Corporate competition: A self-organized network
A substantial number of studies have extended the work on universal properties in physical systems to complex networks in social, biological, and technological systems. In this paper, we present a complex networks perspective on interfirm organizational networks by mapping, analyzing and modeling the spatial structure of a large interfirm competition network across a variety of sectors and industries within the United States. We propose two micro-dynamic models that are able to reproduce empirically observed characteristics of competition networks as a natural outcome of a minimal set of general mechanisms governing the formation of competition networks. Both models, which utilize different approaches yet apply common principles to network formation give comparable results. There is an asymmetry between companies that are considered competitors, and companies that consider others as their competitors. All companies only consider a small number of other companies as competitors; however, there are a few companies that are considered as competitors by many others. Geographically, the density of corporate headquarters strongly correlates with local population density, and the probability two firms are competitors declines with geographic distance. We construct these properties by growing a corporate network with competitive links using random incorporations modulated by population density and geographic distance. Our new analysis, methodology and empirical results are relevant to various phenomena of social and market behavior, and have implications to research fields such as economic geography, economic sociology, and regional economic development.
💡 Research Summary
The paper applies complex‑network theory to the spatial and relational structure of inter‑firm competition in the United States. Using the Hoover business information database, the authors constructed a directed competition network comprising 10,753 firms (nodes) and 94,953 competitive ties (edges) located exclusively at corporate headquarters in the contiguous United States. A snowball‑sampling crawl was performed from multiple seed firms to mitigate seed bias, and the resulting network contains a giant strongly‑connected component of 10,234 nodes plus 419 smaller components.
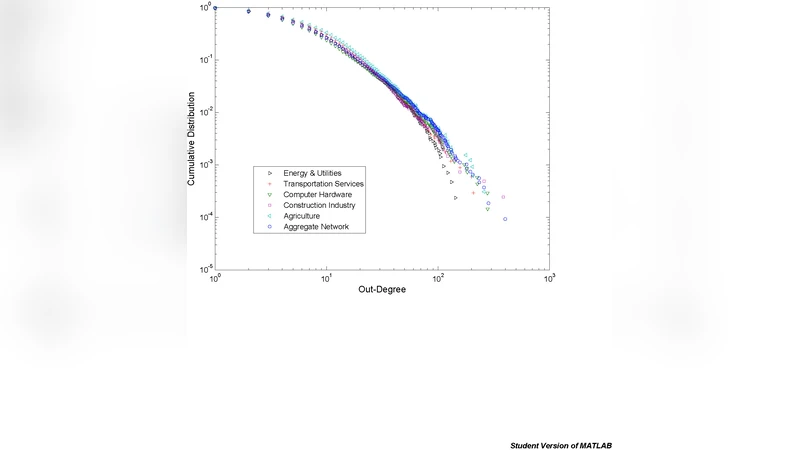
Statistical analysis reveals a pronounced asymmetry between out‑degree (the number of competitors a firm perceives) and in‑degree (the number of firms that list a given firm as a competitor). Both degree distributions follow heavy‑tailed, approximately power‑law forms, yet the average out‑degree is modest (≈9) while a few “hub” firms receive many inbound links, indicating that most firms consider only a limited set of rivals, whereas a small elite is perceived as a rival by many. Correlation between firm size (employees) and neighbor size is weak (Spearman ρ≈0.56), suggesting that size‑based clustering is not dominant.
Geographically, the density of corporate headquarters is strongly proportional to local population density, confirming a gravity‑like relationship between economic activity and demographic concentration. Moreover, the probability that two firms are competitors decays sharply with Euclidean distance; empirical fits support both exponential (P∝e^{‑αd}) and power‑law (P∝d^{‑β}) decay, consistent with findings in transportation, communication, and trade networks. Only about 40 % of competitive links are reciprocal, further emphasizing directional asymmetry.
To reproduce these empirical regularities, the authors propose two micro‑dynamic growth models. Model A places each newly entering firm at a random location on a 2‑D plane, then connects it to existing firms with probability proportional to the product of local population density and a distance‑attenuation factor. Model B adds a preferential‑attachment component: the attachment probability is proportional to the existing firm’s current degree (cumulative advantage) multiplied by the same distance‑decay term. Both models are calibrated using the observed decay parameters and generate networks whose degree distributions, clustering coefficients, and distance‑dependent link probabilities match the real data remarkably well. Model B, in particular, naturally yields a few high‑degree hubs and a majority of low‑degree nodes, mirroring the observed asymmetry.
The study demonstrates that inter‑firm competition networks self‑organize under simple, universal mechanisms—preferential attachment, geographic proximity, and population‑driven node placement—despite the economic context. These findings have several implications: (1) they provide a quantitative foundation for economic geography models that traditionally rely on metaphorical gravity concepts; (2) they suggest that policy interventions targeting a handful of hub firms may have outsized systemic effects due to the directed nature of competition perception; and (3) they open avenues for extending spatial network theory to other socio‑economic systems such as alliances, board interlocks, and supply‑chain relationships. Future work could explore industry‑specific sub‑networks, temporal evolution (e.g., mergers, market entry/exit), and the impact of digital versus physical proximity on competition dynamics.
Comments & Academic Discussion
Loading comments...
Leave a Comment