Proposal for improvement in the transfer and execution of multiple instances of a virtual image
Virtualization technology allows currently any application run any application complex and expensive computational (the scientific applications are a good example) on heterogeneous distributed systems, which make regular use of Grid and Cloud technologies, enabling significant savings in computing time. This model is particularly interesting for the mass execution of scientific simulations and calculations, allowing parallel execution of applications using the same execution environment (unchanged) used by the scientist as usual. However, the use and distribution of large virtual images can be a problem (up to tens of GBytes), which is aggravated when attempting a mass mailing on a large number of distributed computers. This work has as main objective to present an analysis of how implementation and a proposal for the improvement (reduction in size) of the virtual images pretending reduce distribution time in distributed systems. This analysis is done very specific requirements that need an operating system (guest OS) on some aspects of its execution.
💡 Research Summary
The paper addresses a critical bottleneck in large‑scale distributed computing environments—namely, the transfer of heavyweight virtual‑machine (VM) images that can reach tens of gigabytes. While virtualization enables scientists to run complex, compute‑intensive applications on heterogeneous Grid and Cloud infrastructures without modifying the software stack, the sheer size of VM images hampers rapid deployment across thousands of nodes. Existing solutions typically rely on generic compression, which reduces the byte count but still ships the entire filesystem, including many files that are never accessed during boot or application execution.
To overcome this limitation, the authors propose a systematic reduction of VM images by extracting only the files that the guest operating system (OS) actually uses. Their methodology consists of three main steps: (1) monitoring the guest OS during boot using the readahead utility, which records every file accessed by the kernel and init scripts; (2) monitoring the execution of a representative user‑level application (OpenOffice) with preload, which logs libraries, configuration files, and other resources required at runtime; and (3) rebuilding a new, trimmed VM image that contains exclusively the union of the two file sets.
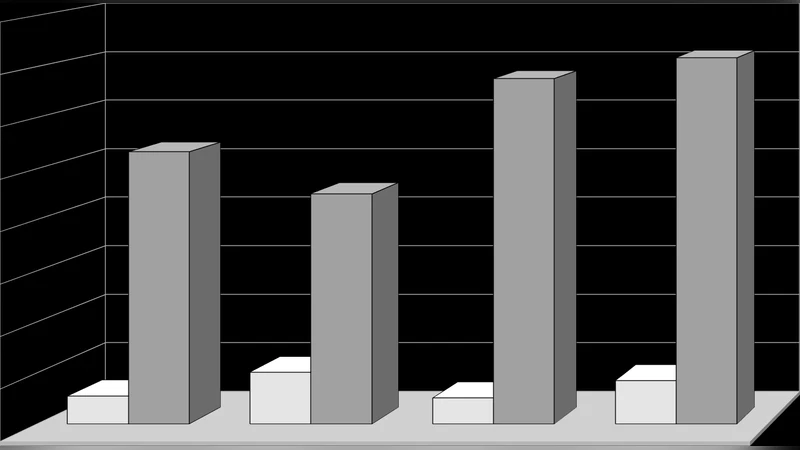
The experimental platform includes four Linux distributions (Debian 5 Lenny, Ubuntu 10.04 Lucid Lynx, Fedora 10, and OpenSUSE) each allocated a 6 GB virtual disk. By comparing the total filesystem size with the size of the files accessed during boot and during the OpenOffice session, the authors find that on average only about 48 % of the allocated space is actually used. The readahead phase typically accesses a few hundred files (≈1.4 % of the filesystem), while the preload phase adds a modest amount of additional files, still keeping the overall usage well below 5 % of the total disk.
Using the collected file lists, the authors script the removal of all non‑essential files and recreate the VM images. The resulting “trimmed” images average 2.9 GB, a reduction of roughly 55 % compared with the original 6 GB images. Network transfer tests demonstrate a proportional decrease in transmission time, and boot time measurements show a ~30 % speed‑up thanks to the pre‑populated readahead cache.
The paper also discusses limitations. The approach assumes a relatively static workload; dynamically loaded modules, runtime updates, or plug‑ins that are not exercised during the monitoring phase would be omitted, potentially causing failures. Moreover, the study is confined to Linux guests and ext3/ext4 filesystems; Windows or other OS families are not evaluated. Future work is suggested to include automated dependency analysis, real‑time monitoring, and comparison with container‑based solutions such as layered Docker images, which already employ a form of file‑level deduplication.
In summary, the authors present a practical, OS‑aware image‑reduction technique that can substantially lower bandwidth consumption and deployment latency in volunteer‑computing, Grid, and Cloud scenarios where massive numbers of identical VM instances must be distributed. By focusing on the actual file‑level footprint of the guest OS and its target applications, the method offers a more efficient alternative to blunt‑force compression, paving the way for faster, more scalable scientific computing infrastructures.
Comments & Academic Discussion
Loading comments...
Leave a Comment