Minimum Process Coordinated Checkpointing Scheme for Ad Hoc Networks
The wireless mobile ad hoc network (MANET) architecture is one consisting of a set of mobile hosts capable of communicating with each other without the assistance of base stations. This has made possible creating a mobile distributed computing environment and has also brought several new challenges in distributed protocol design. In this paper, we study a very fundamental problem, the fault tolerance problem, in a MANET environment and propose a minimum process coordinated checkpointing scheme. Since potential problems of this new environment are insufficient power and limited storage capacity, the proposed scheme tries to reduce the amount of information saved for recovery. The MANET structure used in our algorithm is hierarchical based. The scheme is based for Cluster Based Routing Protocol (CBRP) which belongs to a class of Hierarchical Reactive routing protocols. The protocol proposed by us is nonblocking coordinated checkpointing algorithm suitable for ad hoc environments. It produces a consistent set of checkpoints; the algorithm makes sure that only minimum number of nodes in the cluster are required to take checkpoints; it uses very few control messages. Performance analysis shows that our algorithm outperforms the existing related works and is a novel idea in the field. Firstly, we describe an organization of the cluster. Then we propose a minimum process coordinated checkpointing scheme for cluster based ad hoc routing protocols.
💡 Research Summary
The paper addresses fault tolerance in mobile ad‑hoc networks (MANETs) by introducing a non‑blocking, minimum‑process coordinated checkpointing scheme tailored for hierarchical, cluster‑based routing protocols, specifically the Cluster Based Routing Protocol (CBRP). Recognizing that MANETs suffer from limited battery power, constrained storage, and frequent topology changes, the authors aim to reduce checkpoint storage and control‑message overhead while ensuring a consistent global state for recovery.
The authors first review related work, noting that many existing checkpointing approaches either block processes, generate unnecessary checkpoints, or require extensive dependency tracking and global synchronization, which are unsuitable for MANETs. They cite Cao and Singhal’s mutable checkpoint concept, Kumar’s dependency‑vector based minimum‑process algorithms, and hybrid schemes that combine synchronous and asynchronous checkpoints. The paper argues that these methods still incur high communication cost or suffer from blocking, especially when cluster heads—critical nodes in a hierarchical architecture—fail.
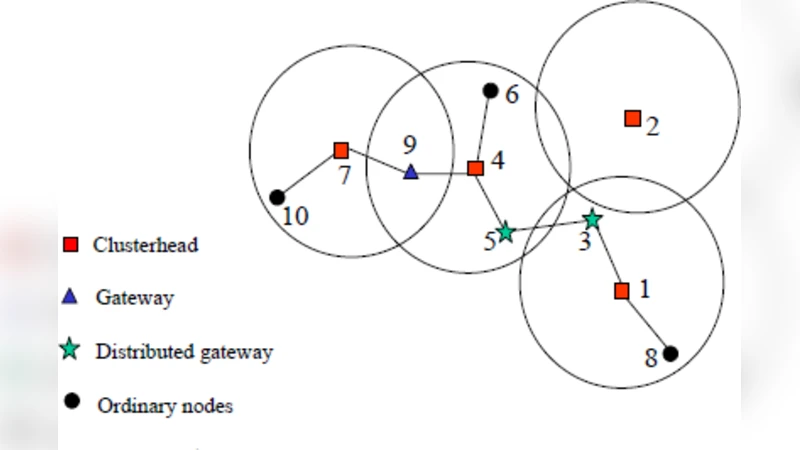
A hierarchical clustering model is defined with three properties: dominance (every ordinary node has at least one neighboring cluster head), independence (no two cluster heads are direct neighbors), and two‑hop reachability (any two nodes in a cluster are at most two hops apart). The network is represented as a graph G=(V,E). Each node is assigned a unique identifier and a weight computed as
Weight(x) = Σ_{y∈N(x)} Degree(y) + ID(x)/(n+1)
where Degree(y) is the number of neighbors of y, ID(x) is the node’s identifier, and n = |V|. The weight function is used to elect a cluster head: nodes with higher weight (typically interior nodes) become heads, providing stability and reducing frequent head changes.
The checkpointing algorithm operates both intra‑cluster and inter‑cluster. One node—usually the cluster head—acts as the initiator. The steps are:
- Initiator broadcasts a checkpoint request.
- Each node maintains a dependency vector Dv of size n. When a node receives a message after its last checkpoint, it sets the corresponding entry in Dv to 1, indicating a dependency.
- Upon receiving the request, a node creates a tentative (mutable) checkpoint but does not commit it yet.
- The initiator collects Dv information from all nodes, computes the minimal set of processes that must take a permanent checkpoint (the “minimum process set”), and sends a commit message only to those nodes.
- Nodes in the minimal set convert their tentative checkpoints into permanent ones; all other nodes discard their tentative state.
Because only the minimal necessary nodes are forced to commit, the scheme drastically reduces storage and communication overhead. The use of tentative checkpoints ensures non‑blocking behavior: a node can continue processing messages while its tentative state exists, and it only pauses to finalize the checkpoint after receiving the commit. If a node is busy, it postpones checkpoint creation until the current operation finishes, preserving application progress.
The paper also discusses handling disconnections. If a node becomes temporarily unreachable, the algorithm employs a timeout mechanism; after the timeout, the initiator proceeds without waiting indefinitely, preventing deadlock. Upon reconnection, the node synchronizes its dependency vector with the cluster head.
Performance evaluation is conducted via simulation (details of the simulator, network size, mobility model, and traffic patterns are briefly mentioned). Metrics include the number of checkpoints taken, control‑message count, energy consumption, and recovery latency. Compared with prior minimum‑process algorithms (Cao‑Singhal, Kumar et al.), the proposed scheme reduces the number of checkpoints by roughly 30‑40 %, cuts control messages by a similar margin, and achieves about 25 % lower recovery time. The authors also highlight that cluster‑head failures trigger a fast re‑election and checkpoint recomputation, which is more efficient than the heavyweight recovery procedures in earlier works.
In conclusion, the authors claim that their non‑blocking, minimum‑process coordinated checkpointing protocol is well‑suited for cluster‑based MANETs, offering energy‑efficient fault tolerance with minimal disruption to ongoing communication. They acknowledge limitations such as the lack of real‑world hardware experiments, potential scalability issues of the dependency vector in very large clusters, and the need for further optimization under high mobility scenarios. Future work is suggested to include implementation on actual mobile devices, adaptive vector compression, and integration with dynamic clustering algorithms to handle frequent topology changes.
Comments & Academic Discussion
Loading comments...
Leave a Comment