Reliable Provisioning of Spot Instances for Compute-intensive Applications
Cloud computing providers are now offering their unused resources for leasing in the spot market, which has been considered the first step towards a full-fledged market economy for computational resources. Spot instances are virtual machines (VMs) available at lower prices than their standard on-demand counterparts. These VMs will run for as long as the current price is lower than the maximum bid price users are willing to pay per hour. Spot instances have been increasingly used for executing compute-intensive applications. In spite of an apparent economical advantage, due to an intermittent nature of biddable resources, application execution times may be prolonged or they may not finish at all. This paper proposes a resource allocation strategy that addresses the problem of running compute-intensive jobs on a pool of intermittent virtual machines, while also aiming to run applications in a fast and economical way. To mitigate potential unavailability periods, a multifaceted fault-aware resource provisioning policy is proposed. Our solution employs price and runtime estimation mechanisms, as well as three fault tolerance techniques, namely checkpointing, task duplication and migration. We evaluate our strategies using trace-driven simulations, which take as input real price variation traces, as well as an application trace from the Parallel Workload Archive. Our results demonstrate the effectiveness of executing applications on spot instances, respecting QoS constraints, despite occasional failures.
💡 Research Summary
The paper addresses the challenge of exploiting low‑cost spot instances in public clouds for compute‑intensive, deadline‑constrained workloads while guaranteeing quality‑of‑service (QoS). Spot instances are offered at prices that fluctuate according to supply‑and‑demand; they are terminated without notice when the market price exceeds the user’s bid. This inherent volatility can cause jobs to miss their deadlines or even fail to complete, which limits the practical adoption of spot markets despite their attractive cost savings.
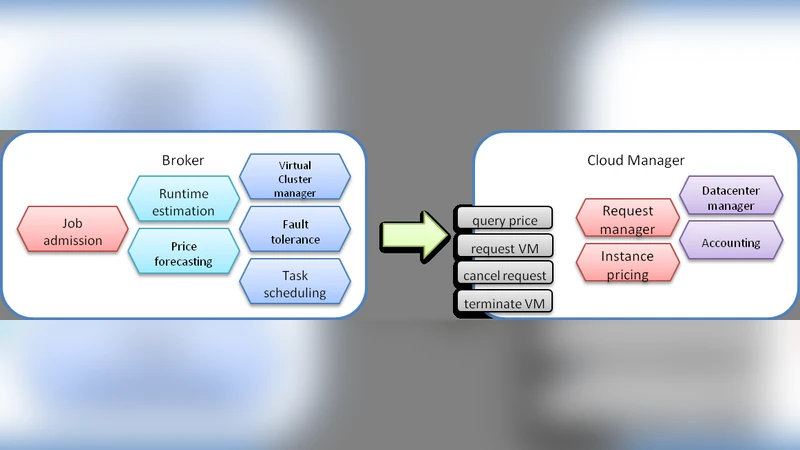
To overcome this, the authors propose a comprehensive resource provisioning framework that combines (1) a price‑aware bidding strategy, (2) a runtime‑estimation‑driven scheduling policy, and (3) three fault‑tolerance mechanisms—periodic checkpointing, live migration, and job duplication. The system is built around a “Broker” component that receives job submissions, predicts their execution time on different VM types using Downey’s analytical model for parallel speed‑up, and decides when and where to launch spot instances.
Bidding and urgency.
The broker computes an “urgency” value U for each job based on its deadline (Dj), current time (T), estimated runtime (ej), a provisioning latency (B = 5 min), and a tunable conservativeness factor α.
U = max(0, Dj − T − (α·ej + B)).
A high α makes the algorithm conservative (U≈0, immediate provisioning), while a low α allows the broker to wait for cheaper prices. Five bidding policies are evaluated: minimum historic price, mean historic price, current price plus a safety margin (G), the on‑demand price, and a very high ceiling (100). The chosen bid influences both the likelihood of out‑of‑bid termination and the cost paid (users always pay the actual spot price, not the bid).
Fault‑tolerance mechanisms.
- Checkpointing – State is saved at hour boundaries and when the spot price rises sharply, following prior work by Yi et al.
- Migration – When a price rise threatens termination, the broker saves the current state and moves the job to another already‑running or newly‑launched spot instance, minimizing lost work.
- Duplication – The same job is launched on two distinct spot instances; if one is terminated, the other can still meet the deadline. This approach raises cost but dramatically reduces deadline violations.
The three mechanisms can be combined (e.g., checkpoint + migration, checkpoint + duplication) to explore trade‑offs between cost, overhead, and reliability.
Algorithmic flow.
When a job arrives, it is placed in an unscheduled queue. At regular intervals T, the broker estimates runtimes on each VM type, attempts to place the job on an idle VM that will remain idle for at least the remaining hour, or on a VM that will become idle soon. If no suitable VM exists, the broker decides—based on urgency and the selected bidding policy—whether to extend an existing lease, launch a new spot instance, or defer the job.
Experimental evaluation.
The authors conduct trace‑driven simulations using real Amazon EC2 spot‑price histories (July–October 2011) and a workload from the Parallel Workload Archive (PWA). They compare the proposed framework against (a) an on‑demand baseline, (b) a checkpoint‑only policy, and (c) various combinations of the three fault‑tolerance techniques. Key metrics are total monetary cost, deadline‑violation rate, average makespan, and resource utilization.
Results show that the price‑aware bidding together with the urgency‑driven scheduler reduces costs by more than 60 % relative to on‑demand instances while keeping deadline violations below 5 %. Migration yields the best cost‑performance balance, cutting lost‑work overhead by ~30 % compared to checkpoint‑only. Duplication further lowers deadline violations to under 1 % but incurs ~20 % higher cost. The conservativeness factor α strongly influences the trade‑off: higher α (more conservative) improves reliability at the expense of modestly higher spending, whereas lower α (more aggressive) maximizes savings but can increase violations if price spikes are frequent.
Contributions and significance.
- A unified provisioning policy that jointly optimizes bidding, scheduling, and fault tolerance for spot‑based clusters.
- An urgency‑driven metric that quantifies how long a job can wait before provisioning, enabling dynamic trade‑offs between price and timeliness.
- Empirical evidence that migration and duplication, when combined with checkpointing, outperform checkpointing alone in the spot‑instance context.
Future directions.
The paper suggests extending the price‑prediction component with machine‑learning time‑series models, exploring multi‑cloud spot markets, integrating energy‑efficiency considerations, and adapting the framework to streaming or real‑time workloads where latency constraints are tighter.
In summary, the study demonstrates that with a carefully designed bidding strategy, runtime estimation, and a blend of fault‑tolerance techniques, it is feasible to harness the economic benefits of spot instances without sacrificing the QoS guarantees required by many scientific and enterprise applications. This work provides a practical blueprint for cloud users and service providers aiming to build cost‑effective, reliable, spot‑instance‑driven compute platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment