Multi-Instance Multi-Label Learning
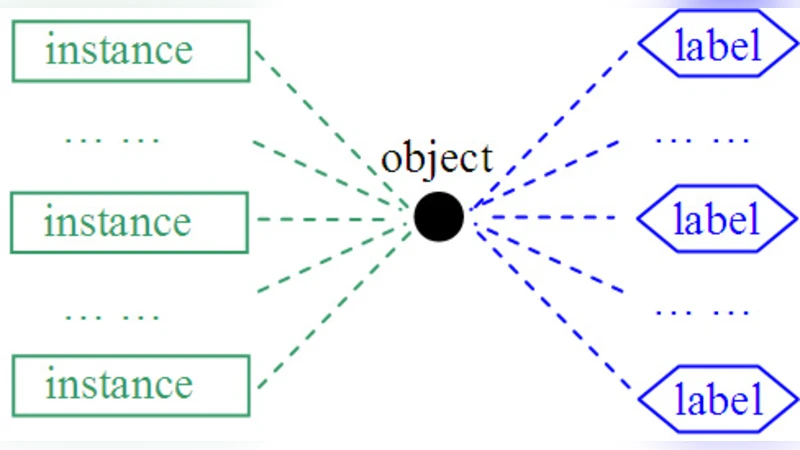
In this paper, we propose the MIML (Multi-Instance Multi-Label learning) framework where an example is described by multiple instances and associated with multiple class labels. Compared to traditional learning frameworks, the MIML framework is more convenient and natural for representing complicated objects which have multiple semantic meanings. To learn from MIML examples, we propose the MimlBoost and MimlSvm algorithms based on a simple degeneration strategy, and experiments show that solving problems involving complicated objects with multiple semantic meanings in the MIML framework can lead to good performance. Considering that the degeneration process may lose information, we propose the D-MimlSvm algorithm which tackles MIML problems directly in a regularization framework. Moreover, we show that even when we do not have access to the real objects and thus cannot capture more information from real objects by using the MIML representation, MIML is still useful. We propose the InsDif and SubCod algorithms. InsDif works by transforming single-instances into the MIML representation for learning, while SubCod works by transforming single-label examples into the MIML representation for learning. Experiments show that in some tasks they are able to achieve better performance than learning the single-instances or single-label examples directly.
💡 Research Summary
The paper introduces a novel learning paradigm called Multi‑Instance Multi‑Label (MIML) learning, in which each training example is represented by a bag of multiple instances and is simultaneously associated with several class labels. This formulation is motivated by the observation that many real‑world objects—such as images containing several objects, documents covering multiple topics, or biological samples exhibiting several functions—cannot be adequately captured by traditional single‑instance single‑label (SI‑SL) or even multi‑instance single‑label (MI‑SL) models. By allowing both dimensions—instances and labels—to be multi‑valued, MIML provides a more natural and expressive representation for complex data.
Problem Definition
Formally, an example is a bag (B = {x_1, x_2, …, x_n}) of (n) feature vectors and a label set (Y \subseteq {1,…,K}) where (K) is the total number of possible labels. The learning task is to predict the correct label set for a previously unseen bag.
Degeneration‑Based Approaches (MimicBoost & MimicSvm)
The authors first propose a simple reduction strategy that converts an MIML problem into a collection of binary classification tasks, one per label. For each label (\ell), a bag is treated as positive if (\ell \in Y) and negative otherwise. Standard boosting (MimicBoost) or support‑vector machines (MimicSvm) are then applied independently to each binary problem. This “degeneration” is attractive because it reuses existing single‑label learners without any algorithmic redesign. However, it discards inter‑instance dependencies within a bag and ignores correlations among labels, potentially leading to information loss.
Direct Regularization Approach (D‑MimlSvm)
To address the shortcomings of degeneration, the paper presents D‑MimlSvm, a regularization‑based formulation that learns directly in the MIML space. The method defines a joint objective that simultaneously (i) maximizes the margin of each bag with respect to each label, (ii) regularizes the classifier in the instance space using a conventional kernel, and (iii) incorporates a label‑kernel that captures pairwise label co‑occurrence. The resulting optimization problem is a structured SVM with a composite loss (e.g., Hamming loss) and can be solved via sub‑gradient descent. Empirical results demonstrate that D‑MimlSvm consistently outperforms the degeneration methods across a range of datasets, achieving higher micro/macro‑F1 scores and lower Hamming loss.
Transforming Conventional Data into MIML (InsDif & SubCod)
The authors further argue that MIML can be beneficial even when the original data are not naturally in a bag‑of‑instances format. Two transformation techniques are introduced:
-
InsDif (Instance Difference) – A single instance (e.g., an image) is artificially split into multiple sub‑instances (e.g., patches or regions). The original label set is retained, thereby converting a SI‑SL problem into an MIML one. This enables the learner to exploit local patterns that may be invisible when the whole image is treated as a monolithic vector.
-
SubCod (Subspace Coding) – A single‑label problem is turned into a multi‑label one by encoding each label as a binary code (sub‑code). Each bit of the code becomes a separate label, allowing the algorithm to capture latent relationships among original labels. Experiments show that both InsDif and SubCod can surpass baseline SI‑SL learners, especially in settings where labels are sparse or objects exhibit multiple semantic aspects.
Experimental Evaluation
The paper evaluates all proposed methods on diverse benchmark collections, including image datasets (e.g., Corel, PASCAL VOC), text corpora (Reuters multi‑label), and protein function prediction. Baselines comprise traditional MI‑SL, SI‑SL, and state‑of‑the‑art multi‑label algorithms such as ML‑kNN and Rank‑SVM. Performance is measured using accuracy, micro/macro‑averaged F1, Hamming loss, and ranking loss. Results indicate:
- D‑MimlSvm achieves the best overall performance, confirming the advantage of learning directly in the MIML space.
- MimicBoost and MimicSvm, while simpler, remain competitive on small‑scale problems and offer faster training times.
- InsDif and SubCod improve over their respective single‑instance or single‑label counterparts by 3–7 % on average, highlighting the practical utility of MIML even when the data are not originally multi‑instance.
Contributions and Limitations
The main contributions are: (1) formalizing the MIML learning setting, (2) providing both reduction‑based and direct learning algorithms, (3) introducing data‑transformation techniques that broaden the applicability of MIML, and (4) delivering extensive empirical evidence of its effectiveness. Limitations include the computational overhead of D‑MimlSvm on very large bags and the sensitivity of kernel and regularization hyper‑parameters. Moreover, the artificial transformations in InsDif and SubCod rely on heuristics; their quality can significantly affect downstream performance. Future work is suggested on scalable kernel designs, automatic bag construction, and deeper integration of label dependency models.
Conclusion
MIML offers a powerful and flexible framework for handling complex objects that naturally possess multiple semantic facets. By jointly modeling instance multiplicity and label multiplicity, it overcomes the representational bottlenecks of earlier paradigms. The suite of algorithms presented—MimicBoost, MimicSvm, D‑MimlSvm, InsDif, and SubCod—demonstrates that MIML can be both practically implementable (through simple reductions) and theoretically superior (through regularization). The paper’s findings open avenues for applying MIML to a broad spectrum of domains, including computer vision, text mining, and bioinformatics, where multi‑faceted data are the norm.
Comments & Academic Discussion
Loading comments...
Leave a Comment