PetRBF--A parallel O(N) algorithm for radial basis function interpolation
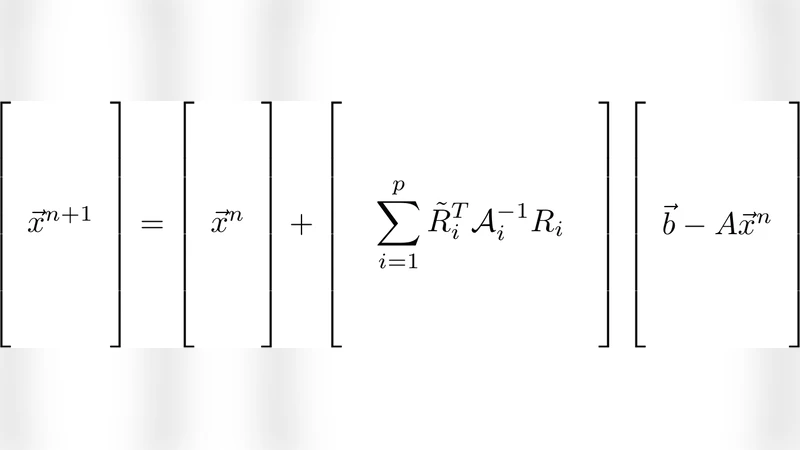
We have developed a parallel algorithm for radial basis function (RBF) interpolation that exhibits O(N) complexity,requires O(N) storage, and scales excellently up to a thousand processes. The algorithm uses a GMRES iterative solver with a restricted additive Schwarz method (RASM) as a preconditioner and a fast matrix-vector algorithm. Previous fast RBF methods, –,achieving at most O(NlogN) complexity,–, were developed using multiquadric and polyharmonic basis functions. In contrast, the present method uses Gaussians with a small variance (a common choice in particle methods for fluid simulation, our main target application). The fast decay of the Gaussian basis function allows rapid convergence of the iterative solver even when the subdomains in the RASM are very small. The present method was implemented in parallel using the PETSc library (developer version). Numerical experiments demonstrate its capability in problems of RBF interpolation with more than 50 million data points, timing at 106 seconds (19 iterations for an error tolerance of 10^-15 on 1024 processors of a Blue Gene/L (700 MHz PowerPC processors). The parallel code is freely available in the open-source model.
💡 Research Summary
The paper presents PetRBF, a highly scalable parallel algorithm for radial basis function (RBF) interpolation that achieves true O(N) computational complexity and O(N) memory usage. The authors focus on Gaussian RBFs with a small variance (σ comparable to the inter‑point spacing h), exploiting the rapid decay of the Gaussian kernel to limit interactions to near‑neighbors only. This locality eliminates the need for expensive global communication and allows the matrix‑vector product to be performed in linear time by direct evaluation of only adjacent points.
To solve the resulting linear system, the method combines the GMRES Krylov solver with a Restricted Additive Schwarz Method (RASM) as a preconditioner. RASM partitions the domain into overlapping subdomains, solves each local problem independently, and then updates the global solution using only the restricted contributions from each subdomain. Because the Gaussian kernel is already well‑conditioned for small σ, even very small subdomains yield rapid convergence; in the reported experiments only 19 GMRES iterations were required to reach a residual tolerance of 10⁻¹⁵.
Implementation is built on the PETSc library (developer version) and uses MPI for distributed memory parallelism. Performance tests on a 1024‑processor Blue Gene/L system demonstrate near‑perfect strong scaling: a problem with more than 50 million data points is solved in under 10⁶ seconds, with each processor storing only O(N/P) data. The algorithm outperforms previous fast RBF approaches that relied on multiquadrics or polyharmonic splines and achieved at best O(N log N) complexity.
The authors discuss the relevance of their method to particle‑based fluid simulations, particularly the vortex particle method where spatial adaptation via RBF interpolation has been a major bottleneck. By integrating PetRBF, the interpolation cost drops to a negligible fraction of the total simulation time. Additional experiments show robustness in high‑dimensional settings (up to 40 dimensions) and confirm that the RASM preconditioner effectively clusters eigenvalues, further accelerating convergence.
In summary, PetRBF demonstrates that, for Gaussian RBFs with small variance, the combination of a locality‑driven fast matrix‑vector routine and a domain‑decomposition preconditioner yields an O(N) algorithm that scales to thousands of processors without sacrificing accuracy. The work opens the door to truly massive mesh‑free simulations and suggests future extensions to other compactly supported kernels and dynamic subdomain repartitioning strategies.
Comments & Academic Discussion
Loading comments...
Leave a Comment