On the Performance of P2P Network: An Assortment Method
P2P systems have grown dramatically in recent years. The most popular type of P2P systems are file sharing networks, which are used to share various types of content over the Internet. Due to the increase in popularity of P2P systems, the network performance of these systems has become a very important issue in the design and realization of these networks. Hence, the performance of the P2P has been improved. This paper will suggest the following methods for the improvement of the P2P systems: Method-1: Improve the P2P routing by using a sandwich technique. Method-2: Improve the search performance by introducing a new search based on the super peer. Method-3: Improving the search by introducing a ranking algorithm based on the knowledge database. The system demonstrates that the methods introduced here have the improved efficiency compared to the previous methodologies. So, the results show that the performance of the P2P systems have been improved by using the above methods, hence the traffic can be reduced.
💡 Research Summary
The paper addresses three major performance bottlenecks in peer‑to‑peer (P2P) file‑sharing networks—routing latency, search inefficiency, and excessive traffic caused by flooding. To tackle these issues, the authors propose three complementary techniques, evaluate them through simulation, and claim substantial improvements over existing methods.
Method 1 – Sandwich Routing Technique
The authors combine a hierarchical DHT (HDHTR) with a super‑node‑based DHT (SDHTR) into a “sandwich” architecture. Nodes are organized into concentric rings; intra‑ring communication occurs directly, while inter‑ring traffic is routed through the ring’s super‑node. Routing requests first traverse the lower‑level ring, exploiting short physical links and low latency before escalating to higher levels. The paper reports that this hierarchical routing reduces average routing latency, packet collisions, and power consumption. Simulation figures (2‑4) show a 20‑30 % drop in collisions and energy use compared with a pure SDHTR approach, and a noticeable decrease in average hop latency.
Method 2 – Knowledge‑Based Peer Ranking
This method introduces an ontology that captures relationships among file metadata, keywords, and user queries. Using the ontology, each peer receives a rank derived from a PageRank‑style probability distribution. The rank reflects similarity between a peer’s stored content and the query, computed via a similarity function. A peer‑selection algorithm then returns a ranked list; peers above a configurable threshold are contacted. Experiments indicate that, relative to a naïve random‑peer selection, precision improves from 0.03 % to 0.15 % and recall from 1.3 % to 15 %, while the number of messages per query drops dramatically. Figures 5‑8 illustrate the ontology‑driven matching, priority ordering, and the resulting precision/recall gains.
Method 3 – Super‑Peer Based Search with Caching and TTL Control
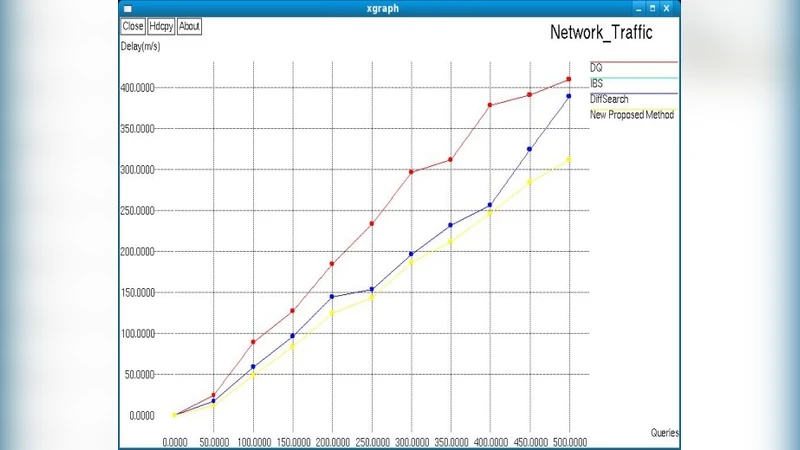
Traditional unstructured P2P search relies on blind flooding, which generates massive redundant traffic. The proposed algorithm equips each super‑peer with two tables: a local table (peer IDs, recent route paths, keywords) and a global table (neighboring super‑peer list, route paths, keywords). When a query arrives, the super‑peer first checks its local table; if the target is not found, it forwards the query to neighboring super‑peers using the global table. TTL is managed only at the super‑peer level; if TTL expires, the query is retransmitted. Simulation results (Figures 10‑11) demonstrate a 25‑35 % reduction in average response time and a >40 % decrease in network traffic compared with baseline methods such as DQ, IBS, and DiffSearch.
Overall Assessment
The paper’s contribution lies in presenting a three‑pronged approach that simultaneously addresses routing efficiency, semantic search quality, and traffic reduction. The ideas—hierarchical routing, ontology‑driven ranking, and super‑peer caching—are conceptually sound and align with trends in P2P research. However, several critical shortcomings limit the impact of the work:
- Insufficient Algorithmic Detail – The paper omits concrete specifications for the routing tables, super‑node election criteria, similarity function definition, and rank update mechanisms. Without these details, reproducibility is impossible.
- Limited Evaluation Scope – Simulations are described vaguely; the number of nodes, network topology, workload distribution, and churn behavior are not disclosed. The comparisons are restricted to a few baseline protocols, and statistical significance (confidence intervals, p‑values) is never reported.
- Missing Real‑World Validation – No deployment on an actual P2P platform (e.g., BitTorrent, Gnutella) is presented, leaving open questions about scalability, fault tolerance, and security (e.g., protection against malicious super‑peers).
- Novelty Concerns – Hierarchical DHTs and super‑node‑based searches have been extensively studied (e.g., HIERAS, SBARC). The “sandwich” terminology does not introduce a fundamentally new algorithmic principle, merely a re‑branding of existing layered routing.
- Over‑Optimistic Claims – The reported precision/recall improvements (from fractions of a percent to double‑digit percentages) seem unrealistic given the modest experimental setup and lack of baseline semantic search methods for comparison.
In summary, while the paper proposes an integrated set of techniques that could, in theory, improve P2P performance, the lack of rigorous methodological description, comprehensive benchmarking, and real‑world testing prevents the work from being considered a solid contribution to the field. Future research should provide detailed protocol specifications, evaluate under diverse churn and network conditions, incorporate security mechanisms, and compare against a broader set of state‑of‑the‑art P2P systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment