A Platform for Spreadsheet Composition
A huge amount of data is everyday managed in large organizations in many critical business sectors with the support of spreadsheet applications. The process of elaborating spreadsheet data is often performed in a distributed, collaborative way, where many actors enter data belonging to their local business domain to contribute to a global business view. The manual fusion of such data may lead to errors in copy-paste operations, loss of alignment and coherency due to multiple spreadsheet copies in circulation, as well as loss of data due to broken cross-spreadsheet links. In this paper we describe a methodology, based on a Spreadsheet Composition Platform, which greatly reduces these risks. The proposed platform seamlessly integrates the distributed spreadsheet elaboration, supports the commonly known spreadsheet tools for data processing and helps organizations to adopt a more controlled and secure environment for data fusion.
💡 Research Summary
The paper addresses the pervasive problem of data inconsistency, loss, and version chaos that arises when large organizations rely on spreadsheets for critical business processes in a distributed, collaborative setting. Traditional approaches—manual copy‑paste, cross‑workbook links, or ad‑hoc email circulation—are error‑prone and do not scale. To mitigate these risks, the authors propose a client‑server based Spreadsheet Composition Platform named DISCOM (Distributed Spreadsheet COMposition).
The core idea is to keep end‑users within their familiar Excel environment while introducing a central service that automatically synchronizes exported cell ranges and imports updates in near real‑time. A plug‑in, built with C# and Visual Studio Tools for Office, integrates directly into Microsoft Excel (2003/2007). Users designate export and import ranges through a graphical interface; the plug‑in converts the selected cells into a custom XML payload and sends it to the DISCOM server via SOAP web‑services. The server, implemented in Java with the Spring framework and backed by a MySQL database, stores the XML representations and metadata, handling authentication, CRUD operations, and access control.
Data propagation works in two directions. Exporters periodically scan their spreadsheets for changes and push updates to the server; importers poll the server for new contributions and refresh the local workbook accordingly. This mechanism ensures that any change made by a contributor is reflected in all dependent workbooks almost instantly.
A particularly challenging scenario is the “intermediate spreadsheet” that both consumes data from an upstream source and provides data to downstream consumers (e.g., A → B → C). If B goes offline, the chain would break. DISCOM solves this by uploading the entire intermediate workbook to the server. When B is offline, the server runs a lightweight spreadsheet engine (using Apache POI) to recalculate formulas based on the latest imported values, then updates the exported ranges. Consequently, downstream users receive up‑to‑date data even when an intermediate node is unavailable.
Access control is realized through the concept of a “Space.” A Space is a logical collection of users (creator, exporters, importers) that defines who can see or modify particular data sets. This aligns with hierarchical corporate structures and allows fine‑grained permission management.
Deployment can be on‑premises—giving enterprises full control over data residency and security—or as a cloud service (e.g., an Amazon Machine Image on EC2) for quicker setup and lower operational overhead.
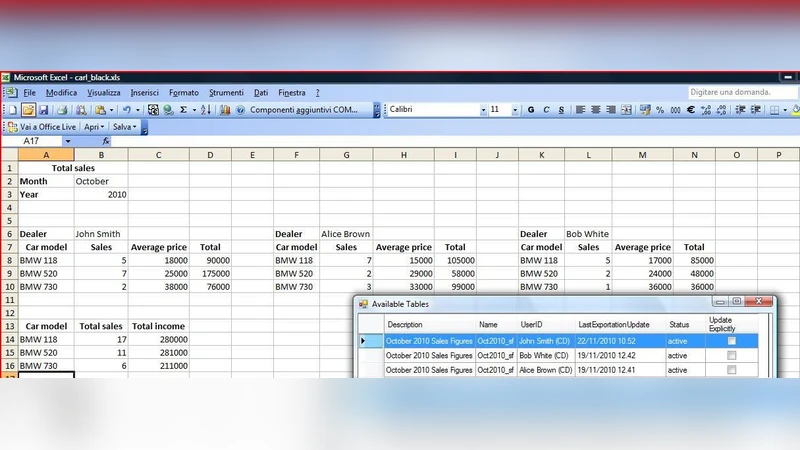
The authors illustrate the platform with a realistic car‑dealer scenario. Each dealer (CD) installs the plug‑in, exports a standardized four‑column sales table, and restricts visibility to the Area Sales Manager (ASM). The ASM imports all dealer contributions, applies performance‑index formulas, and publishes a consolidated comparison spreadsheet. The system automatically synchronizes updates: when a dealer records a new sale, the ASM’s performance index updates instantly, even if the ASM is not actively working on the spreadsheet.
Compared with existing solutions such as Excel cross‑links, Google Docs, or SharePoint, DISCOM offers several advantages: (1) it preserves the familiar Excel UI, requiring no programming skills; (2) it reuses existing spreadsheets without forcing migration; (3) it supports hierarchical, geographically distributed organizations; (4) it guarantees “always‑on” data propagation, handling offline intermediate nodes; and (5) it provides granular access control through Spaces.
Limitations are acknowledged. The current implementation is Windows‑Excel specific, relies on SOAP (which has higher overhead than modern RESTful APIs), and may encounter performance bottlenecks with very large data volumes due to repeated XML serialization and database writes.
Future work suggested includes extending support to web‑based spreadsheet editors, adopting REST/JSON communication, implementing data compression and streaming for large datasets, and integrating machine‑learning based data‑quality checks.
In conclusion, DISCOM demonstrates a practical, scalable approach to secure, automated, and consistent spreadsheet composition in enterprise environments, bridging the gap between end‑user computing convenience and enterprise‑grade data governance.
Comments & Academic Discussion
Loading comments...
Leave a Comment