A New Proposed Technique to Improve Software Regression Testing Cost
In this article, we describe the regression test process to test and verify the changes made on software. A developed technique use the automation test based on decision tree and test selection process in order to reduce the testing cost is given. The developed technique is applied to a practical case and the result show its improvement.
💡 Research Summary
The paper addresses the high cost of regression testing in software maintenance and proposes a technique that combines test‑selection with an automated‑test‑viability decision process. After a brief introduction that cites legacy statistics (maintenance consumes 40‑70 % of total lifecycle cost, regression testing up to 50 % of testing effort), the authors list a variety of maintenance cost factors (team stability, application type, program structure, staff skills, etc.) and describe the classic categories of software maintenance (corrective, adaptive, perfective, preventive).
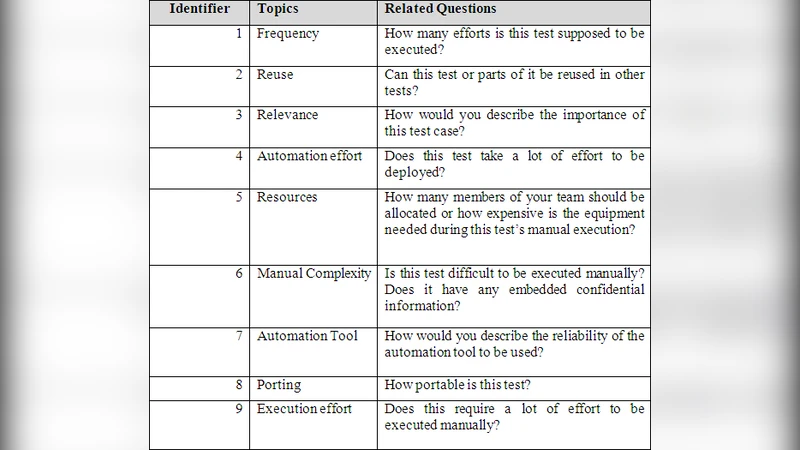
In the verification section the authors review common testing methods—black‑box, white‑box, debugging, profiling, mutation testing, beta testing—and then focus on test automation. They argue that automation reduces human error, enables parallel execution, eliminates interruptions, and simplifies result analysis, but also warn that indiscriminate automation can be wasteful. To make automation decisions more systematic they introduce an “Automation Test Viability Method” (ATVM) consisting of a questionnaire with seven items (frequency of execution, re‑use potential, importance of the test case, reliability of the automation tool, etc.). Each answer is classified as High, Medium, or Low.
Using the responses of 500 existing automated test cases, the authors automatically construct a decision tree. Nodes correspond to questionnaire items; branches are taken according to the H/M/L answer; leaf nodes output either “Yes” (the test is a good candidate for automation) or “No”. The tree is illustrated in Figure 5, and a concrete example from an insurance system (customer registration) is walked through: low execution frequency, medium re‑use, high importance, high tool reliability → final “Yes”. The authors claim that this process reduces the number of tests that need to be automated and therefore cuts cost.
The paper then surveys regression‑testing techniques: Retest‑All, Test‑Case Prioritization (general and version‑specific), Hybrid approaches (combining selection and prioritization), and Regression Test Selection (RTS). RTS is described as partitioning the existing suite into reusable, retestable, and obsolete cases, possibly generating new tests for uncovered code. Three RTS families—coverage‑based, minimization‑based, and safe techniques—are listed, together with Rothermel’s evaluation criteria (inclusiveness, precision, efficiency, generality).
A risk‑based regression‑testing approach is introduced next, citing Chen & Probert and Amland. Risk exposure is defined as probability of fault presence multiplied by potential loss. The authors adopt a simple two‑element risk model to compute a risk score for each test case and use it to prioritize execution.
The proposed decision‑tree method is applied to a real‑world insurance application (SNA‑Soft). The authors state that the technique “improved” regression‑testing cost, but they provide no quantitative data: no execution‑time measurements, no cost breakdown, no defect‑detection statistics, and no statistical validation. The comparison with other techniques (Retest‑All, prioritization, classic RTS) is only narrative, lacking tables or graphs. Moreover, the questionnaire’s mapping to actual cost savings is not calibrated; the High/Medium/Low labels are purely qualitative, and the process for converting them into numeric weights is omitted.
From a technical standpoint, the decision‑tree construction is treated as a black box; there is no discussion of the learning algorithm (e.g., CART, C4.5), pruning strategies, over‑fitting prevention, or cross‑validation. Consequently, it is unclear whether the tree outperforms standard machine‑learning classifiers for the same task. The paper also fails to address how the method scales to large test suites (thousands of test cases) or to continuous‑integration pipelines where test selection must be performed automatically for each build.
In summary, the contribution of the paper is an informal framework for deciding which regression tests to automate, based on a small set of qualitative questions organized in a decision tree. While the idea of structuring expert judgment is sensible, the manuscript suffers from several shortcomings: (1) lack of up‑to‑date empirical data; (2) insufficient methodological detail for reproducing the decision tree; (3) no rigorous comparison with existing automated‑test‑selection or risk‑based approaches; (4) absence of statistical validation of claimed cost reductions; and (5) poor writing quality, numerous typographical errors, and missing figures/tables that are referenced but not shown.
Future work should (a) formalize the questionnaire into measurable metrics, (b) collect a large, diverse dataset of test cases across multiple domains, (c) apply standard machine‑learning evaluation (precision, recall, F‑measure) to the decision‑tree model, (d) report concrete cost‑benefit numbers (e.g., percentage reduction in test‑execution time, manpower hours saved), and (e) integrate the method into an automated CI/CD pipeline to demonstrate practical scalability. Only with such rigorous validation can the proposed technique be considered a substantive advancement in regression‑testing cost optimization.
Comments & Academic Discussion
Loading comments...
Leave a Comment