Storage Balancing in Self-organizing Multimedia Delivery Systems
Many of the current bio-inspired delivery networks set their focus on search, e.g., by using artificial ants. If the network size and, therefore, the search space gets too large, the users experience high delays until the requested content can be consumed. In previous work, we proposed different replication strategies to reduce the search space. In this report we further evaluate measures for storage load balancing, because peers are most likely limited in space. We periodically apply clean-ups if a certain storage level is reached. For our evaluations we combine the already introduced replication measures with least recently used (LRU), least frequently used (LFU) and a hormone-based clean-up. The goal is to elaborate a combination that leads to low delays while the replica utilization is high.
💡 Research Summary
The paper addresses the challenge of storage load balancing in self‑organizing peer‑to‑peer (P2P) multimedia delivery systems that use bio‑inspired mechanisms. Building on earlier work that applied artificial‑ant search and hormone‑based signaling, the authors propose a set of replication strategies combined with three clean‑up policies—Least Recently Used (LRU), Least Frequently Used (LFU), and a hormone‑based clean‑up—to keep peer storage usage within limits while minimizing request latency and maximizing replica utilization.
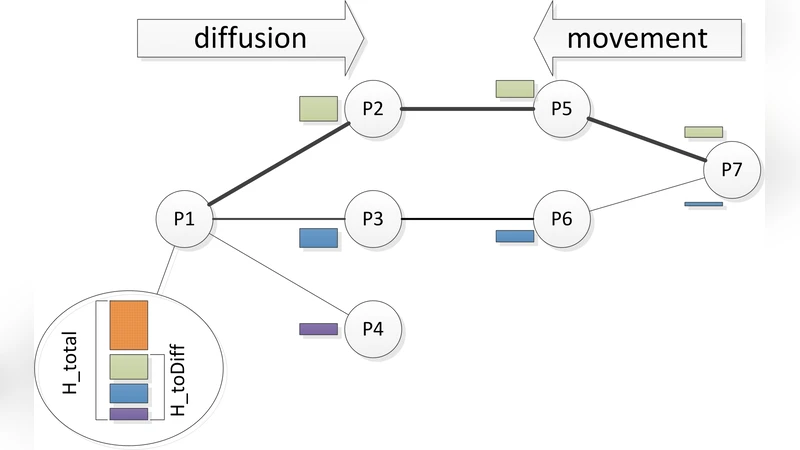
The underlying delivery algorithm works as follows: when a user requests a multimedia unit (a photo or short video clip), a hormone associated with the request’s keyword is generated at the requester node. Hormones are real‑valued quantities that diffuse through neighboring nodes, forming a gradient that points toward the requester. Units that match the keyword move “up‑hill” along the steepest hormone gradient, eventually arriving at the requester. Hormone diffusion parameters (initial strength η₀, incremental increase η, diffusion fraction α, evaporation ε, and movement threshold m) are inter‑dependent; to obtain a well‑behaved system the authors employ a genetic algorithm to optimise these parameters for maximal client satisfaction (i.e., the number of units delivered before their deadline).
Replication is needed because a single copy of a unit would have to travel sequentially to each requester, causing long detours. Six replication policies are examined: (1) Owner replication (copy at the requester), (2) Path replication (cache at every intermediate hop), (3) Path‑adaptive replication (probabilistic caching based on node resources), (4) Simple hormone replication (replicate when two or more neighbours hold hormones for the same unit), (5) Local popularity replication (keep units that rank in the top 30 % of local request history), and (6) Neighbor‑based popularity or hormone ranking (aggregate ranks from neighbours and replicate when the region rank is within a threshold).
Because peers have limited storage (each node provides 900 MB, initially filled to 30 % capacity), a clean‑up is triggered when usage exceeds 60 %. The three clean‑up mechanisms differ in their decision criteria: LRU removes the least recently accessed replica, LFU removes the least frequently accessed replica, and hormone‑based clean‑up deletes a replica only if no neighbour currently holds a hormone for that unit (i.e., there is no active demand). All policies respect a safety rule that at least one copy must remain on a neighbour to avoid total loss.
The authors evaluate the combined strategies using a discrete‑event simulator. Two network topologies are considered: a 50‑node Erdős‑Rényi random graph (diameter 6) and a 1,000‑node scale‑free graph (diameter 13). Units follow a size distribution (average 2.6 MB, range 190 KB–16 MB) and requests are generated via keyword searches that follow a Zipf‑like distribution. Each request may contain multiple keywords and carries a deadline derived from unit size, link bandwidth (100 Mbit/s), and a maximum hop count (10). If a deadline is missed, hormone generation for that unit stops, preventing further attraction.
Performance metrics include: (a) request latency (CDF of delivery time), (b) deadline‑miss rate (percentage of units whose deadline was exceeded), (c) request‑failure rate (requests where all constituent units missed their deadlines), and (d) replica utilization (ratio of concurrently presented units to total replicas).
Results show that the choice of clean‑up policy has a pronounced impact on latency and failure rates, and the effect is highly dependent on the underlying replication strategy. For instance, combining hormone‑based clean‑up with local‑popularity replication leads to a noticeable increase in latency because the clean‑up may delete replicas that are still needed for upcoming requests, despite low current hormone levels. Conversely, pairing LRU with path replication yields lower latency and maintains high utilization, as stale replicas are removed without harming units that are still in demand. LFU generally performs well across most replication schemes, striking a balance between removing rarely requested content and preserving popular items.
The study concludes that effective storage balancing in self‑organizing multimedia delivery systems requires coordinated design of replication and clean‑up mechanisms. Simple replication alone is insufficient; the clean‑up must be aware of both real‑time demand (hormone levels) and historical popularity to avoid degrading QoS. Future work is suggested on dynamic parameter adaptation, multi‑level hormone hierarchies, and real‑world deployment on mobile devices to further refine load‑balancing while preserving the robustness and adaptivity inherent to bio‑inspired P2P networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment