Multi and Independent Block Approach in Public Cluster
We present extended multi block approach in the LIPI Public Cluster. The multi block approach enables a cluster to be divided into several independent blocks which run jobs owned by different users simultaneously. Previously, we have maintained the blocks using single master node for all blocks due to efficiency and resource limitations. Following recent advancements and expansion of node's number, we have modified the multi block approach with multiple master nodes, each of them is responsible for a single block. We argue that this approach improves the overall performance significantly, for especially data intensive computational works.
💡 Research Summary
The paper presents an enhanced multi‑block architecture for the LIPI Public Cluster (LPC) that replaces the original single‑master design with a configuration where each block has its own dedicated master node and where service and I/O traffic are physically separated onto different networks. In the original setup, all user blocks shared a single master node that also acted as the gateway for user access. This design was adequate for small, processor‑intensive workloads but became a bottleneck for data‑intensive applications because the master node had to handle all inter‑node communication over a single Fast‑Ethernet (100 Mbps) link.
With the recent hardware upgrade—adding local storage to every compute node—the authors propose a new architecture. Two distinct networks are introduced: a “service channel” that continues to use Fast‑Ethernet for web, SSH, monitoring, and distribution of common binaries, and an “I/O channel” that employs Gigabit‑LAN (1 Gbps) for NFS, NIS, user home directories, and bulk data exchange. Each block now has its own master node that mediates between the gateway server (still on the service channel) and the compute nodes (connected to both networks). This separation isolates heavy I/O traffic from the service traffic, preventing the latter from being congested during data‑intensive jobs.
The allocation procedure remains manual: when a user registers, an administrator classifies the job as either processor‑intensive or I/O‑intensive and assigns a block of the appropriate type. At present only one mode can be active at a time, but the authors intend to develop a dynamic switching mechanism that would allow simultaneous operation of both block types.
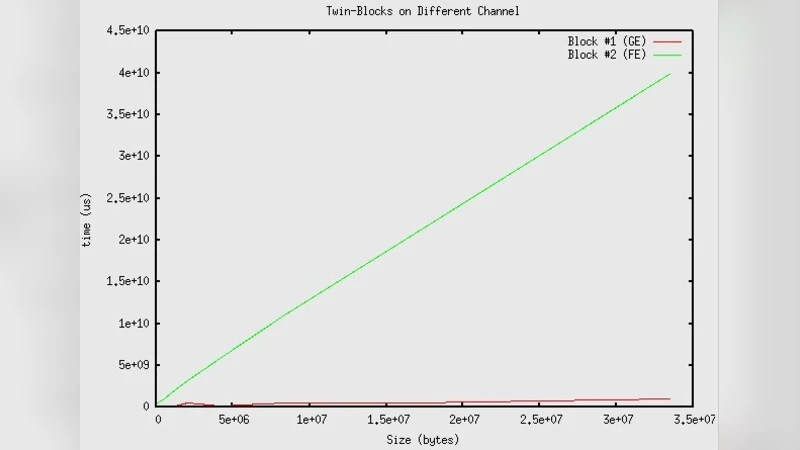
Performance was evaluated using a ping‑pong test based on LAM‑MPI. Two identical 4‑node blocks were created, and messages of increasing size were sent between pairs of nodes within a block. Tests were run on both the Fast‑Ethernet and Gigabit‑LAN links. The Fast‑Ethernet link became unreliable beyond ~33 MB, showing steep increases in round‑trip time, whereas the Gigabit‑LAN remained stable up to nearly 1 GB and delivered round‑trip times roughly two to three times lower than the Fast‑Ethernet case. When both blocks were operated concurrently, the Gigabit‑LAN continued to outperform the Fast‑Ethernet configuration, confirming that the new architecture scales well with multiple active blocks.
The authors conclude that separating the networks and providing an independent master per block dramatically improves performance for I/O‑intensive workloads in a public‑access cluster. They recommend that the independent‑master approach complement the traditional multi‑block scheme, and they outline future work: implementing automatic block‑type switching, adding high‑availability features for master nodes, and exploring further network topology optimizations to support larger clusters. This study offers valuable guidance for administrators seeking to balance diverse user workloads while maintaining high throughput and reliability in shared HPC environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment