Online Learning for Combinatorial Network Optimization with Restless Markovian Rewards
Combinatorial network optimization algorithms that compute optimal structures taking into account edge weights form the foundation for many network protocols. Examples include shortest path routing, minimal spanning tree computation, maximum weighted matching on bipartite graphs, etc. We present CLRMR, the first online learning algorithm that efficiently solves the stochastic version of these problems where the underlying edge weights vary as independent Markov chains with unknown dynamics. The performance of an online learning algorithm is characterized in terms of regret, defined as the cumulative difference in rewards between a suitably-defined genie, and that obtained by the given algorithm. We prove that, compared to a genie that knows the Markov transition matrices and uses the single-best structure at all times, CLRMR yields regret that is polynomial in the number of edges and nearly-logarithmic in time.
💡 Research Summary
The paper tackles a fundamental challenge in modern networking: many routing, scheduling, and resource‑allocation tasks can be expressed as combinatorial optimization problems on a graph, yet the edge weights (e.g., link quality, delay, throughput) are often stochastic and evolve over time. The authors model each edge’s weight as a finite‑state, aperiodic, irreducible Markov chain whose transition matrix is unknown to the decision maker. This “restless” setting—where the state of every edge changes at every time slot regardless of whether the edge is selected—makes the problem substantially harder than the classic i.i.d. or “rested” Markov bandit formulations.
Problem formulation
Given a graph (G=(V,E)) with (N=|E|) edges, each edge (i) follows a Markov chain ({X_i(t)}) on state space (S_i) with unknown transition matrix (P_i). In state (x\in S_i) the edge yields an instantaneous reward (r_i^x) (e.g., packet reception probability). At each discrete time slot a decision maker selects an action (or “arm”) (a) from a finite feasible set (\mathcal{F}). An arm is a vector of non‑negative coefficients ((a_i){i=1}^N) that encodes a combinatorial structure (e.g., a path, a spanning tree, a matching). The instantaneous reward of arm (a) is (\sum{i\in A_a} a_i r_i^{X_i(t)}) where (A_a={i: a_i>0}). The goal is to minimize single‑action regret, i.e., the cumulative difference between the reward of the best static arm (chosen by a genie that knows all (P_i) but is forced to stay with one arm forever) and the reward accumulated by the learning algorithm.
Why existing methods fail
If one treats each feasible structure as an independent arm, the number of arms grows exponentially with (N). Classical restless bandit algorithms such as RCA (Tekin & Liu, 2012) or R‑UCB (Liu et al., 2016) would need to store statistics for each arm, leading to infeasible memory and computation. Moreover, those algorithms assume independence among arms, which is violated here because different arms share many edges.
CLRMR algorithm – key ideas
- Compressed statistics – Instead of maintaining a separate estimate for each arm, CLRMR keeps two scalar statistics per edge: (i) the number of observations (m_i^2) collected during a special “regenerative” sub‑interval, and (ii) the empirical mean (\bar{z}_i^2) of the observed rewards in that interval. This yields O(N) storage regardless of the size of (\mathcal{F}).
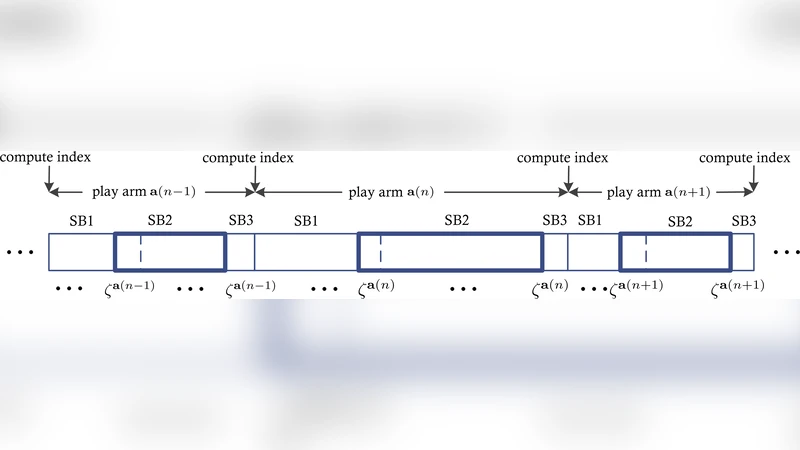
- Regenerative cycles – For each edge (i) a distinguished state (\zeta_i) is pre‑selected. Whenever the chain of edge (i) visits (\zeta_i), a new regenerative cycle begins. A block consists of three sub‑blocks: SB1 (play until the first (\zeta) is seen), SB2 (the interval from the first to the second visit of the joint state ((\zeta_i)_{i\in A_a})), and SB3 (a single slot that ends the block). Only observations gathered in SB2 are used to update (\bar{z}_i^2) and (m_i^2). Because the Markov chain is aperiodic and irreducible, the sequence of observations in SB2 is i.i.d. with respect to the stationary distribution, which enables unbiased estimation despite the restless dynamics.
- UCB‑style arm selection – At the beginning of each block the algorithm computes for every feasible arm a confidence‑bound index:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment