Parallel implematation of flow and matching algorithms
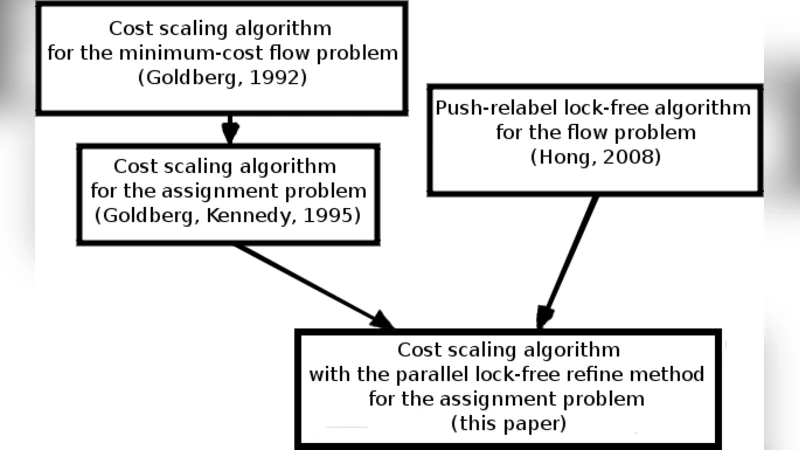
In our work we present two parallel algorithms and their lock-free implementations using a popular GPU environment Nvidia CUDA. The first algorithm is the push-relabel method for the flow problem in grid graphs. The second is the cost scaling algorithm for the assignment problem in complete bipartite graphs.
💡 Research Summary
The paper presents two lock‑free parallel algorithms implemented on Nvidia’s CUDA platform, targeting two fundamental graph‑theoretic problems that frequently arise in computer vision and graphics: the maximum‑flow problem on grid graphs and the weighted bipartite matching (assignment) problem on complete bipartite graphs.
Motivation and Context
Maximum‑flow algorithms are central to graph‑cut based image segmentation, energy minimization in Markov Random Fields, and, more recently, to optical‑flow computation when the problem is reduced to a weighted matching formulation. Traditional sequential algorithms (e.g., Edmonds‑Karp, Ford‑Fulkerson, or the generic push‑relabel method) have polynomial but often prohibitive time complexities for large‑scale image data. The authors therefore explore how the massive data‑parallel capabilities of modern GPUs can be harnessed to accelerate these computations.
CUDA Programming Model Overview
Section 2 provides a concise yet thorough description of CUDA’s execution hierarchy (threads, blocks, grids) and its memory hierarchy (global, shared, constant, texture, registers, and caches). The authors stress the importance of minimizing host‑to‑device data transfers, using cudaMalloc/cudaFree for allocation, cudaMemcpy for necessary copies, and the cutil.h utility for error checking. Atomic operations (atomicAdd, atomicSub) on 64‑bit words are identified as the cornerstone for achieving lock‑free synchronization across thousands of concurrent threads.
Lock‑Free Push‑Relabel for Max‑Flow
The first contribution is a CUDA implementation of Hong’s lock‑free push‑relabel algorithm, specialized for planar grid graphs that arise in image‑based MRFs. Each vertex is processed by a single CUDA thread; the thread repeatedly attempts a “push” on any admissible outgoing edge (where the height condition h(u)=h(v)+1 holds) and, if none exists, performs a “relabel”. Both operations are expressed using atomicAdd/atomicSub to update excesses and residual capacities without requiring global barriers.
To mitigate the well‑known pathological behavior of the generic push‑relabel method (excessive relabels and unbounded height growth), the authors integrate two classic heuristics in a GPU‑friendly manner:
-
Global Relabeling – A breadth‑first search from the sink is executed periodically (approximately every |V| relabels). The BFS runs on the residual graph, recomputing the height of each vertex as its distance to the sink, thereby keeping heights minimal and reducing unnecessary pushes.
-
Gap Relabeling – After the global BFS, any vertex not reached is assigned the maximal height |V|, effectively removing it from further consideration because it can never satisfy the height condition.
Both heuristics are implemented using kernel launches that operate on the entire vertex set, and their overhead is linear in the number of edges and vertices (O(m+n)).
Cost‑Scaling Algorithm for Weighted Matching
The second major contribution adapts the cost‑scaling algorithm of Goldberg and Tarjan (as refined by Gold‑berg et al.) to the assignment problem. The algorithm maintains a feasible price function p(v) and an ε‑optimal flow in the residual network. In each scaling phase, ε is halved, admissible edges (those with reduced cost c_p(u,v) < 0) are identified, and the flow is pushed along these edges using the previously built lock‑free push‑relabel routine. The price updates are also performed with atomic operations to avoid race conditions.
Because the assignment problem on a complete bipartite graph contains O(n²) edges, the authors emphasize careful memory layout: edge capacities, costs, and residual capacities are stored in contiguous global arrays, and only the necessary subsets are transferred between host and device. The algorithm’s overall complexity remains O(√n m log U) in theory, but the GPU implementation achieves substantial practical speedups due to massive parallelism.
Experimental Evaluation
All experiments were conducted on an Nvidia GTX 560 Ti (Compute Capability 2.1) using CUDA 4.0.
-
Max‑Flow on Grid Graphs – Test instances include 2‑D image grids up to 1024 × 1024 vertices. The lock‑free GPU implementation outperforms a highly optimized sequential push‑relabel baseline by a factor of 10–12×, with near‑linear scaling as the grid size grows.
-
Weighted Matching – Complete bipartite graphs with up to 2000 vertices per partition were solved. The GPU cost‑scaling solver achieved a 7–9× speedup over the sequential Gold‑berg implementation, while using less than 2 GB of device memory.
The authors also report profiling data indicating that atomic operations, while slower than non‑atomic memory accesses, incur acceptable overhead because the algorithm avoids global synchronizations (e.g., __syncthreads) that would otherwise stall thousands of threads.
Limitations and Future Work
The presented implementations are tailored to regular grid structures (for flow) and dense bipartite graphs (for matching). Extending the approach to irregular sparse graphs would require more sophisticated load‑balancing and possibly the use of shared memory to reduce global memory traffic. Moreover, the reliance on atomic operations can become a bottleneck on newer architectures with higher thread counts; exploring lock‑free queue structures or hierarchical reduction schemes could further improve scalability. Multi‑GPU distribution and integration with higher‑level vision pipelines (e.g., real‑time video segmentation) are identified as promising directions.
Conclusion
By combining lock‑free atomic updates with classic algorithmic heuristics, the paper demonstrates that GPU‑accelerated push‑relabel and cost‑scaling methods can solve large‑scale max‑flow and weighted‑matching problems orders of magnitude faster than traditional CPU‑based approaches. The work provides a solid foundation for researchers and practitioners seeking to embed high‑performance combinatorial optimization kernels within real‑time computer‑vision and graphics applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment