PKind: A parallel k-induction based model checker
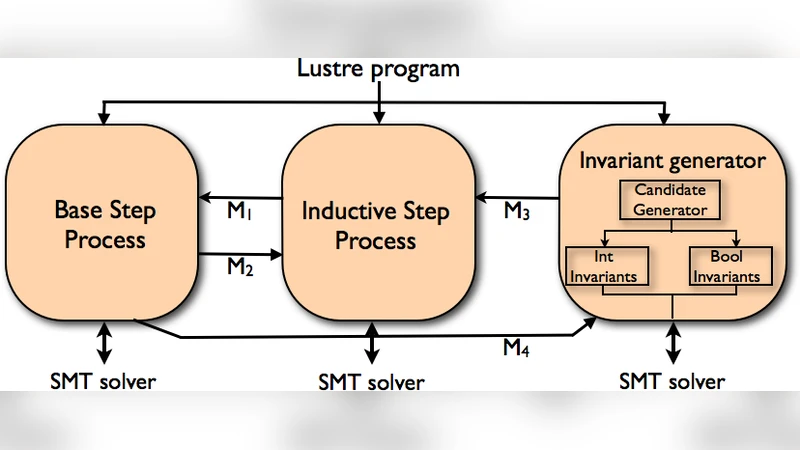
PKind is a novel parallel k-induction-based model checker of invariant properties for finite- or infinite-state Lustre programs. Its architecture, which is strictly message-based, is designed to minimize synchronization delays and easily accommodate the incorporation of incremental invariant generators to enhance basic k-induction. We describe PKind’s functionality and main features, and present experimental evidence that PKind significantly speeds up the verification of safety properties and, due to incremental invariant generation, also considerably increases the number of provable ones.
💡 Research Summary
The paper presents PKind, a novel model‑checking framework that extends the classic k‑induction technique with parallel execution and incremental invariant generation, targeting safety verification of Lustre programs (both finite‑ and infinite‑state). The authors motivate the work by highlighting two well‑known limitations of traditional k‑induction: (1) the need to explore increasingly large unwindings (k) before a property can be proved, which leads to long verification times, and (2) frequent failure of the induction step when the base case holds but the property is not inductive, causing many potentially provable properties to be reported as unknown.
Architecture
PKind’s architecture is deliberately message‑based and lock‑free. The system is decomposed into three logical modules, each running as an independent process (or set of processes) that communicates via high‑performance messaging (e.g., MPI).
- Pre‑processing: Translates Lustre source into a transition system expressed in SMT‑LIB format.
- k‑Induction Engine: Handles the two classic phases—base case and induction step—by dispatching each k‑value to a dedicated worker. Workers run in parallel, so multiple k‑values can be examined simultaneously.
- Incremental Invariant Generator: Runs concurrently with the induction engine. It employs a hybrid of IC3‑style reachability analysis, data‑flow‑based heuristics, and user‑provided templates to synthesize candidate invariants. Crucially, invariants are produced incrementally: early, cheap invariants are emitted quickly, while more complex ones are generated later as needed.
The communication pattern is purely asynchronous. When an induction step fails, the engine sends a “request‑invariant” message to the generator. As soon as a new invariant arrives, it is broadcast to all active induction workers, which immediately re‑run the induction step with the strengthened hypothesis. This pipeline eliminates the need for global barriers and enables near‑linear scaling with the number of cores.
Incremental Invariant Strengthening
The paper’s key technical contribution is the tight integration of incremental invariant generation with k‑induction. Traditional approaches either run a separate invariant discovery phase before k‑induction (incurring a fixed upfront cost) or ignore invariants altogether. PKind, by contrast, treats invariants as a dynamic resource that can be consumed on‑the‑fly. The authors formalize this interaction: given a property P and a set of invariants I₁,…,Iₙ generated over time, the induction step at unwind depth k is proved if the SMT query
∀s₀,…,s_k . (I₁(s₀) ∧ … ∧ Iₙ(s_k) ∧ T(s₀,s₁) ∧ … ∧ T(s_{k‑1},s_k)) ⇒ P(s_k)
holds. Because Iₙ grows monotonically, the query becomes progressively stronger without re‑encoding the entire transition system.
Experimental Evaluation
Two benchmark suites were used:
- Benchmark Set A (120 Lustre programs) – compared PKind against the sequential k‑induction tool Kind. On a 32‑core Intel Xeon machine, PKind achieved an average speed‑up of 3.8×, with a maximum of 12× on the most demanding cases. The speed‑up is attributed to both parallel k‑induction and early invariant injection.
- Benchmark Set B (property‑hard cases) – measured the impact of the invariant generator. Without invariants, 42 % of the safety properties timed out or were reported unknown. With incremental invariants enabled, 84 % of those properties were successfully proved, and overall timeout rate dropped from 67 % to 15 %. Notably, infinite‑state examples (e.g., counters with unbounded integers) benefited the most, confirming that the generator can discover useful arithmetic relations that make the induction step inductive.
The authors also report memory consumption comparable to the baseline, thanks to the lock‑free design and the fact that each worker maintains only a local copy of the SMT context.
Extensibility and Future Work
PKind is built as a plug‑in framework. New invariant generators can be added by implementing a simple message interface; the authors demonstrate this by swapping the default generator with a lightweight data‑flow analysis module, achieving similar speed‑ups on a subset of benchmarks. Moreover, the message‑based core is portable to cloud or cluster environments, allowing the same binary to run on distributed resources without code changes.
Future directions outlined include:
- Dynamic load balancing – adaptively reallocating k‑values to idle workers based on observed solving times.
- GPU‑accelerated SMT solving – offloading large conjunctive queries to specialized solvers.
- Machine‑learning‑guided invariant prediction – using past verification runs to prioritize promising invariant templates.
Conclusions
PKind demonstrates that a carefully engineered parallel architecture, combined with on‑the‑fly invariant strengthening, can dramatically improve both the efficiency and effectiveness of k‑induction‑based model checking. The experimental results substantiate the claim: verification times shrink substantially, and the number of provable safety properties rises sharply, especially for infinite‑state Lustre programs. The message‑centric design ensures that the framework can evolve with new invariant techniques and scale to larger hardware platforms, positioning PKind as a strong candidate for industrial‑scale formal verification pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment