Unleashing the Power of Distributed CPU/GPU Architectures: Massive Astronomical Data Analysis and Visualization case study
Upcoming and future astronomy research facilities will systematically generate terabyte-sized data sets moving astronomy into the Petascale data era. While such facilities will provide astronomers with unprecedented levels of accuracy and coverage, the increases in dataset size and dimensionality will pose serious computational challenges for many current astronomy data analysis and visualization tools. With such data sizes, even simple data analysis tasks (e.g. calculating a histogram or computing data minimum/maximum) may not be achievable without access to a supercomputing facility. To effectively handle such dataset sizes, which exceed today’s single machine memory and processing limits, we present a framework that exploits the distributed power of GPUs and many-core CPUs, with a goal of providing data analysis and visualizing tasks as a service for astronomers. By mixing shared and distributed memory architectures, our framework effectively utilizes the underlying hardware infrastructure handling both batched and real-time data analysis and visualization tasks. Offering such functionality as a service in a “software as a service” manner will reduce the total cost of ownership, provide an easy to use tool to the wider astronomical community, and enable a more optimized utilization of the underlying hardware infrastructure.
💡 Research Summary
The paper addresses the emerging challenge in astronomy of processing and visualizing data sets that now routinely reach terabyte and eventually petabyte scales. Traditional analysis tools, which assume that the entire data set can reside in the memory of a single workstation, become infeasible for even simple operations such as histogramming or finding global minima and maxima. To overcome these limits, the authors propose a general‑purpose framework that combines many‑core CPUs with large numbers of graphics processing units (GPUs) in a distributed, heterogeneous architecture.
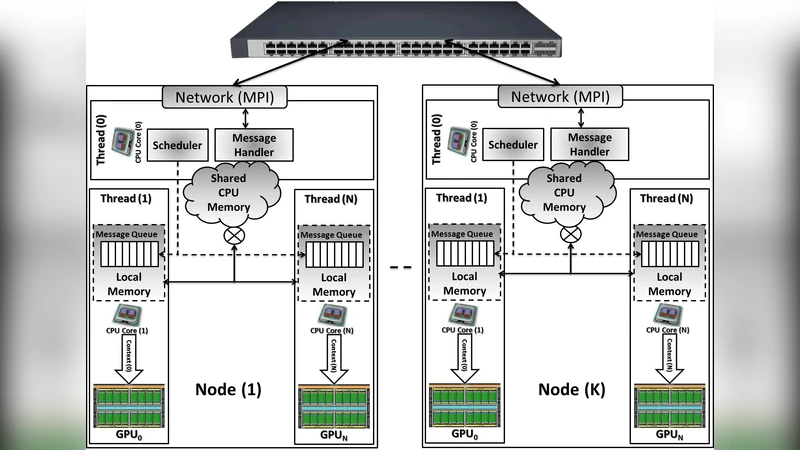
In the proposed design each GPU on a compute node is paired with a dedicated CPU core that prepares input data, launches a CUDA kernel, and performs any required post‑processing. Communication follows a master‑slave pattern: a master thread on each node handles inter‑node messaging via MPI, while slave threads manage local data exchange through shared memory protected by semaphores. The framework exploits CUDA 4.0’s Unified Virtual Addressing to treat CPU and GPU memory as a single address space, thereby reducing explicit memory copies. Moreover, multiple CUDA streams (execution queues) are used to overlap data transfers with kernel execution, maximizing bandwidth utilization on both the PCIe bus and the network interconnect.
Performance is demonstrated with a worst‑case workload: real‑time volume rendering of spectral data cubes that exceed the memory capacity of a single machine. The authors tested data cubes ranging from 4 GB to 204 GB on a cluster comprising 64 nodes, each equipped with two NVIDIA GPUs (total 128 GPUs). Frame rates of 33–55 fps were achieved, corresponding to a peak processing throughput of 2.5 teravoxels per second. Because the communication is split into a local stage (GPU‑CPU shared memory) and a global stage (MPI), the amount of data transferred across the network is reduced by at least 50 % compared with naïve approaches. The scaling behavior follows a 1/N reduction in communication overhead, where N is the number of GPUs per node, confirming the efficiency of the mixed shared‑distributed memory model.
Beyond raw performance, the paper argues for delivering the framework as a Software‑as‑a‑Service (SaaS) platform. A thin‑client visualization front‑end built with Qt5 allows astronomers to submit analysis jobs, interact with rendered volumes, and retrieve results without installing or maintaining any high‑performance hardware locally. This model promises lower total cost of ownership, easier access for a broader community, and the ability to integrate with private cloud resource‑management systems for on‑demand scaling. The authors illustrate the practical relevance by considering a 1 TB spectral cube expected from the Australian Square Kilometre Array Pathfinder (ASKAP). Processing such a cube on a single GPU would require partitioning into roughly 170 sub‑cubes and multiple data loads, which is acceptable for single‑pass statistics but infeasible for multi‑pass algorithms (e.g., median, standard deviation). The distributed GPU framework keeps the entire cube in memory across the cluster, enabling global operations with reasonable latency.
In summary, the work demonstrates that a carefully engineered combination of CPU cores, GPUs, shared memory, and MPI can turn petascale astronomical data analysis from an intractable problem into a tractable, service‑oriented capability. The results suggest that future large‑scale observatories will benefit from adopting similar heterogeneous, cloud‑ready infrastructures to meet the growing demands of data‑intensive astronomy.
Comments & Academic Discussion
Loading comments...
Leave a Comment