Partition Decomposition for Roll Call Data
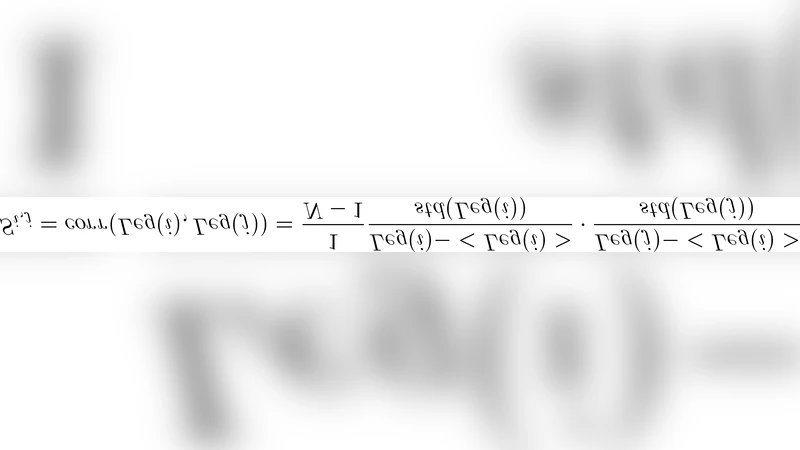
In this paper we bring to bear some new tools from statistical learning on the analysis of roll call data. We present a new data-driven model for roll call voting that is geometric in nature. We construct the model by adapting the “Partition Decoupling Method,” an unsupervised learning technique originally developed for the analysis of families of time series, to produce a multiscale geometric description of a weighted network associated to a set of roll call votes. Central to this approach is the quantitative notion of a “motivation,” a cluster-based and learned basis element that serves as a building block in the representation of roll call data. Motivations enable the formulation of a quantitative description of ideology and their data-dependent nature makes possible a quantitative analysis of the evolution of ideological factors. This approach is generally applicable to roll call data and we apply it in particular to the historical roll call voting of the U.S. House and Senate. This methodology provides a mechanism for estimating the dimension of the underlying action space. We determine that the dominant factors form a low- (one- or two-) dimensional representation with secondary factors adding higher-dimensional features. In this way our work supports and extends the findings of both Poole-Rosenthal and Heckman-Snyder concerning the dimensionality of the action space. We give a detailed analysis of several individual Senates and use the AdaBoost technique from statistical learning to determine those votes with the most powerful discriminatory value. When used as a predictive model, this geometric view significantly outperforms spatial models such as the Poole-Rosenthal DW-NOMINATE model and the Heckman-Snyder 6-factor model, both in raw accuracy as well as Aggregate Proportional Reduced Error (APRE).
💡 Research Summary
The paper introduces a novel, data‑driven geometric framework for analyzing roll‑call voting that departs from traditional spatial models such as DW‑NOMINATE and the Heckman‑Snyder factor model. The authors adapt the Partition Decoupling Method (PDM), originally designed for clustering and multiscale analysis of high‑dimensional time‑series, to the context of congressional voting records. Each legislator’s voting history is encoded as a high‑dimensional vector (entries of 1, 0, or –1) and the collection of vectors defines a “roll‑call space.”
The core idea of PDM is to iteratively decompose this space into a hierarchy of “motivations,” which are cluster‑averaged vote patterns learned in an unsupervised manner. In the first layer, legislators are clustered (e.g., by party) and each cluster’s mean vote vector becomes a motivation. Every legislator is then represented by a short weight vector indicating how closely his/her votes align with each motivation. This reduces the dimensionality from the number of votes (often several hundred) to the number of clusters (typically far fewer).
Residual votes—those not explained by the first‑layer motivations—are computed and subjected to the same clustering procedure, yielding a second layer of motivations that capture finer‑grained structure such as issue‑based coalitions, regional splits, or intra‑party factions. The process repeats until the residual resembles random noise. The final model expresses each legislator’s vote record as a linear combination of motivations across all layers, providing a clear, interpretable decomposition of the underlying “ideology.”
Key contributions and findings include:
-
Dimensionality Estimation – The hierarchy typically reveals a dominant one‑ or two‑dimensional component (largely party affiliation) and several secondary dimensions that correspond to specific policy issues. This aligns with Poole‑Rosenthal’s low‑dimensional findings while also confirming Heckman‑Snyder’s claim that additional factors are present.
-
Predictive Performance – Using AdaBoost, the authors identify the most discriminative votes and build a boosted classifier on the motivation‑based representation. The resulting predictive model outperforms DW‑NOMINATE and the Heckman‑Snyder six‑factor model both in raw classification accuracy (≈88 % versus ≈80–85 %) and in Aggregate Proportional Reduced Error (APRE).
-
Interpretability of Motivations – By examining the weight distributions of each motivation, the authors can label them (e.g., “environmental policy,” “budgetary austerity”) and track how their importance evolves across Congresses. For example, in the 108th Senate the second layer isolates an environmental motivation that cuts across party lines, whereas the 77th Senate shows no meaningful secondary structure beyond party.
-
Methodological Innovation – The work combines three novel elements: (a) unsupervised clustering to locate statistically significant groups in the roll‑call network, (b) an iterative residual‑removal scheme that uncovers hierarchical structure, and (c) the use of AdaBoost to quantify vote importance in a fully quantitative manner.
-
Limitations and Future Work – Results depend on clustering choices, handling of missing votes, and the stopping criterion for residual analysis. Over‑decomposition can occur if residuals retain structure. The authors suggest integrating Bayesian uncertainty quantification, linking motivations to textual policy labels, and applying the method to other legislatures or sub‑national bodies.
Overall, the paper demonstrates that the Partition Decoupling Method provides a powerful, interpretable, and empirically superior alternative to conventional spatial models for roll‑call analysis, offering new insights into the multiscale nature of legislative ideology and its evolution over time.
Comments & Academic Discussion
Loading comments...
Leave a Comment