Eclectic Extraction of Propositional Rules from Neural Networks
Artificial Neural Network is among the most popular algorithm for supervised learning. However, Neural Networks have a well-known drawback of being a “Black Box” learner that is not comprehensible to the Users. This lack of transparency makes it unsuitable for many high risk tasks such as medical diagnosis that requires a rational justification for making a decision. Rule Extraction methods attempt to curb this limitation by extracting comprehensible rules from a trained Network. Many such extraction algorithms have been developed over the years with their respective strengths and weaknesses. They have been broadly categorized into three types based on their approach to use internal model of the Network. Eclectic Methods are hybrid algorithms that combine the other approaches to attain more performance. In this paper, we present an Eclectic method called HERETIC. Our algorithm uses Inductive Decision Tree learning combined with information of the neural network structure for extracting logical rules. Experiments and theoretical analysis show HERETIC to be better in terms of speed and performance.
💡 Research Summary
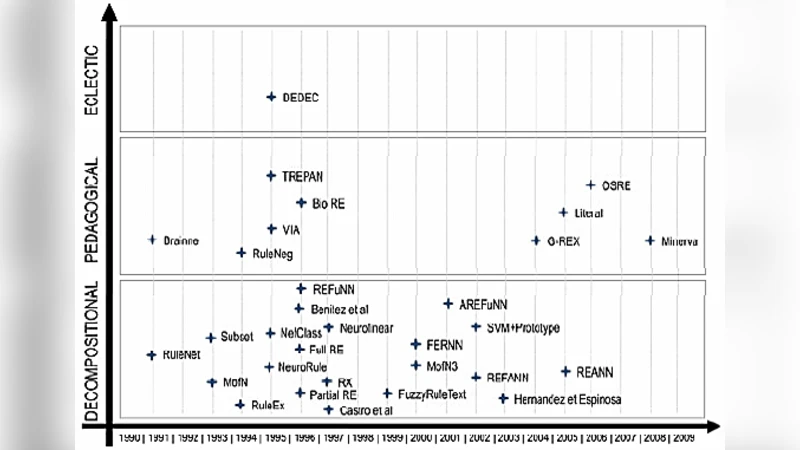
The paper addresses the well‑known “black‑box” problem of artificial neural networks (ANNs) by proposing a novel rule‑extraction method called HERETIC (Hierarchical and Eclectic Rule Extraction via Tree Induction and Combination). Rule extraction is categorized into three families: decompositional (direct weight analysis), pedagogical (treating the network as an oracle and learning symbolic models from its input‑output behavior), and eclectic (a hybrid of the two). While decompositional methods exploit internal structure, they suffer from exponential search spaces; pedagogical methods are architecture‑agnostic but often require extensive re‑learning and yield lower fidelity. Eclectic approaches aim to combine the strengths of both, yet prior work in this area is limited.
HERETIC’s core idea is to decompose a trained feed‑forward multilayer perceptron (MLP) into its individual neurons, then approximate each neuron’s Boolean mapping with a decision tree generated by the C4.5 algorithm. The workflow is as follows: (1) train the MLP using standard back‑propagation; (2) feed the original training instances through the trained network and record each neuron’s output; (3) discretize neuron outputs to binary values (0/1) by using a steep sigmoid (effectively a step function) to reduce quantization error; (4) for each neuron, construct a dedicated training set consisting of its inputs (which are either original features or outputs of neurons in the preceding layer) and the binary target; (5) run C4.5 independently on each set, producing a univariate decision tree per neuron; (6) translate every root‑to‑leaf path into a conjunctive clause, then combine clauses across layers to form a final set of disjunctive normal form (DNF) rules that emulate the original network.
Key advantages highlighted include: (i) exploitation of network topology, because each tree is built on the actual connectivity of the neuron; (ii) use of a well‑studied symbolic learner (decision trees) that generalizes better than raw weight inspection; (iii) natural parallelism, as trees for different neurons can be learned concurrently; (iv) broad applicability to networks with arbitrary depth, partial connectivity, and even limited recurrent structures, thanks to the universal approximation property of decision trees.
The authors acknowledge several limitations. The binary discretization of neuron outputs inevitably discards information; although a steep sigmoid mitigates this, the trade‑off is not empirically quantified. Tree depth may grow with network depth, potentially yielding very large DNF expressions that are hard for humans to interpret—a classic “rule explosion” problem. Computationally, while each C4.5 run is O(N log N), the total cost scales with the number of neurons, which can be substantial for modern deep networks. The paper’s experimental section is under‑described: it mentions superior speed and accuracy but provides no concrete datasets, baseline algorithms (e.g., TREPAN, DEDEC, MofN), performance metrics, or statistical significance tests, making reproducibility and objective assessment difficult.
In terms of scholarly contribution, HERETIC offers a concrete implementation of the eclectic paradigm, demonstrating that a hybrid of structural decomposition and symbolic learning can produce compact, high‑fidelity rule sets. It reinforces the notion that decision‑tree approximations are powerful surrogates for neural computations, suggesting a pathway for future explainable‑AI systems that need both the predictive strength of deep learning and the interpretability of symbolic models. Future work should explore multi‑valued (rather than binary) discretization, pruning strategies to control rule size, scalability to deep convolutional or transformer architectures, and thorough empirical comparisons across diverse benchmark domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment