An Empirical Study and Analysis of the Dynamic Load Balancing Techniques Used in Parallel Computing Systems
A parallel computer system is a collection of processing elements that communicate and cooperate to solve large computational problems efficiently. To achieve this, at first the large computational problem is partitioned into several tasks with different work-loads and then are assigned to the different processing elements for computation. Distribution of the work load is known as Load Balancing. An appropriate distribution of work-loads across the various processing elements is very important as disproportional workloads can eliminate the performance benefit of parallelizing the job. Hence, load balancing on parallel systems is a critical and challenging activity. Load balancing algorithms can be broadly categorized as static or dynamic. Static load balancing algorithms distribute the tasks to processing elements at compile time, while dynamic algorithms bind tasks to processing elements at run time. This paper explains only the different dynamic load balancing techniques in brief used in parallel systems and concluding with the comparative performance analysis result of these algorithms.
💡 Research Summary
**
The paper provides a broad overview of dynamic load‑balancing techniques used in parallel computing systems, focusing exclusively on the dynamic (run‑time) category while briefly mentioning static approaches for context. It begins by emphasizing the importance of load balancing: in a parallel system, the overall performance, speed‑up, and resource utilization depend heavily on how computational tasks are partitioned and assigned to processing elements. Static schemes allocate tasks at compile time, which works only for predictable workloads; dynamic schemes adapt to runtime variations, making them essential for heterogeneous or unpredictable environments.
The authors enumerate five primary goals of load‑balancing algorithms: (1) performance improvement (reducing response time and increasing throughput), (2) job equality (fair treatment of all tasks), (3) fault tolerance (maintaining service despite node failures), (4) modifiability (adapting to changes in system size or configuration), and (5) system stability (preventing performance degradation under sudden load spikes). These goals guide the design of policies that govern load‑balancing behavior.
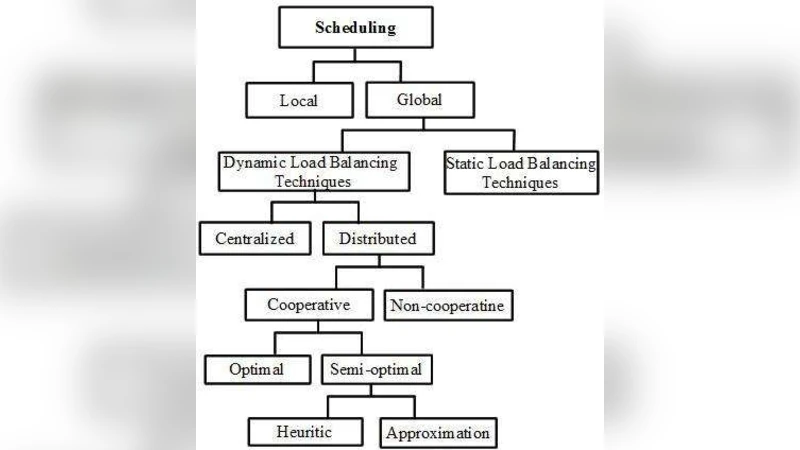
A taxonomy of policies is introduced, comprising six elements: information policy (what load data to collect, when, and from where), triggering policy (when to start a balancing operation), resource‑type policy (classifying nodes as servers or receivers), location policy (selecting partners based on resource type), selection policy (choosing tasks to migrate), and the actual load‑balancing operation. The paper argues that the combination of these policies determines whether a scheme is centralized or distributed, cooperative or non‑cooperative, and whether it aims for optimal, semi‑optimal, heuristic, or approximation solutions.
The core of the analysis classifies dynamic load‑balancing techniques into five groups:
-
Centralized Dynamic Load Balancing – A master node gathers load information from slaves either on‑demand, periodically, or upon state changes, and makes all migration decisions. This approach minimizes unnecessary traffic because information is not broadcast arbitrarily, but it suffers from a single‑point‑of‑failure and limited scalability as the master becomes a bottleneck.
-
Distributed Non‑Cooperative Dynamic Load Balancing – Each workstation independently monitors its own load and exchanges information with others only when a local imbalance is detected. This yields better scalability than the centralized scheme, yet the need to disseminate load data across many nodes can increase network traffic and overall overhead.
-
Distributed Cooperative Optimal Dynamic Load Balancing – All nodes collaborate to achieve a globally optimal distribution of tasks. Information exchange remains demand‑driven, and the average overhead is moderate. However, computing a true global optimum is computationally intensive, which may hinder real‑time applicability on large systems.
-
Distributed Cooperative Semi‑Optimal Heuristic Dynamic Load Balancing – Instead of exact optimality, heuristic methods are employed to quickly approximate a good load distribution. The responsibility for decision‑making is shared among all nodes, the information strategy stays demand‑driven, and the overhead remains moderate, offering a practical trade‑off between solution quality and responsiveness.
-
Distributed Cooperative Semi‑Optimal Approximation Dynamic Load Balancing – This variant exchanges a larger volume of profiling information to achieve finer‑grained approximations. While it can handle highly dynamic workloads more accurately, the increased traffic can become a limiting factor, especially in bandwidth‑constrained environments.
Table 1 in the paper summarizes these categories by indicating the controlling entity (master vs. all workstations), the information strategy (periodic, demand‑driven, or state‑change driven), scalability (limited vs. moderate), and profile‑information overhead (none, limited, average, or many).
The authors discuss performance evaluation metrics such as resource workload measurement, criteria for defining workload, mitigation of dynamic resource effects, and handling heterogeneity to obtain an instantaneous average workload. However, the paper does not present any experimental or simulation results; the comparative analysis remains qualitative. The authors acknowledge this limitation and suggest that future work should involve empirical testing, refinement of triggering policies, and exploration of optimal moments to request load information from workstations.
In conclusion, the paper asserts that while centralized dynamic schemes offer lower communication overhead, they are unsuitable for systems requiring high scalability. Conversely, non‑cooperative distributed schemes provide better scalability at the cost of increased overhead. Cooperative schemes strike a balance, with semi‑optimal heuristic approaches delivering moderate overhead and scalability, and approximation‑based methods offering higher accuracy at the expense of network traffic. The authors propose extending their research to optimize these trade‑offs and to develop adaptive policies that decide when and how much load information to exchange, thereby improving overall system performance in real‑world heterogeneous parallel environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment