Identifying Reference Objects by Hierarchical Clustering in Java Environment
Recently Java programming environment has become so popular. Java programming language is a language that is designed to be portable enough to be executed in wide range of computers ranging from cell phones to supercomputers. Computer programs written in Java are compiled into Java Byte code instructions that are suitable for execution by a Java Virtual Machine implementation. Java virtual Machine is commonly implemented in software by means of an interpreter for the Java Virtual Machine instruction set. As an object oriented language, Java utilizes the concept of objects. Our idea is to identify the candidate objects’ references in a Java environment through hierarchical cluster analysis using reference stack and execution stack.
💡 Research Summary
The paper proposes a method for automatically identifying candidate object references in a Java programming environment by applying hierarchical clustering to operations performed on two distinct stacks: the Reference Stack and the Execution Stack. The authors build on earlier work that used stack and queue operations in procedural languages to create a pattern matrix, compute pairwise similarities, and cluster functions based on those similarities.
In the Java context, the authors define ten fundamental operations—initRef, initExec, isEmptyRef, isEmptyExec, ePush, rPush, ePop, rPop, traRef, and traExec. Each operation is described by six binary attributes (R0–R5) that capture return type, parameter type, and whether the operation accesses fields of the underlying stack structures. These attributes are assembled into a 0‑1 pattern matrix where each row corresponds to an operation and each column to an attribute.
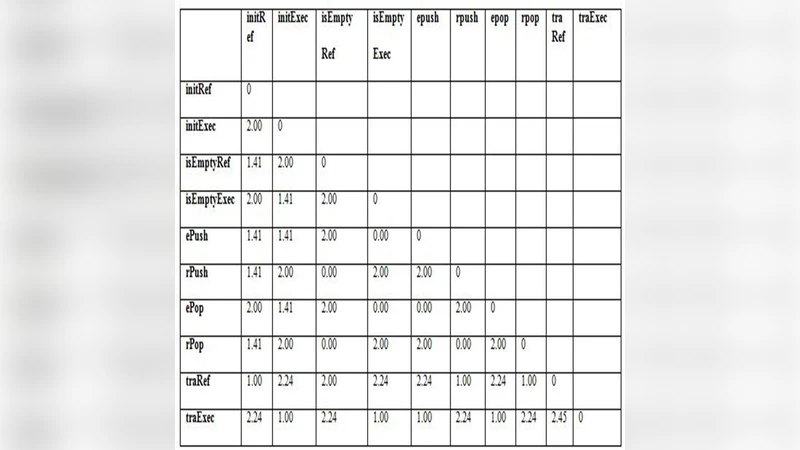
Using the Euclidean distance formula √∑(xᵢⱼ – xₖⱼ)², the authors compute an initial distance matrix for all operation pairs. The smallest distance (0.00) indicates identical attribute vectors, and those pairs are merged first. The clustering proceeds with a single‑linkage (minimum‑distance) rule: the distance between a newly formed cluster and any other cluster is defined as the smallest distance between any member of the new cluster and any member of the other cluster. This process is repeated iteratively, generating successive distance matrices (Tables 9‑13) and ultimately yielding a dendrogram that visualizes the hierarchy.
The final clustering results in two primary clusters: C5, containing all Reference‑Stack‑related operations, and C6, containing all Execution‑Stack‑related operations. Further sub‑clustering splits C5 into C3 (operations that traverse the reference stack, e.g., traRef, initRef) and C1 (operations that check emptiness or push/pop on the reference stack). Similarly, C6 splits into C4 (traversal and initialization of the execution stack) and C2 (emptiness checks and push/pop on the execution stack).
The authors conclude that hierarchical clustering based on stack operation attributes can effectively separate functions dealing with reference management from those handling execution flow, thereby providing a systematic way to identify candidate object references during a migration from procedural to object‑oriented code.
Critical appraisal reveals several limitations. The binary pattern matrix discards quantitative nuances such as call frequency, parameter values, or execution costs, potentially reducing the discriminative power of the similarity measure. Euclidean distance, while straightforward, may not be optimal for binary data; alternatives like Jaccard or Dice coefficients could better capture overlap. The study lacks objective clustering validation metrics (e.g., silhouette score, Dunn index), making it difficult to assess the robustness of the derived clusters. Moreover, the paper does not detail how stack operations are extracted from real Java bytecode or source, limiting reproducibility and practical applicability.
Future work should explore richer feature representations, experiment with multiple distance metrics, and incorporate formal cluster quality assessments. An automated pipeline for extracting stack‑related operations from large Java codebases would also be essential to demonstrate scalability. If these enhancements are realized, the proposed approach could become a valuable tool for reverse‑engineering legacy systems, aiding developers in systematically identifying object boundaries and facilitating smoother transitions to object‑oriented architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment