Low-rank data modeling via the Minimum Description Length principle
Robust low-rank matrix estimation is a topic of increasing interest, with promising applications in a variety of fields, from computer vision to data mining and recommender systems. Recent theoretical results establish the ability of such data models to recover the true underlying low-rank matrix when a large portion of the measured matrix is either missing or arbitrarily corrupted. However, if low rank is not a hypothesis about the true nature of the data, but a device for extracting regularity from it, no current guidelines exist for choosing the rank of the estimated matrix. In this work we address this problem by means of the Minimum Description Length (MDL) principle – a well established information-theoretic approach to statistical inference – as a guideline for selecting a model for the data at hand. We demonstrate the practical usefulness of our formal approach with results for complex background extraction in video sequences.
💡 Research Summary
The paper tackles a fundamental yet often overlooked problem in low‑rank matrix modeling: how to choose the rank (or, more generally, the complexity) of the approximation when the low‑rank assumption is used as a regularisation device rather than a true description of the underlying signal. The authors adopt the Minimum Description Length (MDL) principle, which equates the ability of a model to capture regularities with its ability to compress the data. By treating the decomposition Y = X + E (where X is low‑rank and E is sparse) as a coding problem, they derive explicit codelength formulas for every component of the model.
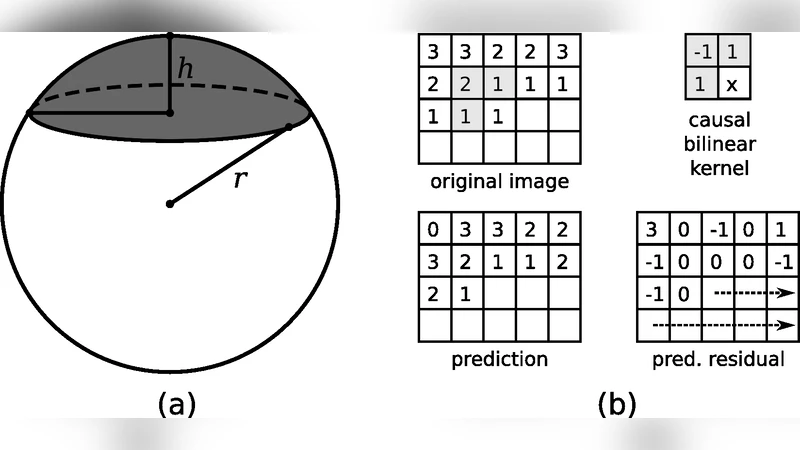
First, the low‑rank part X is represented by its reduced singular value decomposition X = U Σ Vᵀ. The diagonal of Σ is quantised to 10⁻¹⁶ precision and encoded using a universal integer code L(j)=log j+log log j+…, which yields a compact description that grows only logarithmically with the magnitude of the singular values. The orthonormal matrices U∈ℝ^{m×k} and V∈ℝ^{n×k} are assumed to be uniformly distributed on the respective unit spheres. Their columns are encoded by exploiting the geometry of spherical caps: the first component of each column is coded using the cumulative distribution function of the cap area, and subsequent components are recursively encoded on lower‑dimensional spheres orthogonal to the already‑encoded columns. Quantisation steps for U and V are chosen adaptively (starting from 1/√m and 1/√n) and refined until the total codelength stops decreasing.
When additional prior knowledge is available, the authors enrich the coding scheme. In video surveillance data, the columns of U correspond to “eigen‑frames” that are spatially smooth. Each column is reshaped into an image and a causal bilinear predictor is applied; the prediction residuals are modelled as Laplacian random variables with unknown scale. A two‑part universal code encodes both the residuals and the estimated scale (≈½ log m bits for the scale). An analogous first‑order predictive coding is applied to the rows of V, which capture temporal evolution; again Laplacian residuals and a ½ log n‑bit scale term are used.
The sparse error matrix E is handled by first encoding the locations of non‑zero entries with an Enumerative Code for Bernoulli sequences, then encoding the non‑zero values themselves with a Laplacian model whose scale is estimated per row (reflecting that some pixels are more often occluded than others).
To search over possible ranks, the authors solve the Robust PCA (RPCA) convex program
min_W ‖Y‑W‖₁ + λ‖W‖_*
for a decreasing sequence of λ values. They employ an Augmented Lagrangian Method (ALM) with warm‑starts, so that each successive λ uses the previous solution as initialization, making the whole path computation efficient. For each λ they obtain a pair (X_t, E_t) and compute its total description length L(Y|X_t). The model with the smallest codelength is selected, providing a parameter‑free rank estimate.
Experimental validation is performed on real surveillance video sequences where background frames are stacked as columns of Y. The background, being largely static, is low‑rank, while moving people appear as sparse outliers. Traditional methods would require manual tuning of the rank; the MDL‑based approach automatically selects k≈10 for the “Lobby” sequence, correctly separating background and foreground, and even reveals subtle events such as lights being switched off (visible as a square‑pulse in the right singular vectors). The results demonstrate that the MDL criterion not only yields a principled rank choice but also offers a transparent way to incorporate domain‑specific priors (smoothness, temporal correlation) into the model.
In summary, the contribution of the paper is threefold: (1) formulation of low‑rank model selection as an MDL coding problem; (2) concrete, analytically derived codelengths for singular values, orthonormal bases, and sparse errors, with extensions for predictive coding when additional structure is known; (3) an efficient algorithmic pipeline that traverses the RPCA regularisation path and selects the optimal rank without cross‑validation. This bridges information‑theoretic model selection with robust low‑rank matrix recovery, opening the door to fully automatic, statistically sound low‑rank modeling in computer vision, recommender systems, and beyond.
Comments & Academic Discussion
Loading comments...
Leave a Comment