Applying Fuzzy ID3 Decision Tree for Software Effort Estimation
Web Effort Estimation is a process of predicting the efforts and cost in terms of money, schedule and staff for any software project system. Many estimation models have been proposed over the last three decades and it is believed that it is a must for the purpose of: Budgeting, risk analysis, project planning and control, and project improvement investment analysis. In this paper, we investigate the use of Fuzzy ID3 decision tree for software cost estimation; it is designed by integrating the principles of ID3 decision tree and the fuzzy set-theoretic concepts, enabling the model to handle uncertain and imprecise data when describing the software projects, which can improve greatly the accuracy of obtained estimates. MMRE and Pred are used as measures of prediction accuracy for this study. A series of experiments is reported using two different software projects datasets namely, Tukutuku and COCOMO'81 datasets. The results are compared with those produced by the crisp version of the ID3 decision tree.
💡 Research Summary
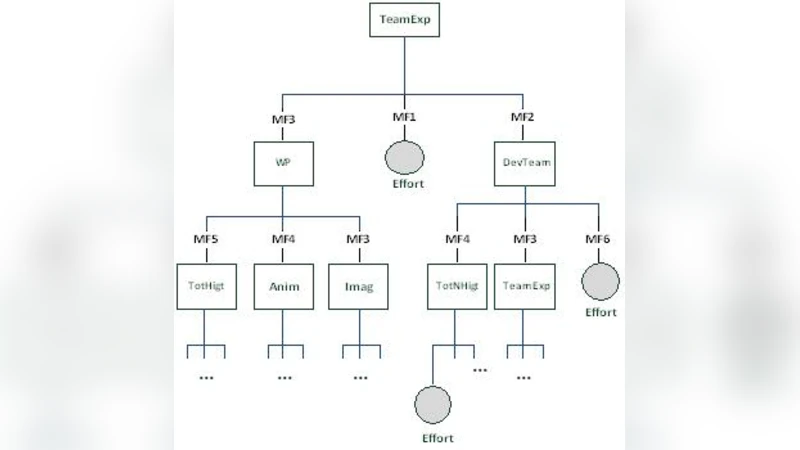
The paper proposes a fuzzy‑enhanced version of the classic ID3 decision‑tree algorithm—referred to as fuzzy ID3—to improve software effort estimation, a task traditionally plagued by uncertainty and imprecise input data. By integrating fuzzy set theory with the information‑theoretic foundation of ID3, the authors enable each training instance to belong to a node with a degree of membership rather than a binary assignment. This fuzzy membership is used to compute a “fuzzy entropy” (Equation 2) and an information gain (Equation 3) that guide tree growth. Two key design parameters are investigated: the choice of t‑norm (conjunction operator) for fuzzy intersection (minimum vs. product) and the significance level β, which determines the minimum membership a case must have to be considered part of a node.
The experimental evaluation employs two well‑known datasets: the Tukutuku web‑project dataset (53 projects, 9 attributes) and the COCOMO’81 dataset (252 projects, 13 attributes). For each dataset, the authors build two fuzzy ID3 models—one using the product t‑norm and the other using the minimum t‑norm—and vary β from 0.0 to 1.0 in steps of 0.1. Model performance is measured with two standard effort‑estimation metrics: Mean Magnitude of Relative Error (MMRE) and Pred(25), the percentage of projects whose MRE is ≤ 25 %. Acceptable thresholds in the literature are MMRE ≤ 25 % and Pred(25) ≥ 75 %.
Results on the Tukutuku dataset reveal that for very low β values (0.1–0.2) the product t‑norm yields exceptionally low MMRE (as low as 2.45 %) and high Pred(25) (≈ 97 %). However, as β increases beyond 0.2, the minimum t‑norm consistently outperforms the product version, delivering lower MMRE (e.g., 9.09 % at β = 0.5) while maintaining Pred(25) above 90 %. The COCOMO’81 experiments show a similar trend: the minimum t‑norm model achieves the best balance of low MMRE (≈ 12 % at β = 0.3) and high Pred(25) (≈ 88 %) across a broader β range, whereas the product t‑norm only excels at the smallest β values. These findings demonstrate that fuzzy ID3 can handle noisy, imprecise data more robustly than crisp ID3, provided that the conjunction operator and significance level are suitably tuned.
Beyond raw accuracy, the authors emphasize the “white‑box” nature of decision trees. The fuzzy ID3 tree remains interpretable: each split corresponds to a specific cost driver, and the degree of membership offers insight into how strongly a project exhibits a particular attribute. This transparency facilitates feature selection, as irrelevant or weakly contributing attributes are naturally pruned during tree growth. Consequently, project managers can identify the most influential cost drivers and understand the reasoning behind each effort estimate.
In conclusion, the study validates that augmenting ID3 with fuzzy logic yields statistically significant improvements in software effort estimation on both web‑centric and traditional datasets. The fuzzy ID3 model reduces both systematic under‑estimation and over‑estimation, satisfies industry‑accepted error thresholds, and retains interpretability—an essential requirement for practical project‑management tools. The paper suggests future work on optimizing membership‑function shapes, exploring hybrid ensembles that combine fuzzy decision trees with other machine‑learning techniques, and extending the approach to larger, more heterogeneous project repositories.
Comments & Academic Discussion
Loading comments...
Leave a Comment