Active Learning for Node Classification in Assortative and Disassortative Networks
In many real-world networks, nodes have class labels, attributes, or variables that affect the network’s topology. If the topology of the network is known but the labels of the nodes are hidden, we would like to select a small subset of nodes such that, if we knew their labels, we could accurately predict the labels of all the other nodes. We develop an active learning algorithm for this problem which uses information-theoretic techniques to choose which nodes to explore. We test our algorithm on networks from three different domains: a social network, a network of English words that appear adjacently in a novel, and a marine food web. Our algorithm makes no initial assumptions about how the groups connect, and performs well even when faced with quite general types of network structure. In particular, we do not assume that nodes of the same class are more likely to be connected to each other—only that they connect to the rest of the network in similar ways.
💡 Research Summary
The paper tackles the problem of inferring the class labels of all nodes in a network when only the network topology is known and the labels are hidden, while the cost of obtaining a label for any individual node is limited. The authors propose an active‑learning framework that selects, one by one, the most informative nodes to query, thereby minimizing the number of queries needed to achieve high‑accuracy classification of the remaining nodes.
The underlying generative model is the stochastic block model (SBM). In this model each node v carries a latent class t(v)∈{1,…,k} and an edge from u to v exists independently with probability p_{t(u),t(v)}. The authors adopt a Bayesian treatment: each p_{ij} receives a Beta(α,β) prior (often the uniform prior α=β=1) and is analytically integrated out, yielding a marginal likelihood P(G|t) that automatically penalizes over‑parameterization. This formulation allows the model to represent arbitrary mixtures of assortative (p_{ii}>p_{ij}), disassortative (p_{ii}<p_{ij}), and directed relationships without any a‑priori structural assumptions.
Active learning is driven by the mutual information (MI) between the label of a candidate node v and the joint labels of all other nodes, under the Gibbs distribution P(t|G)∝P(G|t). MI(v)=I(t(v);t(V{v})) can be expressed as the difference between the marginal entropy H(t(v)) and the conditional entropy H(t(v)|t(V{v})). Intuitively, a node with high MI is both uncertain (large H(t(v))) and strongly correlated with the rest of the network (small H(t(v)|·)). The algorithm therefore queries the node with the largest estimated MI at each step.
Since the exact Gibbs distribution is intractable, the authors approximate it via Gibbs sampling. They employ a single‑site heat‑bath Markov chain: at each iteration a non‑queried node is selected uniformly at random, its label is resampled according to the conditional distribution proportional to P(G|t) with all other labels fixed, and the process repeats. After a burn‑in period, samples are collected to estimate the marginal label probabilities for each node and the conditional entropies needed for MI. The authors acknowledge that mixing times can be exponential for pathological graphs, but empirical convergence diagnostics (e.g., stability of marginals when the number of updates is doubled) indicate rapid mixing on the real‑world networks examined.
A secondary selection criterion, “average agreement,” is also introduced. It measures the expected proportion of nodes on which two independent Gibbs samples agree, conditioned on agreement at the candidate node. This metric captures the same intuition as MI—favoring nodes whose labels are highly predictive of the rest of the labeling—while being computationally simpler in some settings.
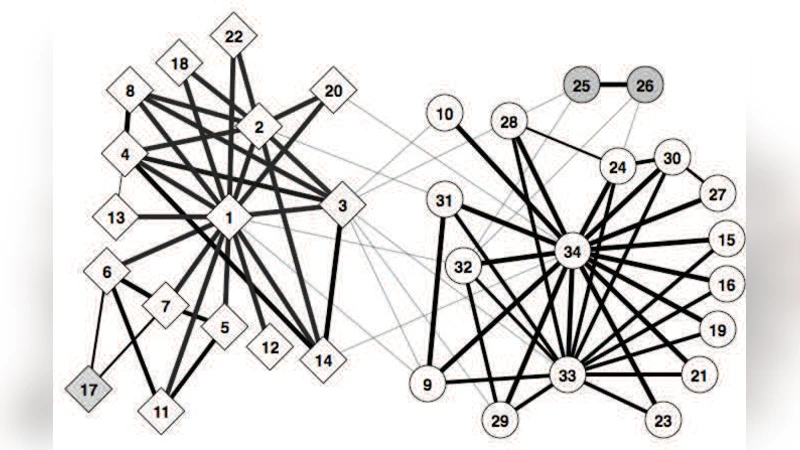
The methodology is evaluated on three heterogeneous datasets: (1) the Zachary karate club social network, where nodes belong to one of two factions; (2) a word‑adjacency network built from Charles Dickens’s “A Tale of Two Cities,” with parts‑of‑speech as class labels; and (3) an Antarctic marine food web, where species are labeled by habitat or trophic level and edges are directed predator‑prey links. For each dataset the algorithm begins with no labeled nodes, iteratively queries nodes according to MI (or average agreement), and predicts the labels of the remaining nodes using the posterior Gibbs distribution. Performance is measured as classification accuracy as a function of the number of queried nodes.
Results show that with only 5–10 queried nodes, the proposed active‑learning approach achieves accuracies above 80–85 % across all three networks, substantially outperforming baseline heuristics such as selecting nodes by degree, betweenness centrality, or random choice. The advantage is especially pronounced in the food‑web case, where the network exhibits strong disassortative and directed structure that defeats traditional community‑detection‑based methods. Moreover, the sequence of queried nodes reveals an emergent strategy: the algorithm first targets central nodes within each functional group, then moves to boundary nodes that bridge groups, thereby efficiently uncovering both intra‑group cohesion and inter‑group relationships without any explicit guidance.
The paper’s contributions are threefold. First, it demonstrates that a Bayesian SBM can serve as a flexible prior for a wide variety of network structures, eliminating the need to assume assortativity. Second, it shows that mutual information is an effective active‑learning acquisition function for graph‑based classification, because it balances uncertainty and correlation. Third, it validates the approach on real‑world data, confirming that a modest labeling budget suffices for high‑quality inference even in directed, disassortative, or mixed‑type networks.
Limitations include the lack of theoretical mixing‑time guarantees for the Gibbs sampler and the requirement to pre‑specify the number of classes k (though model‑selection criteria such as MDL or AIC could be incorporated). Extending the framework to continuous attributes, multilabel settings, or hierarchical class structures represents promising future work.
In summary, the authors present a principled, information‑theoretic active‑learning algorithm grounded in stochastic block modeling that efficiently discovers hidden node classes across diverse network topologies, outperforming simple heuristic baselines and offering a general tool for semi‑supervised network analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment