Information Transfer in Social Media
Recent research has explored the increasingly important role of social media by examining the dynamics of individual and group behavior, characterizing patterns of information diffusion, and identifying influential individuals. In this paper we suggest a measure of causal relationships between nodes based on the information-theoretic notion of transfer entropy, or information transfer. This theoretically grounded measure is based on dynamic information, captures fine-grain notions of influence, and admits a natural, predictive interpretation. Causal networks inferred by transfer entropy can differ significantly from static friendship networks because most friendship links are not useful for predicting future dynamics. We demonstrate through analysis of synthetic and real-world data that transfer entropy reveals meaningful hidden network structures. In addition to altering our notion of who is influential, transfer entropy allows us to differentiate between weak influence over large groups and strong influence over small groups.
💡 Research Summary
The paper introduces a model‑free, information‑theoretic method for uncovering causal relationships and identifying influential users in social media platforms. The core metric is transfer entropy, a non‑symmetric measure that quantifies the reduction in uncertainty about a target process Y when the past of a source process X is known, beyond what Y’s own past provides. Formally, T_{X→Y}=H(Y_t|Y_{t−k}^{t−1})−H(Y_t|Y_{t−k}^{t−1},X_{t−l}^{t−1}), where H denotes conditional entropy. This definition makes transfer entropy a nonlinear generalization of Granger causality and distinguishes it from mutual information, which is symmetric.
To apply the concept to social media, the authors discretize user activity streams (e.g., tweet timestamps) into binary variables B_X(t,Δt) that indicate whether any activity occurred in a given time bin. They discuss practical issues such as the severe bias that arises when estimating entropies from sparse point‑process data. The paper adopts the Panzeri‑Treves bias correction and proposes a variable‑width binning scheme: recent activity is captured with fine bins, while older activity uses coarser bins, reflecting the heavy‑tailed human response time distribution. These choices reduce the data requirements for reliable entropy estimation.
The experimental section is divided into synthetic data and real Twitter data. In the synthetic setting, user activity follows a coupled non‑homogeneous Poisson process: λ_Y(t)=μ+γ∑_{i∈S_X(t)}g(t−t_i), with g(Δt)=min(1,(1 hour/Δt)^3) to model long‑tail response times. By varying observation length T, the influence strength γ/μ, and the sampling fraction f (to mimic partial data collection), the authors evaluate how well transfer entropy recovers the known causal link. Results show that with sufficient observation time (hundreds of days) and moderate to strong influence, transfer entropy accurately identifies the direction and existence of the link. However, when the sampling fraction drops below a few percent, the estimated transfer entropy collapses, making network reconstruction impossible.
For real data, the authors analyze a Twitter “Gardenhose” sample (≈20–30 % of all tweets) focusing on URL propagation. Each URL provides a traceable piece of information that moves through the network. By computing transfer entropy solely from the timing of tweets that contain a given URL, they demonstrate a strong correspondence between high transfer entropy values and actual information flow as observed in the URL cascade. Moreover, they find that users with high transfer entropy tend to exert strong influence over a relatively small set of followers, whereas users with lower transfer entropy influence larger audiences more weakly. This dichotomy—strong influence on small groups versus weak influence on large groups—cannot be captured by simple metrics such as follower count, retweet volume, or PageRank.
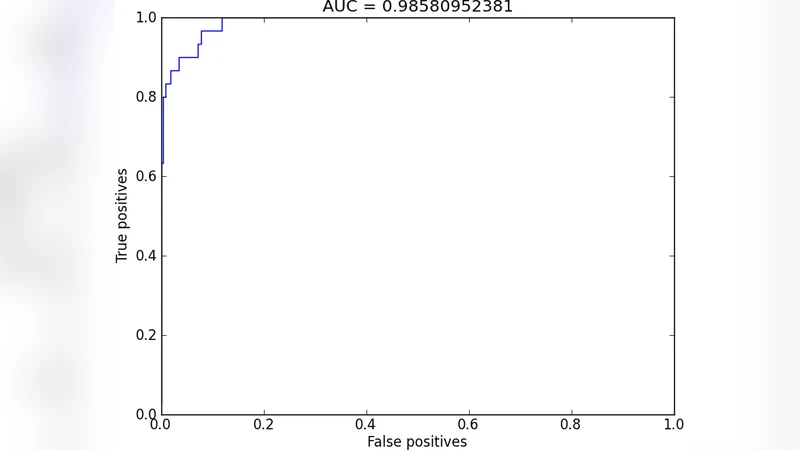
The paper also presents ROC curves, AUC values, and precision‑recall analyses for network reconstruction tasks, showing that transfer‑entropy‑based thresholds outperform traditional centrality‑based methods in both synthetic and real scenarios. The authors discuss limitations, chiefly the dependence on large amounts of high‑quality timestamp data, and suggest extensions such as incorporating content features (text, hashtags), applying bin‑less entropy estimators, and deploying the method in real‑time streaming environments for live influencer detection.
In summary, the study provides a rigorous, theoretically grounded framework for measuring directed information flow in social media. By leveraging transfer entropy, it reveals hidden causal structures that static friendship or follower graphs miss, and it offers a nuanced view of influence that distinguishes between different scales of impact. This work opens avenues for more sophisticated, data‑driven analyses of online social dynamics and for practical tools that can identify true influencers in real time.
Comments & Academic Discussion
Loading comments...
Leave a Comment