On Clustering on Graphs with Multiple Edge Types
We study clustering on graphs with multiple edge types. Our main motivation is that similarities between objects can be measured in many different metrics. For instance similarity between two papers can be based on common authors, where they are published, keyword similarity, citations, etc. As such, graphs with multiple edges is a more accurate model to describe similarities between objects. Each edge/metric provides only partial information about the data; recovering full information requires aggregation of all the similarity metrics. Clustering becomes much more challenging in this context, since in addition to the difficulties of the traditional clustering problem, we have to deal with a space of clusterings. We generalize the concept of clustering in single-edge graphs to multi-edged graphs and investigate problems such as: Can we find a clustering that remains good, even if we change the relative weights of metrics? How can we describe the space of clusterings efficiently? Can we find unexpected clusterings (a good clustering that is distant from all given clusterings)? If given the ground-truth clustering, can we recover how the weights for edge types were aggregated? %In this paper, we discuss these problems and the underlying algorithmic challenges and propose some solutions. We also present two case studies: one based on papers on Arxiv and one based on CIA World Factbook.
💡 Research Summary
This paper tackles the problem of community detection in graphs where each pair of vertices may be related by several distinct similarity measures, i.e., graphs with multiple edge types. The authors argue that collapsing these diverse relationships into a single scalar edge weight inevitably discards valuable information, and they propose a systematic framework that works directly with the multi‑weighted representation.
A multi‑weighted graph is defined as G = (V,E) where each edge e_i carries a k‑dimensional weight vector ~w_i = (w_i^1,…,w_i^k), each component corresponding to a different similarity metric (e.g., co‑authorship, citation, keyword overlap for scientific papers). To apply existing single‑edge clustering algorithms, the authors introduce a linear aggregation function ω_i = ∑_{j=1}^k α_j w_i^j, where the coefficient vector α ∈ ℝ^k encodes the relative importance of each metric. The central methodological question is how to choose α when a ground‑truth clustering C* is available.
Two complementary strategies are explored. The first treats the problem as an inverse problem: start with a random α, run a standard clustering algorithm (Graclus, FastCommunity) on the aggregated graph, and measure the distance between the resulting clustering C(α) and the ground truth using the Variation of Information (VI) metric. An optimization loop adjusts α to minimize VI. This approach is straightforward but heavily dependent on the quality of the forward clustering algorithm.
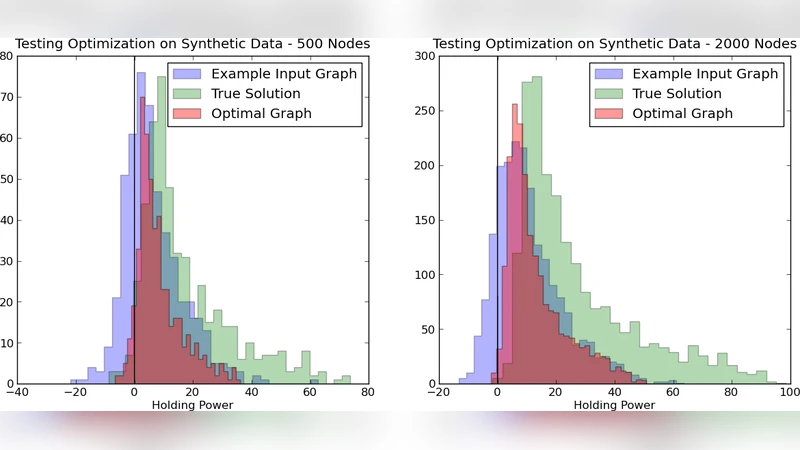
The second strategy sidesteps the forward algorithm altogether by defining a quality function that directly rewards the ground‑truth clustering. For each vertex v and each candidate cluster C_k, the “pull” P_α(v,C_k) is defined as the sum of aggregated edge weights from v to vertices in C_k. The “holding power” H_α(v) is the difference between the pull toward v’s assigned cluster in C* and the strongest competing pull. Positive holding power indicates that v is more strongly attached to its correct cluster than to any other. To obtain a smooth objective amenable to gradient‑free optimization, the step‑like indicator H_α(v)>0 is replaced by arctan(H_α(v)), which emphasizes vertices near the decision boundary while diminishing the influence of vertices that are already well‑or poorly placed. The global objective ∑_v arctan(H_α(v)) is maximized, encouraging α to make as many vertices as possible correctly “held.”
In addition to vertex‑level justification, the authors require the overall clustering to be of high quality. They adopt the modularity score, extended to weighted graphs, as a global quality metric. Because a purely linear objective (e.g., minimizing total cut weight) would trivially assign all weight to the most discriminative metric, the authors combine the arctan‑based local term with modularity, yielding a non‑linear, multi‑objective optimization problem. Since analytic gradients are unavailable, they employ HOPSPACK, a parallel derivative‑free optimizer developed at Sandia National Laboratories, to solve for α.
Beyond weight estimation, the paper introduces the concept of “meta‑clustering.” Each choice of α generates a distinct clustering; the set of all such clusterings can be viewed as points in a high‑dimensional space where distances are measured by VI. By clustering these points again (i.e., clustering the clusterings), the authors reveal higher‑order structure: clusters of similar clusterings and, importantly, regions of the space that are far from any previously observed clustering. This meta‑analysis enables the discovery of “unexpected” clusterings—high‑quality partitions that are substantially different from known solutions, potentially uncovering hidden patterns.
The methodology is validated on three real‑world data sets.
- File‑system data – Files are linked by multiple attributes (directory path, access time, size, etc.). The learned α successfully reconstructs project‑level groupings, outperforming any single attribute.
- ArXiv papers – Four similarity metrics (co‑authorship, citation, keyword overlap, venue) are combined. Using known subject categories as ground truth, the optimization recovers a balanced α that respects both topical and collaborative structure. Meta‑clustering reveals cross‑disciplinary clusters not captured by any single metric.
- CIA World Factbook – Countries are connected via geographic, economic, political, and cultural attributes. The framework uncovers clusters that align with geopolitical blocs while also highlighting alternative groupings based on economic similarity, illustrating the flexibility of the approach.
Across all experiments, the proposed pipeline (weight inference, local holding‑power optimization, modularity regularization, meta‑clustering) consistently yields more informative and robust community structures than naïve single‑metric aggregation.
In conclusion, the paper provides a comprehensive toolkit for clustering multi‑edge graphs: (i) a principled way to learn metric weights from ground‑truth data, (ii) a novel vertex‑level “holding power” concept that bridges local and global quality, (iii) a derivative‑free optimization framework suitable for large, non‑convex problems, and (iv) a meta‑clustering perspective that maps the landscape of possible partitions. The authors suggest future work on non‑linear aggregation functions (e.g., neural networks), online adaptation for streaming graphs, and interactive visual analytics for navigating the meta‑clustering space.
Comments & Academic Discussion
Loading comments...
Leave a Comment