Topological Feature Based Classification
There has been a lot of interest in developing algorithms to extract clusters or communities from networks. This work proposes a method, based on blockmodelling, for leveraging communities and other topological features for use in a predictive classification task. Motivated by the issues faced by the field of community detection and inspired by recent advances in Bayesian topic modelling, the presented model automatically discovers topological features relevant to a given classification task. In this way, rather than attempting to identify some universal best set of clusters for an undefined goal, the aim is to find the best set of clusters for a particular purpose. Using this method, topological features can be validated and assessed within a given context by their predictive performance. The proposed model differs from other relational and semi-supervised learning models as it identifies topological features to explain the classification decision. In a demonstration on a number of real networks the predictive capability of the topological features are shown to rival the performance of content based relational learners. Additionally, the model is shown to outperform graph-based semi-supervised methods on directed and approximately bipartite networks.
💡 Research Summary
The paper addresses the problem of turning network topology into useful predictive features for node classification. Traditional community detection methods rely on optimizing the Newman‑Girvan modularity function or comparing detected partitions against a known “ground truth”. Both approaches suffer from well‑documented issues: modularity has a resolution limit, exhibits many degenerate high‑scoring solutions, and assumes a single, universally correct partition, which is unrealistic for most real‑world networks that contain multiple overlapping or hierarchical groupings (e.g., family, work, hobby). Consequently, evaluating community detection solely by modularity or recovery of a predefined partition does not guarantee that the discovered clusters are relevant for downstream tasks such as classification.
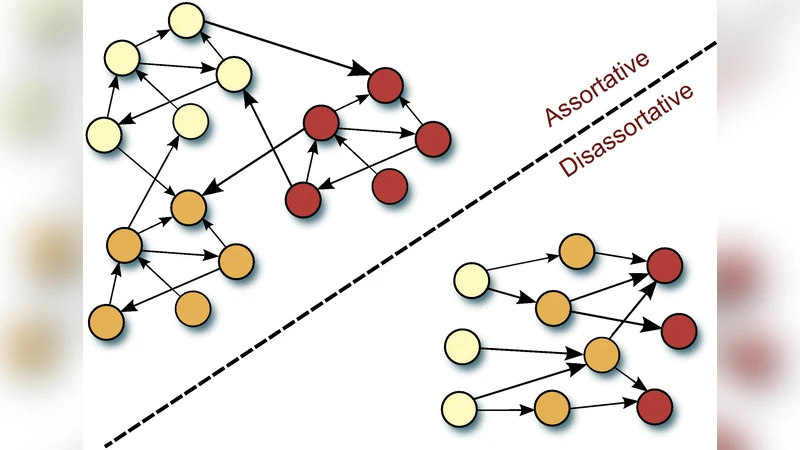
To overcome these limitations, the authors propose a supervised probabilistic block‑modeling framework called the Supervised Blockmodel for Sparse Networks (SBSN). In block modeling, each node is assigned to a latent “position” (also called a network role) that captures a characteristic pattern of connections. Positions can be assortative (nodes tend to link to others in the same position, i.e., a community) or disassortative (nodes preferentially link to different positions). The model defines a K × K interaction matrix π, where π_{k1,k2} is the probability of an edge from a node in position k1 to a node in position k2, and a set of position‑specific node distributions φ_k drawn from Dirichlet priors.
The generative process is as follows: (1) draw the interaction matrix π from a Dirichlet(α) prior; (2) for each position k draw a node distribution φ_k from Dirichlet(β); (3) for each observed interaction i draw a position pair (z_i^s, z_i^r) from a multinomial over π, then draw the sender s_i from φ_{z_i^s} and the receiver r_i from φ_{z_i^r}; (4) for each node v compute the empirical frequency vector (\bar{z}_v) of the positions it participates in, and generate its class label y_v via a softmax function parameterized by η:
p(y_v | η, (\bar{z}_v)) = exp(ηᵀ_y (\bar{z}_v))/∑_c exp(ηᵀ_c (\bar{z}_v)).
Thus the model jointly learns latent positions that explain the observed link structure and are directly tied to the classification target, similar in spirit to supervised Latent Dirichlet Allocation (sLDA) but applied to graph edges rather than words.
Inference is performed using variational Bayesian EM (VBEM). The variational distribution factorizes over π, φ, and the per‑interaction position assignments z_i, with variational parameters ω, ζ, and λ_i respectively. The E‑step updates λ_i (the posterior over position pairs) using expectations of the Dirichlet parameters and the current estimate of η, while the M‑step updates ω, ζ, and η by maximizing the variational free energy. This approach yields tractable updates even for large, sparse graphs, avoiding the intractable exact posterior of the full block model.
Empirical evaluation is carried out on several real‑world networks: citation graphs, blog interaction networks, and word co‑occurrence graphs. The authors compare SBSN against content‑based relational learners that exploit node attributes (e.g., word frequencies) and against graph‑based semi‑supervised methods that assume assortative label propagation. Results show that SBSN, despite using only the link structure and no node content, achieves classification accuracy comparable to or better than the content‑based baselines. Moreover, on directed and approximately bipartite networks (common in fraud detection scenarios), SBSN outperforms traditional semi‑supervised methods, demonstrating its ability to capture disassortative patterns that those methods cannot.
Key contributions of the paper are:
- Introducing a principled way to evaluate community‑like structures by their predictive utility rather than by modularity alone.
- Proposing a supervised block‑model that learns latent positions tailored to a specific classification task, bridging the gap between unsupervised community detection and supervised relational learning.
- Providing a scalable variational inference algorithm that works on large, sparse graphs.
- Demonstrating through extensive experiments that structural information alone can be a powerful predictor, especially in settings where node attributes are unavailable or unreliable.
Overall, the work offers a compelling alternative to traditional community detection and graph‑based semi‑supervised learning, showing that “the best clusters are those that help you predict what you care about.”
Comments & Academic Discussion
Loading comments...
Leave a Comment