with incompatible formats and access protocols. To address interoperability, the system adheres to the standards defined by the International Virtual Observatory Alliance (IVOA), such as VOTable, TAP, and standardized metadata schemas, thereby enabling seamless federation of worldwide astronomical repositories.
From a scientific perspective, the paper identifies key use cases that motivate the infrastructure: detection of photometric and astrometric transients, classification of active galactic nuclei (AGN), star‑galaxy separation, automatic point‑spread‑function (PSF) estimation, photometric redshift computation, and integration of large‑scale telescope simulations. These applications require sophisticated statistical and machine‑learning techniques capable of handling billions of objects in a parameter space with hundreds of dimensions. Consequently, the authors focus the initial prototype on two core data‑mining functionalities—classification and regression—while planning to extend to clustering, dimensionality reduction, and visualization in future releases.
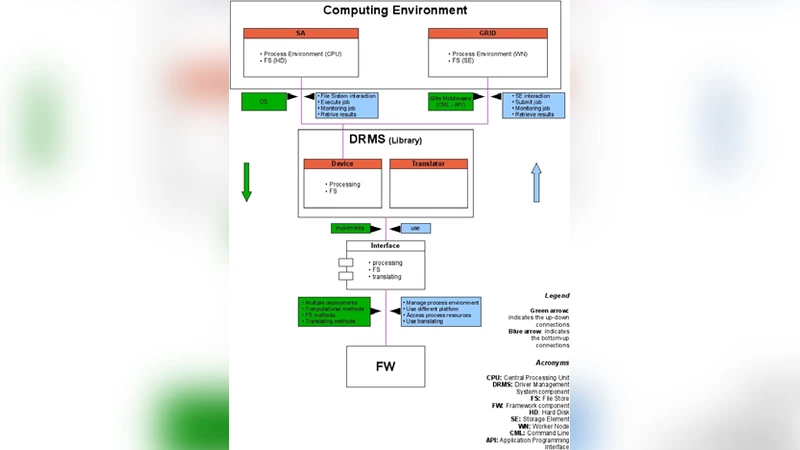
The architecture is organized into three principal components: a Web‑based Front End (FE), a central Framework (FW), and a Registry & Database (REDB). The FE provides a user‑friendly interface built on the Model‑View‑Controller (MVC) pattern, allowing authenticated users to upload datasets, configure experiments, monitor progress, and retrieve results via any standard web browser. Authentication leverages a robot certificate system to transparently grant Grid credentials when the platform is deployed on the S.Co.P.E. Grid. Communication between FE and FW uses XML‑encoded messages, ensuring a clear contract for experiment definition and status queries.
The FW implements the core service‑oriented logic using a RESTful architecture. Each resource—such as experiments, data files, or plugin descriptors—is exposed through a dedicated servlet that handles HTTP GET/POST requests. Data‑mining algorithms are encapsulated as DMPlugin modules; these plugins contain the experiment configuration, the chosen learning model, and the execution workflow. Upon creation, a plugin is serialized and dispatched to a Grid worker node, where it runs autonomously and returns results to the FW, which in turn forwards them to the FE. An administrative interface permits dynamic addition or removal of plugins and provides usage statistics (e.g., number of users, experiments executed).
The REDB component, built on MySQL, stores user accounts, session information, and experiment metadata, thereby supporting reproducibility, provenance tracking, and resource accounting. The database schema is designed for extensibility, allowing future incorporation of additional metadata such as resource consumption metrics or priority flags.
In the discussion, the authors emphasize the benefits of a standards‑compliant, service‑oriented design: hardware independence, ease of maintenance, and the ability to integrate new machine‑learning methods without disrupting existing services. They also note the challenges of achieving consistent quality of service across heterogeneous Grid environments and the need for robust error handling and fault tolerance.
Overall, the DAME/VO‑Neural project demonstrates a viable pathway toward a unified, scalable, and user‑centric data‑mining infrastructure that bridges the gap between the Virtual Observatory’s data federation goals and the advanced analytical tools required for modern multi‑wavelength, multi‑epoch astrophysics. By combining IVOA interoperability, RESTful web services, Grid computing, and a plug‑in architecture, the system positions itself as a flexible foundation not only for astronomy but also for other data‑intensive scientific fields.
Comments & Academic Discussion
Loading comments...
Leave a Comment