Influence, originality and similarity in directed acyclic graphs
We introduce a framework for network analysis based on random walks on directed acyclic graphs where the probability of passing through a given node is the key ingredient. We illustrate its use in evaluating the mutual influence of nodes and discovering seminal papers in a citation network. We further introduce a new similarity metric and test it in a simple personalized recommendation process. This metric’s performance is comparable to that of classical similarity metrics, thus further supporting the validity of our framework.
💡 Research Summary
The paper introduces a novel framework for analyzing directed acyclic graphs (DAGs) by exploiting random walks whose key observable is the “passage probability” – the probability that a walk starting at a given node passes through another node. Because a DAG has no directed cycles, any random walk inevitably terminates at a sink (a node with zero out‑degree). This property makes the passage probability a meaningful, non‑trivial quantity, unlike in general networks where stationary occupation probabilities often collapse to uniform values.
Formally, for each source node x an N‑dimensional vector Gₓ is defined; its i‑th component Gₓ(i) equals the probability that a walk starting at x visits node i. The transition matrix W has entries W_{ij}=1/k_out(i) if i cites j and 0 otherwise. The vectors satisfy the fixed‑point equation Gₓ = W Gₓ with the boundary condition Gₓ(x)=1. Collecting all Gₓ as columns yields the matrix G, where G_{yx} is precisely the passage probability from x to y. This matrix can be expressed as an infinite sum G = Σ_{n=0}^∞ Wⁿ, i.e., the sum over all path lengths.
Using G, the authors define the aggregate impact of a node x as Iₓ = Σ_y G_{yx}. Since Iₓ naturally grows with the size of the node’s progeny set Pₓ (the set of nodes reachable from x), they also consider the ratio Iₓ/Pₓ. Nodes with unusually high Iₓ/Pₓ are interpreted as seminal works that have shaped large downstream research areas despite possibly modest citation counts.
A self‑consistent relation Iₓ = 1 + Σ_y W_{yx} I_y is derived, which mirrors the classic PageRank equation. By introducing a damping factor α (the probability of following an existing edge) and a jump probability 1‑α, the authors obtain a generalized impact Iₓ^α satisfying Iₓ^α = 1‑α + α Σ_y W_{yx} I_y^α. In the limit α → 1, Iₓ^α reduces to the undamped impact Iₓ, while for α < 1 the formulation coincides with standard PageRank. Thus the proposed metric can be seen as a PageRank without damping, which removes the time‑bias inherent in citation data.
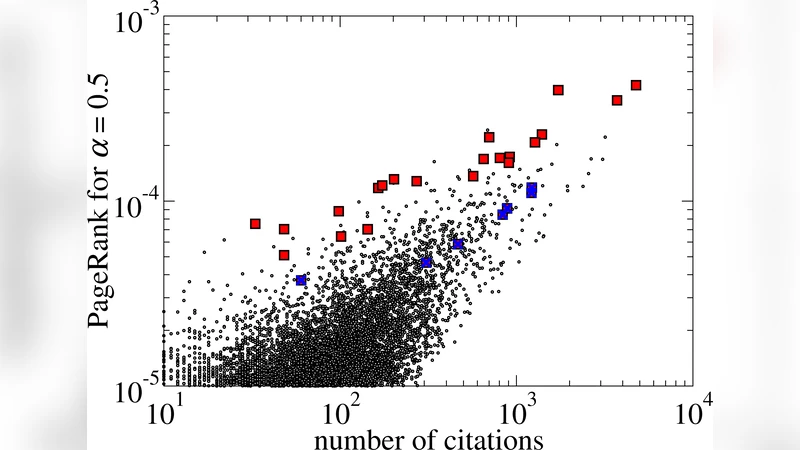
The framework is evaluated on the American Physical Society (APS) citation dataset (≈450 k papers, ≈4.7 M citations, 1940‑2009). After pruning same‑year citations to enforce acyclicity, the authors plot Iₓ versus progeny size Pₓ. Most papers lie on a roughly linear trend, but a handful of outliers exhibit dramatically higher Iₓ/Pₓ. These outliers correspond to historically important papers (e.g., Bardeen et al. on superconductivity, Kohn‑Sham density functional theory) that have received major awards (Nobel, Lorentz, Dirac medals). Notably, many of these seminal works have citation counts comparable to or lower than average, showing that the undamped impact captures originality and downstream influence better than raw citation counts or standard PageRank (α=0.5), which often rank them modestly.
Beyond influence, the authors propose a similarity measure based on the G matrix: the similarity between two papers x and y can be taken as the inner product or cosine similarity of their passage‑probability vectors Gₓ and G_y. They embed this similarity into a simple personalized recommendation algorithm and find performance comparable to classical similarity metrics (cosine, Jaccard, Pearson) on a basic test. The advantage lies in the natural incorporation of temporal ordering inherent to DAGs.
In summary, the paper makes four main contributions: (1) a passage‑probability based random‑walk framework for DAGs, (2) a clear analytical link to PageRank and a demonstration that undamped impact removes time bias, (3) empirical validation on a large citation network showing effective identification of seminal papers, and (4) a new similarity metric that performs on par with established methods while respecting DAG structure. The authors suggest extensions to other DAG‑type systems such as patent citation networks, legal case precedents, and genealogical trees, and propose incorporating edge weights or dynamic updates as promising future directions.
Comments & Academic Discussion
Loading comments...
Leave a Comment