Minimization of Storage Cost in Distributed Storage Systems with Repair Consideration
In a distributed storage system, the storage costs of different storage nodes, in general, can be different. How to store a file in a given set of storage nodes so as to minimize the total storage cost is investigated. By analyzing the min-cut constraints of the information flow graph, the feasible region of the storage capacities of the nodes can be determined. The storage cost minimization can then be reduced to a linear programming problem, which can be readily solved. Moreover, the tradeoff between storage cost and repair-bandwidth is established.
💡 Research Summary
The paper addresses the problem of minimizing total storage cost in a distributed storage system where storage nodes have heterogeneous per‑unit costs. Specifically, the authors consider two classes of nodes: class‑1 nodes (n₁ of them) with cost C₁ per unit of stored data, and class‑2 nodes (n₂ of them) with cost C₂. Each node of class i stores the same amount αᵢ (i = 1, 2), so the overall storage expense is C₁·n₁·α₁ + C₂·n₂·α₂.
The system follows the standard regenerating‑code model: a file of size M is encoded so that any k out of the n = n₁ + n₂ nodes suffice for reconstruction. When a node fails, a newcomer contacts d (≥ k) surviving nodes and downloads β units from each, incurring a repair‑bandwidth of d·β. The authors focus on functional repair, where the newcomer need not store exactly the same data as the failed node, only the overall reconstruction property must be preserved.
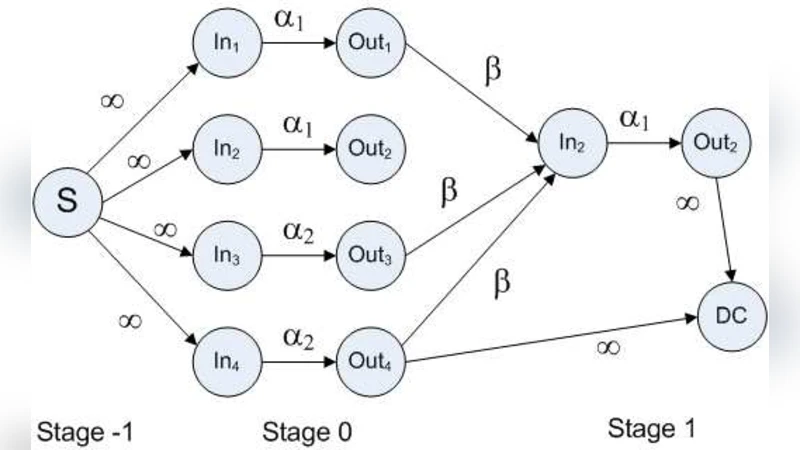
To capture the constraints imposed by reconstruction and repair, the authors build an information‑flow graph (IFG) as introduced by Dimakis et al. The graph contains a source vertex S, “in” and “out” vertices for each storage node, and a data‑collector (DC) vertex that connects to any k “out” vertices. Edges from “in” to “out” have capacities α₁ or α₂ depending on node type; repair edges have capacity β; edges from S to “in” vertices have infinite capacity.
A fundamental result from network coding states that if, for every possible DC, the minimum S‑DC cut capacity is at least M, then there exists a linear network code that enables all DCs to recover the file. By enumerating all possible cuts, the authors derive a universal upper bound on M:
M ≤ ∑_{i=1}^{k} min{α(i), (d − i + 1)β} (1)
where α(i) denotes the storage amount of the i‑th node among the k nodes contacted by a DC; each α(i) is either α₁ or α₂.
Equation (1) must hold for every possible selection of k nodes, which yields 2ᵏ linear inequalities in α₁ and α₂. The authors show that these can be reduced to a compact set of 2(k + 1) constraints. For each integer m (0 ≤ m ≤ k) let θₘ = (k − m)(2d − k − m + 1)β⁄2. Then the feasible region is defined by
M ≤ min{m, n₁}·α₁ + (m − min{m, n₁})·α₂ + θₘ (2)
M ≤ (m − min{m, n₂})·α₁ + min{m, n₂}·α₂ + θₘ (3)
for all m = 0,…,k. The objective is to minimize C₁·n₁·α₁ + C₂·n₂·α₂ subject to (2)–(3). This is a linear program (LP) in two variables.
The authors solve the LP by considering four regimes, depending on whether n₁ and n₂ are at least k:
-
Case A (n₁ ≥ k, n₂ ≥ k): Both constraints simplify to M ≤ m·α₁ + θₘ and M ≤ m·α₂ + θₘ. The feasible region is a square shifted along the line α₁ = α₂. The optimal solution lies at the corner (α₁*, α₂*) = (μ, μ) where μ = max_{1≤m≤k} (M − θₘ)/m. Hence the optimal allocation is symmetric, regardless of the cost disparity.
-
Case B (n₁ ≥ k, n₂ < k): The second set of constraints (3) becomes tighter because only a limited number of class‑2 nodes can appear among the k selected nodes. For each m, the feasible region Rₘ is defined by m·α₁ ≥ M − θₘ and (m − qₘ)·α₁ + qₘ·α₂ ≥ M − θₘ where qₘ = min{m, n₂}. The intersection of all Rₘ yields a polygon whose vertices are at (α₁, α₂) = ((M − θₘ)/m, (M − θₘ)/m). The LP selects the vertex that minimizes C₁·n₁·α₁ + C₂·n₂·α₂, typically pushing more data onto the cheaper class‑1 nodes.
-
Case C (n₁ < k, n₂ ≥ k): Symmetric to Case B, with the roles of α₁ and α₂ interchanged.
-
Case D (n₁ < k, n₂ < k): Neither class has enough nodes to satisfy the k‑reconstruction requirement without additional bandwidth. Feasibility requires β ≥ 2M·k⁄(2d − k + 1). When this holds, the same corner solutions as in Cases B/C apply, but the system must operate with a relatively large β, i.e., higher repair bandwidth, to keep storage costs low.
The analysis reveals a clear trade‑off between storage cost and repair bandwidth. Increasing β enlarges θₘ, which reduces the required α₁ and α₂, thereby lowering the total storage expense. Conversely, limiting β forces larger αᵢ, raising cost but saving bandwidth. This quantitative relationship enables system designers to choose (β, α₁, α₂) that best meet economic and performance constraints.
In summary, the paper extends the regenerating‑code framework to heterogeneous storage‑cost environments, formulates the cost‑minimization problem as a tractable LP via min‑cut analysis of the information‑flow graph, and characterizes the optimal storage allocation across node types. The derived cost‑bandwidth trade‑off provides practical guidance for deploying cost‑effective, repair‑efficient distributed storage systems in real‑world settings such as cloud data centers and edge computing platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment