Lifted Graphical Models: A Survey
This article presents a survey of work on lifted graphical models. We review a general form for a lifted graphical model, a par-factor graph, and show how a number of existing statistical relational representations map to this formalism. We discuss inference algorithms, including lifted inference algorithms, that efficiently compute the answers to probabilistic queries. We also review work in learning lifted graphical models from data. It is our belief that the need for statistical relational models (whether it goes by that name or another) will grow in the coming decades, as we are inundated with data which is a mix of structured and unstructured, with entities and relations extracted in a noisy manner from text, and with the need to reason effectively with this data. We hope that this synthesis of ideas from many different research groups will provide an accessible starting point for new researchers in this expanding field.
💡 Research Summary
The paper provides a comprehensive survey of lifted graphical models, a family of statistical relational learning (SRL) approaches that combine relational languages with probabilistic graphical models. It begins by motivating the need for SRL: many real‑world domains—social networks, molecular biology, web data, natural‑language processing—contain multiple entity types and rich inter‑entity relations, violating the IID assumption of traditional machine learning. Consequently, models must (a) express dependencies among heterogeneous entities and relations, and (b) support probabilistic reasoning under uncertainty.
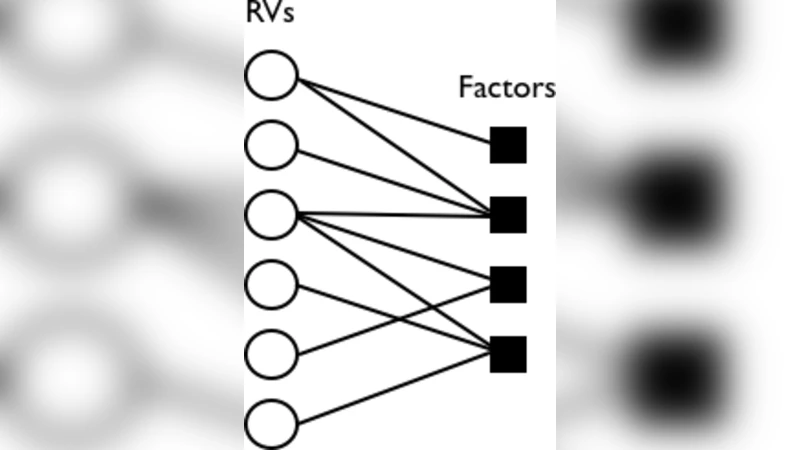
After establishing terminology for both logical formalisms (first‑order logic, object‑oriented representations, SQL) and probabilistic graphical models (Bayesian networks, Markov networks, factor graphs), the authors introduce the unifying framework of parameterized factor graphs (par‑factor graphs). A par‑factor is a triple (A, φ, C) where A is a set of parameterized random variables (par‑RVs), φ is a strictly positive potential function, and C encodes constraints on how variables may be instantiated. A collection of such par‑factors defines a lifted factor graph; grounding all par‑factors yields an ordinary factor graph, but the lifted representation shares structure and parameters across many ground factors, enabling compactness and better generalization.
The survey then maps a variety of existing SRL formalisms onto this generic template. Markov Logic Networks become weighted first‑order formulas (φ) over par‑RVs (A) with domain constraints (C). Probabilistic Relational Models correspond to object‑oriented schemas where attributes and relationships form A, conditional probability tables become φ, and type constraints become C. Template Bayesian and Markov networks, relational dependency networks, and other template‑based models are similarly expressed, illustrating that seemingly disparate systems are merely different instantiations of the same lifted factor‑graph principle.
In the inference section, the authors review lifted algorithms that exploit symmetry to avoid redundant computation. Lifted Belief Propagation groups indistinguishable variables and sends a single message per group; Lifted Variable Elimination performs elimination on equivalence classes rather than individual variables; and color‑refinement or other graph‑automorphism techniques are used to discover these symmetries efficiently. Because the algorithms operate at the par‑factor level, they are applicable to both directed and undirected SRL models and scale to domains with thousands or millions of ground atoms.
Learning is divided into parameter learning and structure learning. For fully observed data, maximum‑likelihood or Bayesian estimation of shared parameters is straightforward; for partially observed data, EM, variational inference, or pseudo‑likelihood methods are employed, always respecting the lifted sharing of parameters. Structure learning concerns the discovery of which par‑factors (i.e., which relational patterns) should be included. The survey discusses score‑based approaches (BIC, AIC, MDL) and search‑based methods (greedy addition/removal, MCMC, relational path ranking), emphasizing techniques that preserve lifting during search to keep the combinatorial explosion in check.
The paper concludes by highlighting emerging trends: the growing prevalence of noisy, mixed structured‑unstructured data extracted from text, the need to integrate deep neural representations with lifted relational models, advances in automatic symmetry detection, and the push toward distributed, real‑time lifted inference and learning. By presenting a unified view of lifted graphical models, the authors aim to provide a clear entry point for newcomers and a reference framework for seasoned researchers exploring the next generation of statistical relational AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment