Hybrid static/dynamic scheduling for already optimized dense matrix factorization
We present the use of a hybrid static/dynamic scheduling strategy of the task dependency graph for direct methods used in dense numerical linear algebra. This strategy provides a balance of data locality, load balance, and low dequeue overhead. We show that the usage of this scheduling in communication avoiding dense factorization leads to significant performance gains. On a 48 core AMD Opteron NUMA machine, our experiments show that we can achieve up to 64% improvement over a version of CALU that uses fully dynamic scheduling, and up to 30% improvement over the version of CALU that uses fully static scheduling. On a 16-core Intel Xeon machine, our hybrid static/dynamic scheduling approach is up to 8% faster than the version of CALU that uses a fully static scheduling or fully dynamic scheduling. Our algorithm leads to speedups over the corresponding routines for computing LU factorization in well known libraries. On the 48 core AMD NUMA machine, our best implementation is up to 110% faster than MKL, while on the 16 core Intel Xeon machine, it is up to 82% faster than MKL. Our approach also shows significant speedups compared with PLASMA on both of these systems.
💡 Research Summary
The paper introduces a hybrid static‑dynamic scheduling framework for dense matrix factorizations, focusing on the communication‑avoiding LU (CALU) algorithm. Traditional static scheduling maximizes data locality by assigning tasks to cores before execution, but it suffers from idle periods when system‑level variations (NUMA latency spikes, OS interruptions, power‑saving frequency changes) cause some cores to stall. Fully dynamic scheduling eliminates these stalls by pulling ready tasks from a global queue, yet it incurs significant dequeue overhead and destroys cache affinity, especially on many‑core NUMA machines.
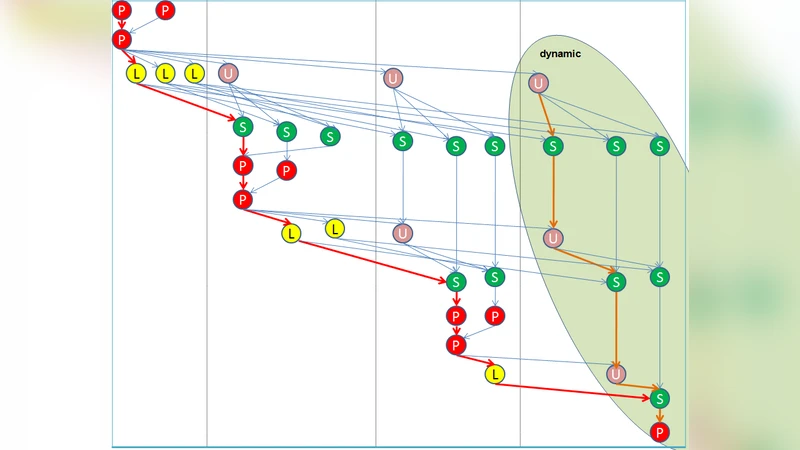
To reconcile these opposing forces, the authors partition the task dependency graph (DAG) of CALU into two regions. The first N_static panels are scheduled statically using a two‑dimensional block‑cyclic distribution; each thread owns a subset of blocks and maintains a private ready‑task queue. Tasks in this region include panel preprocessing (P), L‑factor computation (L), U‑block computation (U), and trailing‑matrix updates (S) that lie on the critical path. By keeping these tasks local, the approach preserves data in the core’s cache and minimizes remote memory accesses.
The remaining panels constitute the dynamic region. When a thread exhausts its private static tasks, it fetches a task from a shared global queue. The dynamic portion is deliberately limited to a tunable percentage (α) of the total work; the optimal α depends on hardware characteristics (NUMA distance, memory bandwidth) and problem size. The authors provide an algorithmic description (Algorithm 1) and a helper routine (Algorithm 2) that selects ready dynamic tasks while respecting dependencies.
Experimental evaluation was performed on two platforms: a 48‑core AMD Opteron NUMA system and a 16‑core Intel Xeon system. Three data layouts were tested – classic column‑major, block‑cyclic, and a two‑level block layout. Results show that the hybrid scheme outperforms pure static scheduling by up to 30 % on the AMD machine and pure dynamic scheduling by up to 64 % on the same hardware. On the Xeon, the hybrid approach yields about an 8 % speed‑up over either pure strategy. Compared with Intel’s Math Kernel Library (MKL) LU routine, the hybrid implementation is up to 110 % faster on AMD and up to 82 % faster on Xeon. Against PLASMA, it achieves additional gains of roughly 30‑45 %.
A theoretical model is presented to explain the observed behavior. The total execution time is expressed as T_total ≈ L_c + α·T_q + (1‑α)·O_static, where L_c is the length of the critical path, T_q is the average queue‑waiting time for dynamic tasks, and O_static is the static‑scheduling overhead (primarily initial data placement). The model predicts a convex relationship between α and T_total, confirming that an intermediate α (typically 20‑30 %) minimizes overall runtime.
The paper argues that the hybrid approach is not limited to CALU; the same principle can be applied to other block‑based dense factorizations such as QR, rank‑revealing QR, Cholesky, and LDLᵀ. By preserving locality for the critical path while allowing limited dynamic load‑balancing, the method offers a practical path toward performance consistency on current many‑core systems and future exascale architectures, where variability and NUMA effects will be even more pronounced.
Comments & Academic Discussion
Loading comments...
Leave a Comment