HelloWorld! An Instructive Case for the Transformation Tool Contest
This case comprises several primitive tasks that can be solved straight away with most transformation tools. The aim is to cover the most important kinds of primitive operations on models, i.e. create, read, update and delete (CRUD). To this end, tasks such as a constant transformation, a model-to-text transformation, a very basic migration transformation or diverse simple queries or in-place operations on graphs have to be solved. The motivation for this case is that the results expectedly will be very instructive for beginners. Also, it is really hard to compare transformation languages along complex cases, because the complexity of the respective case might hide the basic language concepts and constructs.
💡 Research Summary
The paper presents a deliberately simple yet comprehensive benchmark case – “HelloWorld!” – designed to exercise the fundamental CRUD (Create, Read, Update, Delete) capabilities of model transformation tools. Its primary purpose is pedagogical: to give beginners a clear, low‑complexity entry point for learning the core constructs of any transformation language, while simultaneously providing a common baseline for comparing different tools in the Transformation Tool Contest.
The case is divided into several independent tasks, each targeting a distinct primitive operation.
-
Constant Transformation – The tool must generate a fixed output model regardless of the input. This tests basic object creation, memory allocation, and the ability to apply a static template without any data‑driven logic.
-
Model‑to‑Text Transformation – Here the input model is rendered as human‑readable text (e.g., a report or source code fragment). The task requires support for template engines, string concatenation, loops, and conditional sections, thereby exposing the language’s facilities for textual generation and formatting.
-
Basic Migration Transformation – The input model conforms to an older metamodel (Version 1) and must be migrated to a newer version (Version 2). Typical operations include attribute renaming (e.g.,
age→birthYear), type conversion, and structural reshaping of relationships (e.g., re‑linkingEmployeetoDepartment). This part evaluates rule‑based mapping, conditional logic, and multi‑step pipeline composition. -
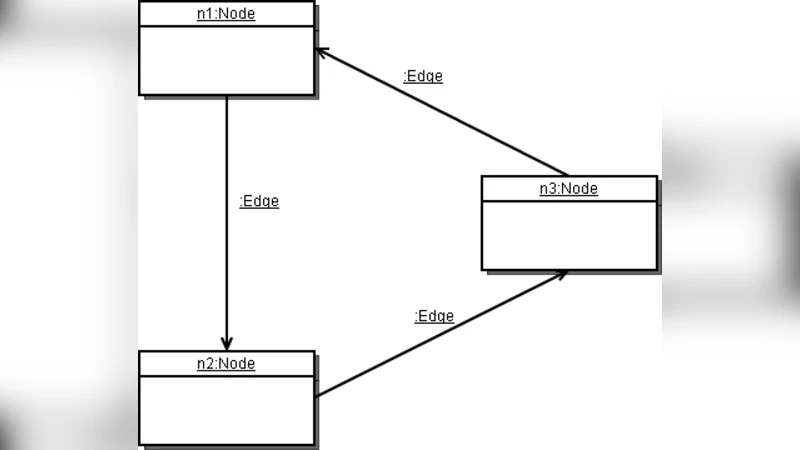
Queries and In‑Place Graph Manipulations – The most involved segment combines reading, updating, and deleting within a single graph. Sample queries locate nodes that satisfy a predicate (e.g., customers with a credit score below 700), then set a flag, add new edges, or remove existing ones. The task forces the tool to expose graph traversal APIs, filtering mechanisms, and deterministic ordering of in‑place modifications, highlighting the distinction between “in‑place” versus “out‑of‑place” transformation modes.
From an educational standpoint, the case deliberately isolates each primitive operation, avoiding the “complexity masking” problem that plagues larger benchmark suites. By working through the five tasks, a newcomer experiences the full spectrum of transformation language features: declarative pattern matching, imperative scripting, template‑based output, and direct graph editing. The simplicity also means that the same case can be implemented across a wide variety of tools—ATL, QVT, Epsilon, Xtend, Henshin, etc.—allowing a fair, side‑by‑side comparison of performance, readability, and extensibility.
The authors argue that while the case is minimalistic, it mirrors real‑world patterns that appear in production migrations, reporting pipelines, and model‑driven engineering tasks. Consequently, mastering this benchmark equips practitioners with the mental models needed to tackle more sophisticated scenarios later on. Moreover, the case serves as a reproducible baseline for the Transformation Tool Contest, ensuring that any claimed advantage of a new language or framework can be traced back to concrete, measurable differences in handling these elementary CRUD operations.
In summary, “HelloWorld!” functions both as a teaching tool and as a standardized testbed. It strips away extraneous domain complexity, foregrounds the essential CRUD operations that every transformation language must support, and provides a clear, repeatable yardstick for evaluating and comparing transformation tools in both academic and industrial contexts.
Comments & Academic Discussion
Loading comments...
Leave a Comment