Implementing a Web Browser with Phishing Detection Techniques
Phishing is the combination of social engineering and technical exploits designed to convince a victim to provide personal information, usually for the monetary gain of the attacker. Phishing has become the most popular practice among the criminals of the Web. Phishing attacks are becoming more frequent and sophisticated. The impact of phishing is drastic and significant since it can involve the risk of identity theft and financial losses. Phishing scams have become a problem for online banking and e-commerce users. In this paper we propose a novel approach to detect phishing attacks. We implemented a prototype web browser which can be used as an agent and processes each arriving email for phishing attacks. Using email data collected over a period time we demonstrate data that our approach is able to detect more phishing attacks than existing schemes.
💡 Research Summary
**
The paper addresses the growing threat of phishing, particularly through email, and proposes a novel detection approach that focuses on link‑based features rather than the more common text‑based classification methods. The authors identify three key characteristics of hyperlinks within an email: (1) the total number of visible links, (2) the number of invisible links (determined by a color‑contrast rule derived from the W3C standard, where a contrast value below 500 indicates that the link is effectively hidden from the user), and (3) a binary flag indicating whether the displayed URL matches the actual target URL (unmatching_urls).
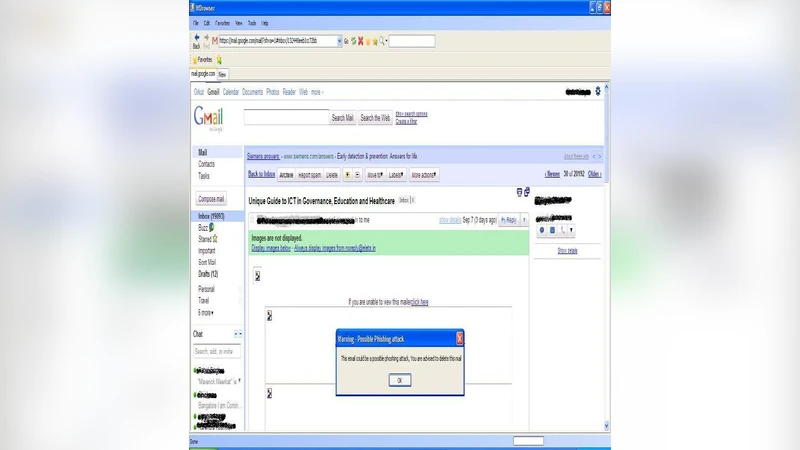
The detection algorithm works as follows: when a user opens an email using the custom web browser, a backend engine parses the HTML content, extracts all <a> elements, and computes the three features. If both “visible_links” and “unmatching_urls” are zero, the email is considered safe and the browser’s status bar displays a “Safe” indicator. If either “invisible_links” or “unmatching_urls” is greater than zero, the system flags the message as a potential phishing attack, presents a pop‑up warning, and advises the user to delete the email.
Implementation details are provided for a prototype built in C#.Net that wraps the Internet Explorer rendering engine. This design choice allows the prototype to function like a regular email viewer while silently performing the phishing check in the background. The user experience remains largely unchanged for legitimate messages; only suspicious messages trigger a visual alert and a recommendation to discard them.
The authors claim that their prototype outperforms existing schemes such as the AntiPhish browser extension, which primarily relies on URL/IP comparison and visual similarity metrics. By focusing on structural link anomalies—especially hidden links and mismatched URLs—the proposed system can catch phishing attempts that evade traditional text‑based filters or visual similarity checks. However, the paper does not provide detailed quantitative metrics (e.g., precision, recall, F1‑score) or a rigorous statistical comparison with baseline methods, making it difficult to assess the true magnitude of the improvement.
A critical analysis of the work highlights several strengths and weaknesses. Strengths include: (i) the innovative use of link visibility and URL mismatch as detection cues, (ii) a lightweight implementation that can be integrated into existing browsers without major user disruption, and (iii) an intuitive user‑facing warning mechanism that directly informs non‑technical users of potential threats. Weaknesses involve: (i) the reliance on a single, manually chosen contrast threshold (500) which may not generalize across different email clients, display settings, or accessibility configurations, (ii) the absence of a comprehensive evaluation dataset and performance statistics, and (iii) limited resilience against sophisticated phishing tactics that deliberately align visible and hidden URLs or use advanced obfuscation techniques (e.g., JavaScript‑generated links).
The paper concludes by suggesting future work that could enhance the system’s robustness: integrating the link‑based features into a machine‑learning classifier to combine them with textual cues, extending the detection to dynamic content analysis (e.g., JavaScript execution), and testing the prototype across a broader range of browsers and operating systems. Overall, the study contributes a practical, user‑centric approach to phishing detection, but further empirical validation and refinement are needed before the solution can be considered ready for large‑scale deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment