From Good Practices to Effective Policies for Preventing Errors in Spreadsheets
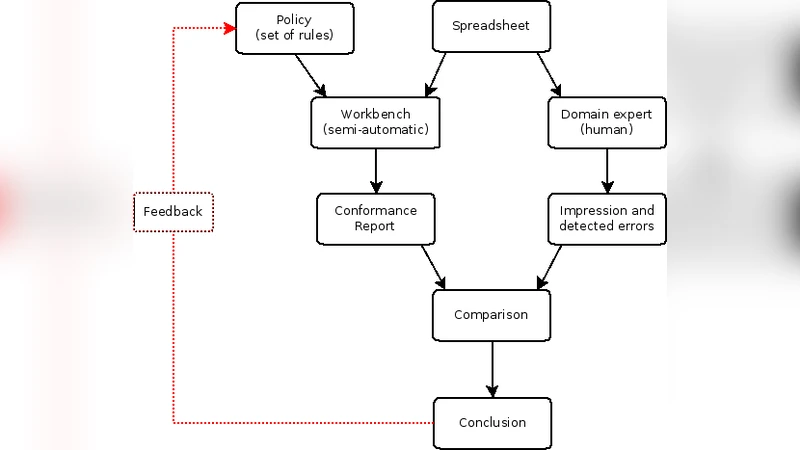
Thanks to the enormous flexibility they provide, spreadsheets are considered a priceless blessing by many end-users. Many spreadsheets, however, contain errors which can lead to severe consequences in some cases. To manage these risks, quality managers in companies are often asked to develop appropriate policies for preventing spreadsheet errors. Good policies should specify rules which are based on “known-good” practices. While there are many proposals for such practices in literature written by practitioners and researchers, they are often not consistent with each other. Therefore no general agreement has been reached yet and no science-based “golden rules” have been published. This paper proposes an expert-based, retrospective approach to the identification of good practices for spreadsheets. It is based on an evaluation loop that cross-validates the findings of human domain experts against rules implemented in a semi-automated spreadsheet workbench, taking into account the context in which the spreadsheets are used.
💡 Research Summary
Spreadsheets are ubiquitous because of their flexibility, but the prevalence of errors in operational spreadsheets poses serious risks to organizations. Although many “best‑practice” recommendations have been published, they often conflict and lack empirical validation, leaving quality managers without scientifically grounded policies. This paper proposes a retrospective, expert‑driven methodology to bridge that gap by converting practice recommendations into concrete policy rules and validating them against real‑world spreadsheets.
The approach consists of four main steps. First, a set of policy rules is derived from the literature (e.g., “use one formula per row/column”, “refer only to cells left or above”). These rules are packaged into a “scenario” that represents an organizational policy. Second, a domain expert manually reviews a sample spreadsheet, assigns an overall quality rating (good/poor) and notes any observed errors. Third, the same spreadsheet is processed by a semi‑automated workbench that checks for violations of the scenario’s rules and produces a detailed report of each breach. Fourth, the expert’s subjective rating is compared with the workbench’s violation list; rules that consistently appear only in spreadsheets rated as poor (and never in those rated as good) are identified as effective practices, while rules that generate false positives or false negatives are discarded.
The workbench is a stand‑alone, cross‑platform Java tool that can ingest Excel, OpenOffice Calc, and Google Docs files. Policies are defined as “scenarios” composed of configurable “rule checkers”. The current prototype includes four checkers (hard‑coded constants reused in formulas, missing cell protection, references to the right or below, cells containing only blanks) and allows users to set thresholds and exceptions via a graphical UI. After analysis, the tool generates a report that can be filtered by cell, rule, or spreadsheet, and each finding includes a textual explanation and remediation suggestions, with optional visualizations supplied by the rule plug‑ins.
The authors acknowledge several limitations. Because the method analyzes only the current state of a spreadsheet, it cannot assess process‑oriented practices such as early‑stage testing or version‑controlled development, nor can it distinguish a spreadsheet that deteriorated over time from one that was originally flawed. Moreover, the approach is limited to practices that can be expressed as computable rules; qualitative aspects that require human judgment remain outside its scope. The reliance on a single domain expert also introduces subjectivity, though the authors argue that consensus among multiple experts would mitigate this risk.
Despite these constraints, the proposed methodology offers a pragmatic pathway for organizations to derive evidence‑based spreadsheet policies. By iteratively refining scenarios—adding, removing, or re‑configuring rule checkers based on the comparison of expert assessments and automated findings—quality managers can converge on a set of “golden rules” that demonstrably correlate with higher spreadsheet quality in a given context. The paper positions this work as a step toward closing the gap between practice and science in spreadsheet governance, and outlines future work such as extending rule coverage, integrating version‑control information, and conducting larger multi‑expert studies to strengthen the statistical validity of the identified practices.
Comments & Academic Discussion
Loading comments...
Leave a Comment