Un metodo estable para la evaluacion de la complejidad algoritmica de cadenas cortas
It is discussed and surveyed a numerical method proposed before, that alternative to the usual compression method, provides an approximation to the algorithmic (Kolmogorov) complexity, particularly useful for short strings for which compression methods simply fail. The method shows to be stable enough and useful to conceive and compare patterns in an algorithmic models. (article in Spanish)
💡 Research Summary
The paper addresses a fundamental limitation of traditional loss‑less compression techniques when applied to short binary strings: the overhead of the decompression routine often exceeds the length of the input, rendering compression‑based estimates of Kolmogorov complexity unreliable. To overcome this, the authors adopt an algorithmic‑probability approach grounded in Solomonoff’s theory and the Coding Theorem, which states that the Kolmogorov complexity K(s) of a string s is approximately equal to the negative binary logarithm of its algorithmic probability P(s).
To obtain empirical estimates of P(s), the authors exhaustively enumerate the output space of three small‑scale universal computational models: (i) tiny Turing machines with a bounded number of states and symbols, (ii) elementary two‑dimensional cellular automata, and (iii) Post tag systems (also known as tag machines). For each model they generate every possible program up to a fixed length, run each program for a bounded number of steps, and record the frequency with which each binary string appears as output. This frequency serves as an empirical approximation of P(s). By applying the Coding Theorem (K(s) ≈ –log₂ P(s)), they derive a numerical estimate of Kolmogorov complexity for every string up to length 12 bits (and many longer examples).
The central contribution is a demonstration of stability across computational models. Correlation analyses show that the rankings of strings by estimated complexity are highly consistent whether the data come from Turing machines, cellular automata, or tag systems. This cross‑model agreement supports the claim that the method captures a model‑independent notion of algorithmic complexity, even for very short strings where the invariance‑theorem constant c would otherwise dominate the measurement.
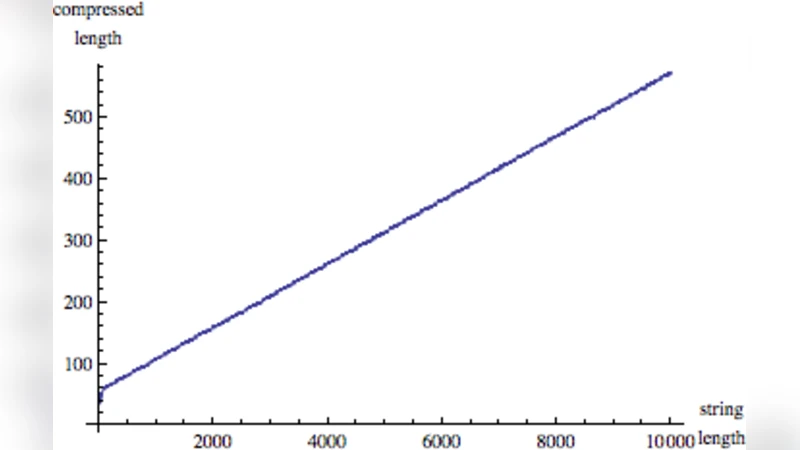
Experimental results reveal several key insights. First, strings with obvious regularities (e.g., “0000000” or repetitive patterns) receive low complexity scores, while strings that appear random (e.g., “10111001”) receive high scores, matching intuitive expectations. Second, traditional compressors such as GZIP or Mathematica’s Compress function only begin to outperform the trivial encoding when strings exceed roughly 30 bits; for shorter strings they produce longer “compressed” representations because the decompression code dominates the size. In contrast, the proposed Coding‑Theorem Method (CTM) yields meaningful, monotonic complexity estimates well below this threshold.
The authors also discuss the relevance of the invariance theorem. While the theorem guarantees that Kolmogorov complexity is invariant up to an additive constant c independent of the string, for short strings c can be comparable to the string length, causing instability. By averaging over several universal machines and minimizing the size of the “compiler” (the translation layer between machines), the effective constant is reduced, leading to more stable estimates. Their empirical data show that differences between models are typically only 1–2 bits.
Beyond short‑string analysis, the paper suggests that the same enumeration strategy can be applied to explore the Busy Beaver problem and other super‑exponential growth phenomena, providing a practical tool for probing the limits of computability.
All frequency data and the resulting complexity estimates are made publicly available as the “CTM database,” enabling other researchers to apply these measures directly in fields such as pattern recognition, anomaly detection, data compression, and the study of complex systems. The authors conclude that their method offers a robust, universal, and computationally feasible way to approximate Kolmogorov complexity for short objects, bridging a gap that has limited the practical use of algorithmic information theory in many applied domains. Future work will expand the enumeration to larger program spaces and explore additional computational models to further refine the estimates.
Comments & Academic Discussion
Loading comments...
Leave a Comment