Controlling centrality in complex networks
Spectral centrality measures allow to identify influential individuals in social groups, to rank Web pages by their popularity, and even to determine the impact of scientific researches. The centrality score of a node within a network crucially depends on the entire pattern of connections, so that the usual approach is to compute the node centralities once the network structure is assigned. We face here with the inverse problem, that is, we study how to modify the centrality scores of the nodes by acting on the structure of a given network. We prove that there exist particular subsets of nodes, called controlling sets, which can assign any prescribed set of centrality values to all the nodes of a graph, by cooperatively tuning the weights of their out-going links. We show that many large networks from the real world have surprisingly small controlling sets, containing even less than 5-10% of the nodes. These results suggest that rankings obtained from spectral centrality measures have to be considered with extreme care, since they can be easily controlled and even manipulated by a small group of nodes acting in a coordinated way.
💡 Research Summary
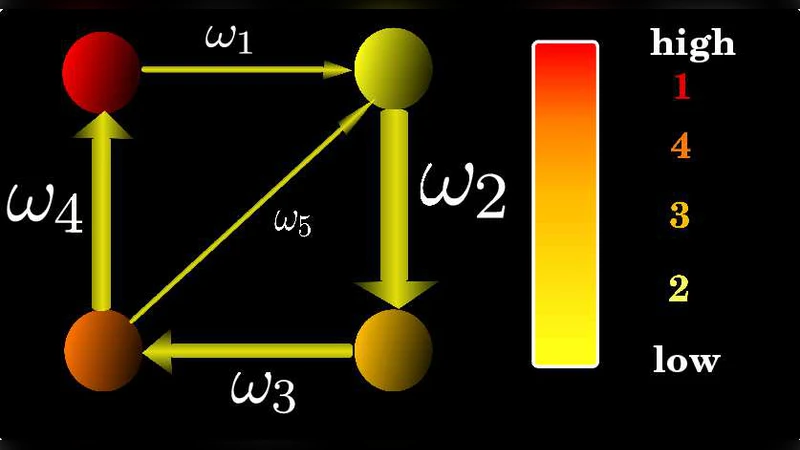
The paper tackles the inverse problem of spectral centrality: instead of computing node importance from a given network, it asks how to reshape a network so that any prescribed set of centrality scores can be realized. Focusing on eigenvector centrality, the authors first prove that for any strongly‑connected directed graph G and any positive vector c ≠ c₀ (the original eigenvector centrality), one can assign positive weights to all existing edges, preserving the topology, to obtain a weighted graph G₍ω₎ whose eigenvector centrality exactly equals c. The proof rests on the fact that the eigenvalue equation Aᵀ₍ω₎ c = ρ c provides N equations with K unknown edge weights; when K > N there are K − N free parameters, guaranteeing a solution for any target c. An illustrative example with four nodes and five edges shows how to make all nodes equally central or to completely reverse the original ranking by solving for the appropriate weight vector ω.
Recognizing that adjusting every edge is impractical in large systems, the authors introduce the notion of a “controlling set” C* ⊆ V. Nodes in C* are allowed to modify only their outgoing links, yet by doing so they can steer the eigenvector centrality of the entire network to any desired vector c. Mathematically, one must select a subset of edges E′ ⊆ E such that for every node i there exists at least one edge in E′ pointing to i; the tails of all edges in E′ form the controlling set. This is essentially a directed dominating set problem, but with the additional requirement that the dominating edges must be present in the original graph.
To assess how large a controlling set needs to be in real‑world networks, the authors devise two greedy heuristics. The first repeatedly picks the node with the largest number of uncovered outgoing edges, adds it to the controlling set, and marks all its outgoing edges as covered. The second works symmetrically on incoming edges. For each of 35 empirical networks—spanning WWW hyperlink graphs, scientific co‑authorship, citation, power‑grid, road, electronic‑circuit, word‑association, and various socio‑economic graphs—the smaller of the two greedy results is reported as an approximation of the minimum controlling set size C(G).
The empirical findings are striking. In most cases the controlling set comprises only 5–20 % of the nodes, and in several large communication networks it is dramatically smaller. For example, the Wikipedia talk‑page network (≈2.4 million nodes) can be controlled by just 2 % of its participants; the Stanford WWW graph (≈280 k nodes) needs only about 8 % of nodes; the Jazz musician collaboration network (198 nodes) requires merely 16 individuals (≈8 %). Conversely, spatially constrained networks such as power grids, road maps, and electronic circuits need larger controlling sets (≈30 % or more), reflecting the limited flexibility of their topology. When the same graphs are degree‑preserving randomized, the controlling set sizes increase substantially, indicating that the observed small controlling sets are not a trivial consequence of degree distribution but a structural feature of real networks.
The authors argue that the same controllability holds for other spectral centralities, such as α‑centrality and Katz centrality, and, with some restrictions, for PageRank. Consequently, rankings derived from these measures are vulnerable to manipulation by a small, coordinated group of nodes that can adjust the weights of their outgoing links. In practical terms, a website owner can alter hyperlink attributes to boost PageRank, a researcher can re‑weight co‑authorship ties to inflate citation metrics, and an autonomous system operator can change peering agreements to affect traffic flow centrality.
In conclusion, the paper provides a rigorous theoretical foundation and extensive empirical evidence that a modest subset of nodes can fully dictate the eigenvector centrality landscape of complex networks. This raises serious concerns for any application that relies on spectral centrality for influence assessment, recommendation, or resource allocation. The work suggests that safeguards—such as limiting the ability to arbitrarily weight edges, incorporating robustness checks, or using centrality measures less susceptible to weight manipulation—are essential. Future research directions include cost‑aware control (minimizing the total weight change), dynamic networks where the controlling set may evolve over time, and extending the analysis to non‑spectral centralities like betweenness or clustering coefficients.
Comments & Academic Discussion
Loading comments...
Leave a Comment